







java简介
Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承、指针等概念,因此Java语言具有功能强大和简单易用两个特征。Java语言作为静态面向对象编程语言的代表,极好地实现了面向对象理论,允许程序员以优雅的思维方式进行复杂的编程 。 --百度百科
java特点:简单性、面向对象、分布式、健壮性、安全性、平台独立与可移植、多线程、动态性等特点。
JDK、JRE、JVM 是什么?
JDK:java的开发工具包,在jdk的安装目录里面有个jre,里面有lib和bin,在这里我们可以认为bin是jvm,lib是jvm所需要的类库。jvm和lib(类库)合起来就交jre
JRE:运行环境,不是开发环境,没有任何开发工具(如编译器和调试器等)
jvm:虚拟机,一个虚构的计算机

由图可知,JDK是java的核心,包含java的开发工具包,java的虚拟机、java的基本类库、java的运行环境。而JRE是java的运行环境,是java实现跨平台的核心。
类加载过程
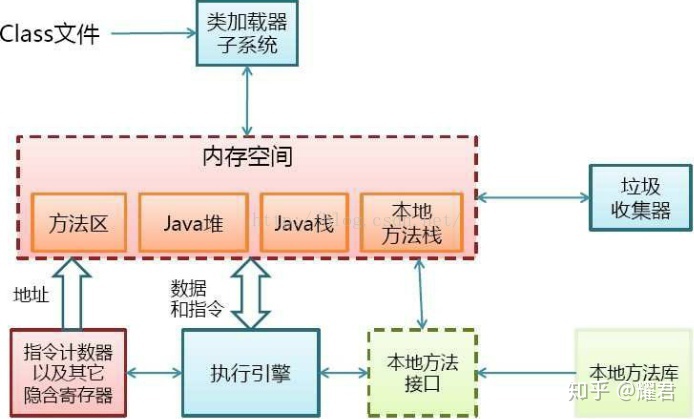
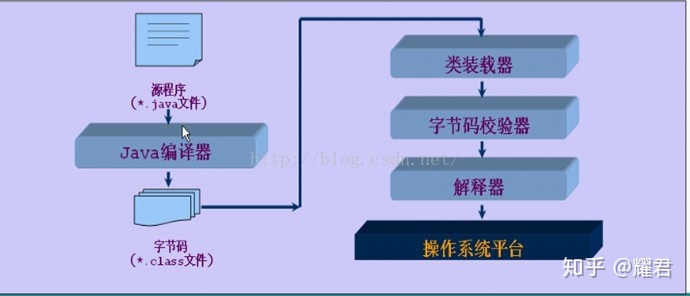
我们编写的java程序以**.java的形式,通过java编译器编译成**.class文件(0101,二进制文件)。 然后由OS之上的java解释器,进行解释执行。这里涉及到类加载过程。
类加载过程步骤:
1.装载
装载过程负责加载class二进制文件,通过类名+包名+ClassLoader实例ID三个元素来找到要加载的类。
2.链接
链接过程主要负责对二进制文件进行验证,初始化装载类中的静态变量以及解析类中调用的接口、类完成校验后,jvm初始化类中的静态变量,并将其值赋为默认值
3.初始化
初始化过程即为执行类中的静态初始化代码、构造器代码以及静态属性的初始化,在四种情况下初始化过程会被触发执行:调用new,反射类中的方法,子类调用初始化,jvm指定初始化类。
JVM运行时数据区
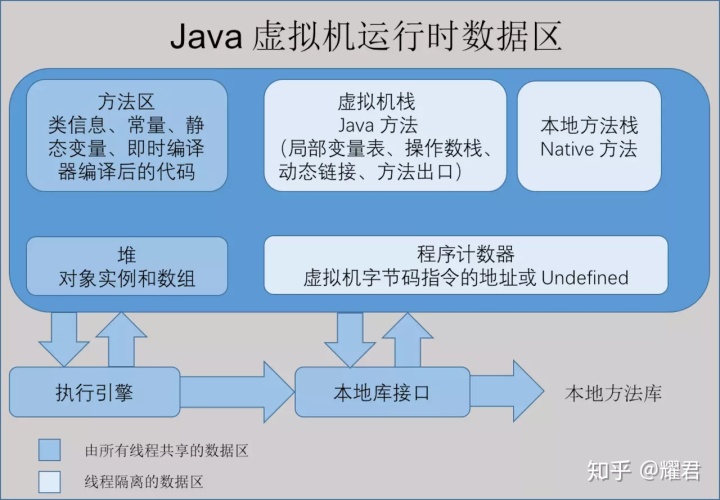
第一块:PC寄存器
PC寄存器是用于存储每个线程下一步将执行的JVM指令,如该方法为native的,则PC寄存器中不存储任何信息。
第二块:JVM栈
JVM栈是线程私有的,每个线程创建的同时都会创建JVM栈,JVM栈中存放的为当前线程中局部基本类型的变量(java中定义的八种基本类型:boolean、char、byte、short、int、long、float、double)、部分的返回结果以及Stack Frame,非基本类型的对象在JVM栈上仅存放一个指向堆上的地址
第三块:堆(Heap)
它是JVM用来存储对象实例以及数组值的区域,可以认为Java中所有通过new创建的对象的内存都在此分配,Heap中的对象的内存需要等待GC进行回收。
第四块:方法区域(Method Area)
(1)在Sun JDK中这块区域对应的为PermanetGeneration,又称为持久代。
(2)方法区域存放了所加载的类的信息(名称、修饰符等)、类中的静态变量、类中定义为final类型的常量、类中的Field信息、类中的方法信息,当开发人员在程序中通过Class对象中的getName、isInterface等方法来获取信息时,这些数据都来源于方法区域,同时方法区域也是全局共享的,在一定的条件下它也会被GC,当方法区域需要使用的内存超过其允许的大小时,会抛出OutOfMemory的错误信息。
第五块:运行时常量池(Runtime Constant Pool)
存放的为类中的固定的常量信息、方法和Field的引用信息等,其空间从方法区域中分配。
第六块:本地方法堆栈(Native Method Stacks)
JVM采用本地方法堆栈来支持native方法的执行,此区域用于存储每个native方法调用的状态。














 1935
1935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









