






自己总结了下java中常见的数据结构和分类
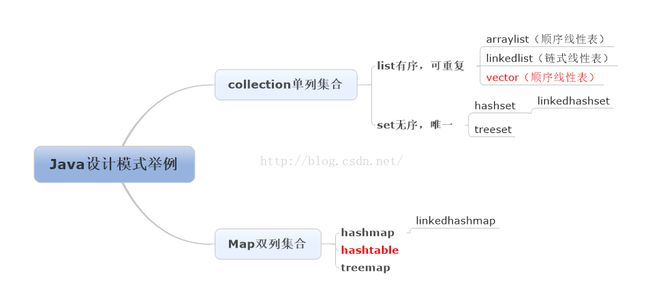
在这里,我总结了list中数据结构对应我们所学的线性表,属于顺序存储还是链式存储,但没有总结set数据结构对应我们所学的哪一种(按理说应该是集合),是因为treeset是基于红黑树的,hashset和linkedhashset基于hash表,不能完全对应到数据结构书上的内容。。。。我认为书上的数据结构是一些基础的数据结构,发展到如今常用的数据结构都是在此基础上延伸或者组合起来的,虽然名称感觉上类似(set与集合,list和线性表,map和貌似没有==),但是实际上早已经不是一类了。
官网的图片如图:
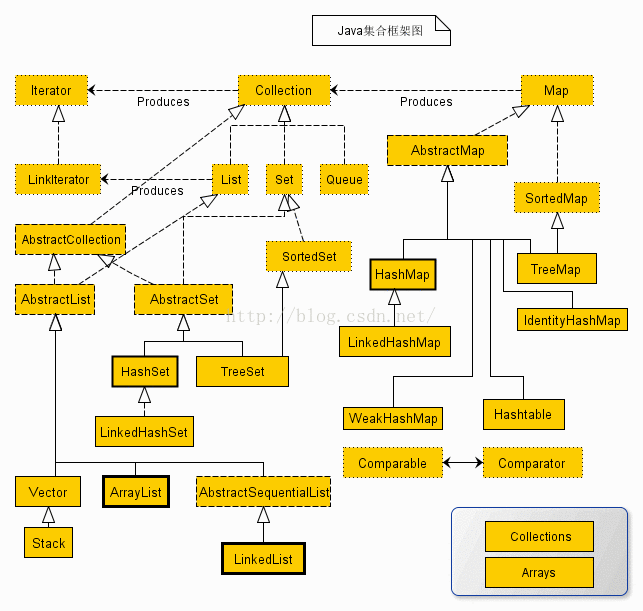
上述类图中,实线边框的是实现类,比如ArrayList,LinkedList,HashMap等,折线边框的是抽象类,比如AbstractCollection,AbstractList,AbstractMap等,而点线边框的是接口,比如Collection,Iterator,List等。
一、arraylist,linkedlist和vector
从图中可以看出,这三者都实现了List接口.所有使用方式也很相似,主要区别在于因为实现方式的不同,所以对不同的操作具有不同的效率。ArrayList是一个可改变大小的数组.当更多的元素加入到ArrayList中时,其大小将会动态地增长.内部的元素可以直接通过get与set方法进行访问,因为ArrayList本质上就是一个数组.LinkedList是一个双链表,在添加和删除元素时具有比ArrayList更好的性能.但在get与set方面弱于ArrayList.当然,这些对比都是指数据量很大或者操作很频繁的情况下的对比,如果数据和运算量很小,那么对比将失去意义.Vector和ArrayList类似,但属于强同步类。如果你的程序本身是线程安全的(thread-safe,没有在多个线程之间共享同一个集合/对象),那么使用ArrayList是更好的选择。Vector和ArrayList在更多元素添加进来时会请求更大的空间。Vector每次请求其大小的双倍空间,而ArrayList每次对size增长50%.而LinkedList还实现了Queue接口,该接口比List提供了更多的方法,包括 offer(),peek(),poll()等.注意: 默认情况下ArrayList的初始容量非常小,所以如果可以预估数据量的话,分配一个较大的初始值属于最佳实践,这样可以减少调整大小的开销。
二、hashset,linkedhashset和treeset
HashSet:哈希表是通过使用称为散列法的机制来存储信息的,元素并没有以某种特定顺序来存放;
LinkedHashSet:以元素插入的顺序来维护集合的链接表,允许以插入的顺序在集合中迭代;
TreeSet:提供一个使用树结构存储Set接口的实现,对象以升序顺序存储,访问和遍历的时间很快。
用例代码:

package com.test;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.TreeSet;
/*** @description 几个set的比较
* HashSet:哈希表是通过使用称为散列法的机制来存储信息的,元素并没有以某种特定顺序来存放;
* LinkedHashSet:以元素插入的顺序来维护集合的链接表,允许以插入的顺序在集合中迭代;
* TreeSet:提供一个使用树结构存储Set接口的实现,对象以升序顺序存储,访问和遍历的时间很快。
*@authorZhou-Jingxian
**/
public class SetDemo {
public static void main(String[] args) {
HashSeths = new HashSet();
hs.add("B");
hs.add("A");
hs.add("D");
hs.add("E");
hs.add("C");
hs.add("F");
System.out.println("HashSet 顺序:\n"+hs);
LinkedHashSetlhs = new LinkedHashSet();
lhs.add("B");
lhs.add("A");
lhs.add("D");
lhs.add("E");
lhs.add("C");
lhs.add("F");
System.out.println("LinkedHashSet 顺序:\n"+lhs);
TreeSetts = new TreeSet();
ts.add("B");
ts.add("A");
ts.add("D");
ts.add("E");
ts.add("C");
ts.add("F");
System.out.println("TreeSet 顺序:\n"+ts);
}
}
输出效果:
HashSet 顺序:
[D, E, F, A, B, C]
LinkedHashSet 顺序:
[B, A, D, E, C, F]
TreeSet 顺序:
[A, B, C, D, E, F]
三、hashmap,linkedhashmap,hashtable和treemap
All three classes implement the Map interface and offer mostly the same functionality. The most important difference is the order in which iteration through the entries will happen:
HashMap makes absolutely no guarantees about the iteration order. It can (and will) even change completely when new elements are added.
TreeMap will iterate according to the "natural ordering" of the keys according to their compareTo() method (or an externally supplied Comparator). Additionally, it implements the SortedMap interface, which contains methods that depend on this sort order.
LinkedHashMap will iterate in the order in which the entries were put into the map
"Hashtable" is the generic name for hash-based maps. In the context of the Java API, Hashtable is an obsolete class from the days of Java 1.1 before the collections framework existed. It should not be used anymore, because its API is cluttered with obsolete methods that duplicate functionality, and its methods are synchronized (which can decrease performance and is generally useless). Use ConcurrrentHashMap instead of Hashtable.














 4526
4526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









