







点击上方 "zhisheng"关注, 星标或置顶一起成长
Flink 从入门到精通 系列文章
本章将介绍两个最佳实践,第一个是如何合理的配置重启策略,笔者通过自己的亲身经历来讲述配置重启策略的重要性,接着介绍了 Flink 中的重启策略和恢复策略的发展实现过程;第二个是如何去管理 Flink 作业的配置。两个实践大家可以参考,不一定要照搬运用在自己的公司,同时也希望你可以思考下自己是否有啥最佳实践可以分享。
从使用 Flink 到至今,遇到的 Flink 有很多,解决的问题更多(含帮助微信好友解决问题),所以对于 Flink 可能遇到的问题及解决办法都比较清楚,那么在这章就给大家讲解下几个 Flink 中比较常遇到的问题的解决办法。
常见错误导致 Flink 作业重启
不知道大家是否有遇到过这样的问题:整个 Job 一直在重启,并且还会伴随着一些错误(可以通过 UI 查看 Exceptions 日志),以下三张图片中的错误信息是笔者曾经生产环境遇到过的一些问题。
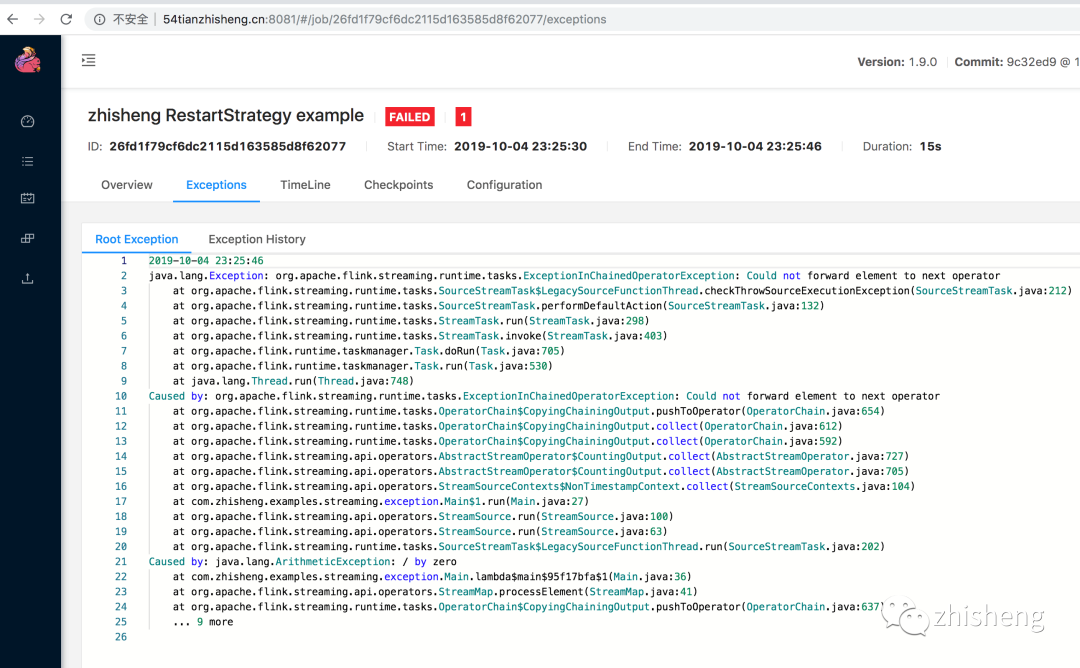
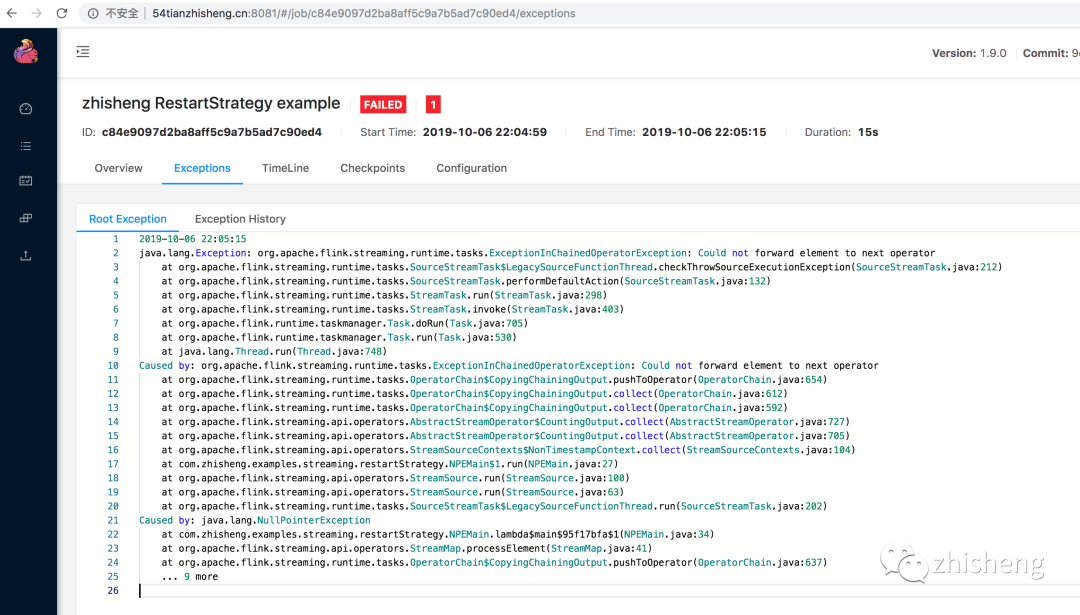
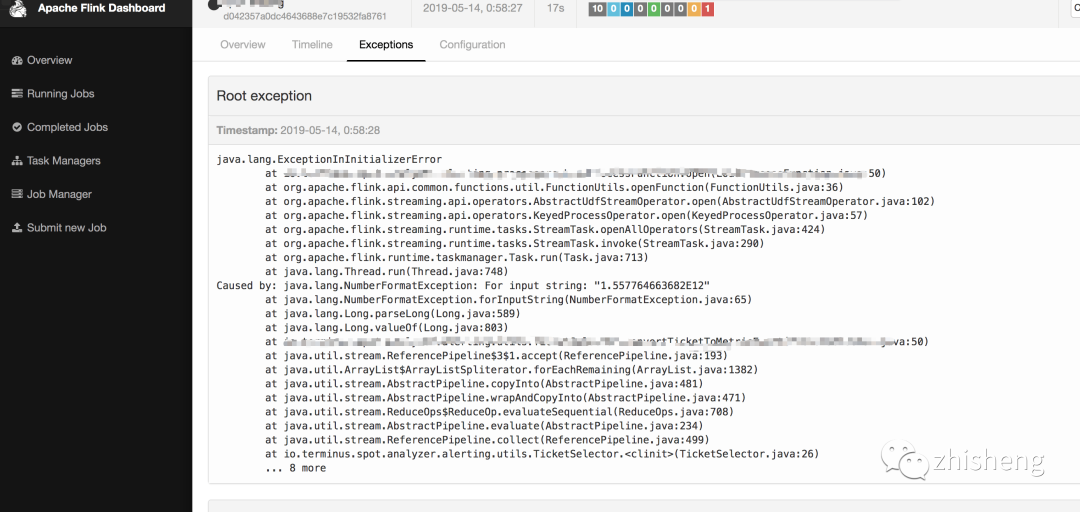
笔者就曾因为上图中的一个异常报错,作业一直重启,在深夜线上发版的时候,同事发现这个问题,凌晨两点的时候打电话把我叫醒起来修 BUG,真是惨的教训,哈哈哈,估计这辈子都忘不掉了!
其实遇到上面这种问题比较常见的,比如有时候因为数据的问题(不合规范、为 null 等),这时在处理这些脏数据的时候可能就会遇到各种各样的异常错误,比如空指针、数组越界、数据类型转换错误等。可能你会说只要过滤掉这种脏数据就行了,或者进行异常捕获就不会导致 Job 不断重启的问题了。
确实如此,如果做好了脏数据的过滤和异常的捕获,Job 的稳定性确实有保证,但是复杂的 Job 下每个算子可能都会产生出脏数据(包含源数据可能也会为空或者不合法的数据),你不可能在每个算子里面也用一个大的 try catch 做一个异常捕获,所以脏数据和异常简直就是防不胜防,不过我们还是要尽力的保证代码的健壮性,但是也要配置好 Flink Job 的 RestartStrategy(重启策略)。
RestartStrategy 简介
RestartStrategy,重启策略,在遇到机器或者代码等不可预知的问题时导致 Job 或者 Task 挂掉的时候,它会根据配置的重启策略将 Job 或者受影响的 Task 拉起来重新执行,以使得作业恢复到之前正常执行状态。Flink 中的重启策略决定了是否要重启 Job 或者 Task,以及重启的次数和每次重启的时间间隔。
为什么需要 RestartStrategy?
重启策略会让 Job 从上一次完整的 Checkpoint 处恢复状态,保证 Job 和挂之前的状态保持一致,另外还可以让 Job 继续处理数据,不会出现 Job 挂了导致消息出现大量堆积的问题,合理的设置重启策略可以减少 Job 不可用时间和避免人工介入处理故障的运维成本,因此重启策略对于 Flink Job 的稳定性来说有着举足轻重的作用。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 273
273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









