






pandas.read_excel()的作用:将Excel文件读取到pandas DataFrame中。
支持从本地文件系统或URL读取的xls,xlsx,xlsm,xlsb和odf文件扩展名。 支持读取单一sheet或几个sheet。
以下是该函数的全部参数:
pandas.read_excel(io,sheet_name=0,header=0,names=None,index_col=None,usecols=None,squeeze=False,dtype=None,engine=None,converters=None,true_values=None,false_values=None,skiprows=None,nrows=None,na_values=None,keep_default_na=True,verbose=False,parse_dates=False,date_parser=None,thousands=None,comment=None,skipfooter=0,convert_float=True,mangle_dupe_cols=True,**kwds)
我创建了一个excel,用作数据源:
sheet1:CRM
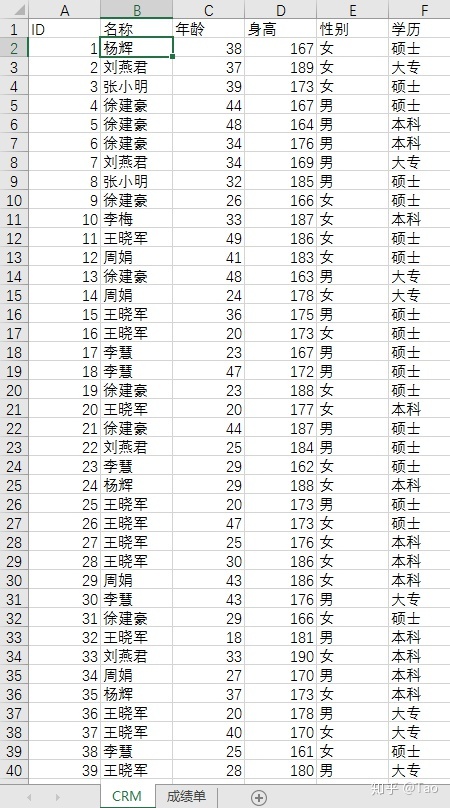
共39行
sheet2:成绩单
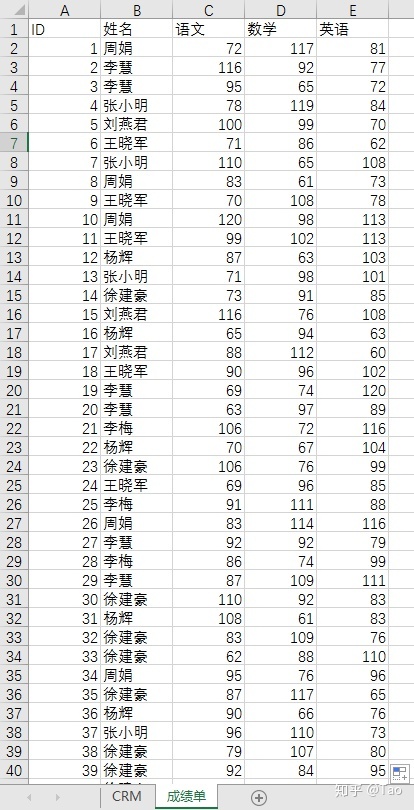
共50行
sheet3:销量表
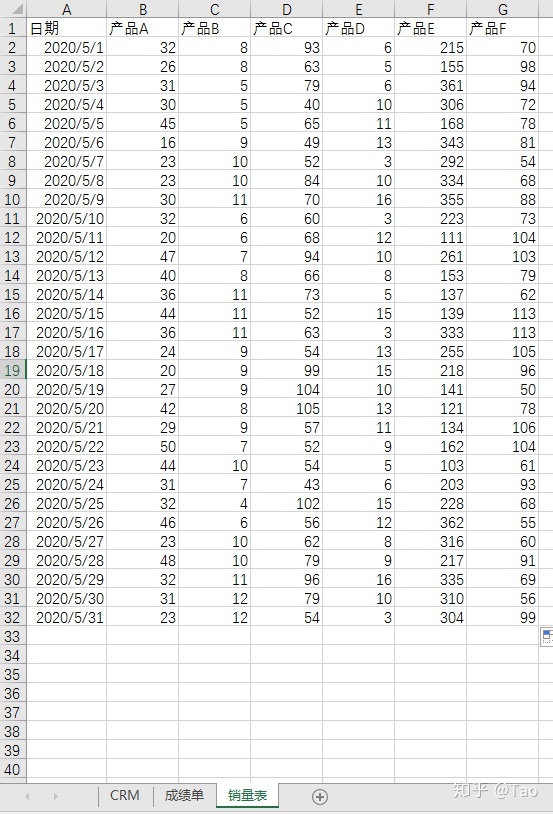
共31行
1.基本用法(io)
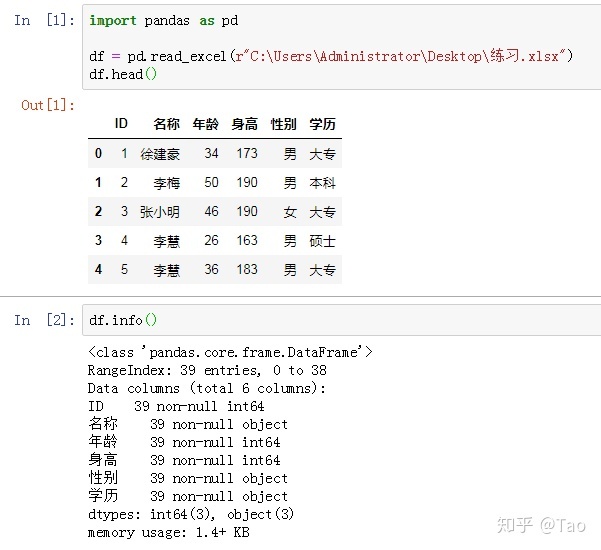
直接使用pd.read_excel(r"文件路径"),默认读取第一个sheet的全部数据
实际上就是第一个参数:io,支持str, bytes, ExcelFile, xlrd.Book, path object, or file-like object
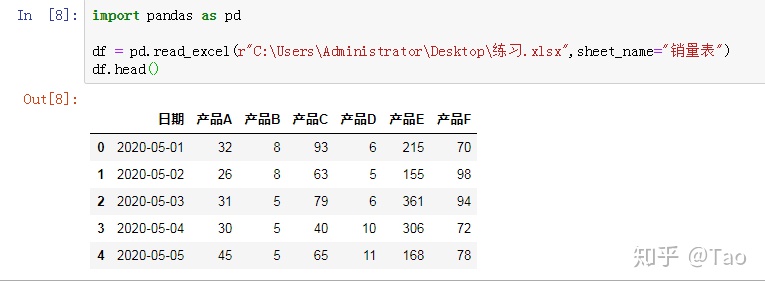
2.sheet_name(str, int, list, None, default 0)
str字符串用于引用的sheet的名称
int整数用于引用的sheet的索引(从0开始)
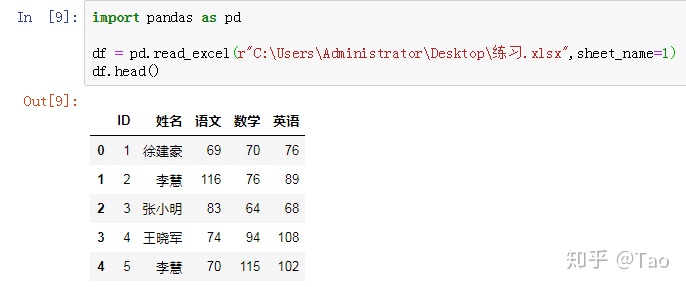
字符串或整数组成的列表用于引用特定的sheet
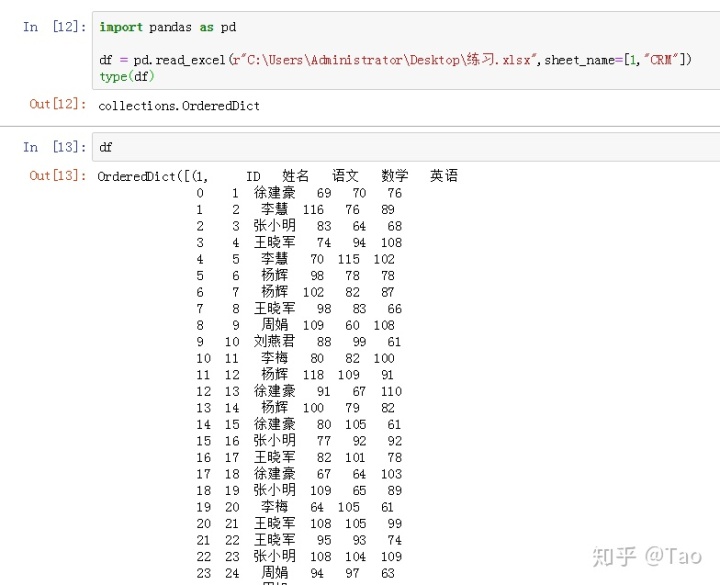
注意,读取后的数据类型是OrderedDict,将两个sheet的数据合并到了一个list中
None 表示引用所有sheet
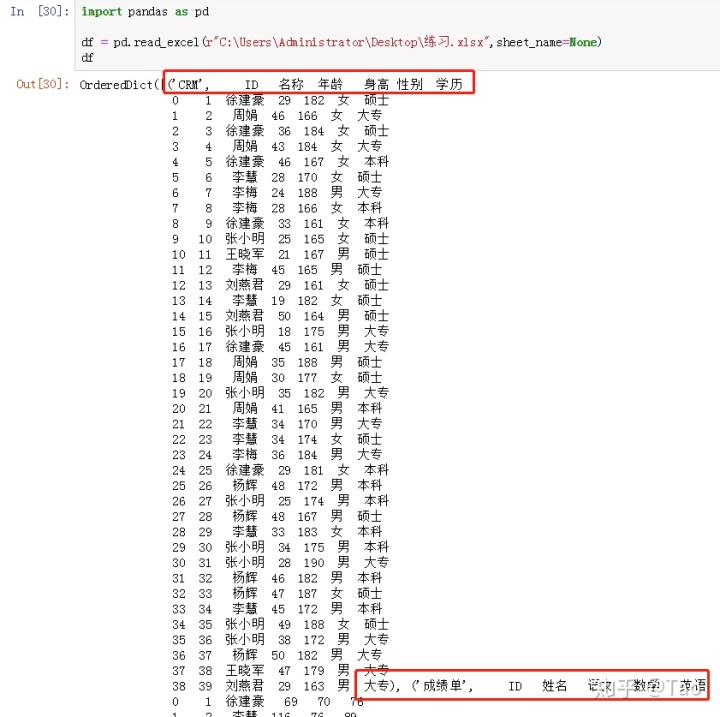
默认为0,表示不输入sheet_name的参数下,默认引用第一张sheet的数据
3.header(int, list of int, default 0)
表示用第几行作为表头,默认header=0,即默认第一行为表头
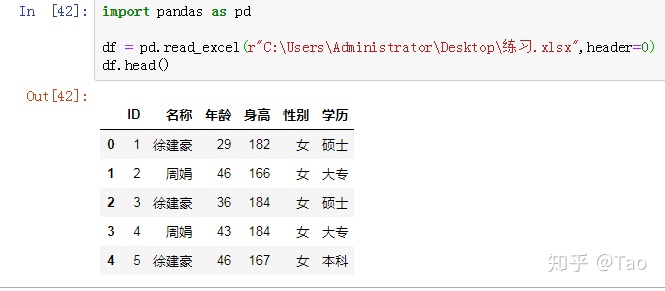
hearder=1:选择第二行为表头,第一行数据就不要了。其他以此类推
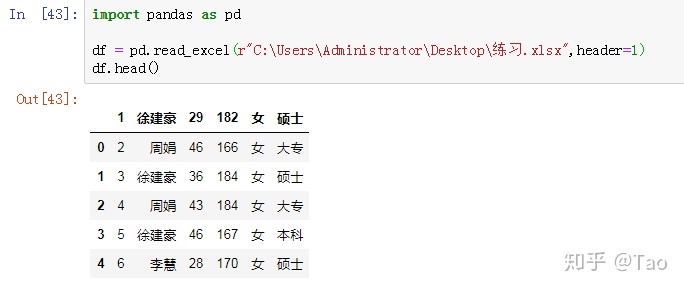
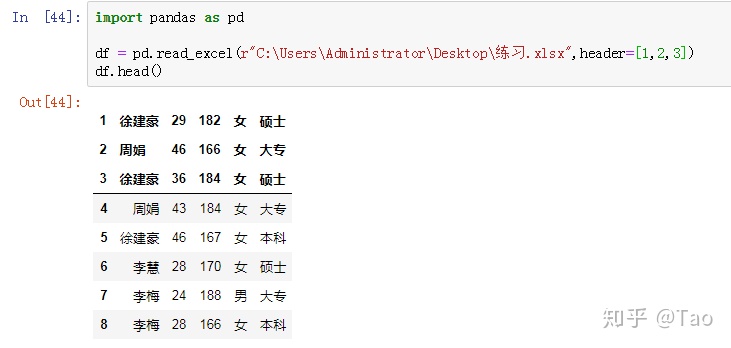
hearder=[1,2,3]:选择第2,3,4行的数据作为表头,第二行之上的数据不用
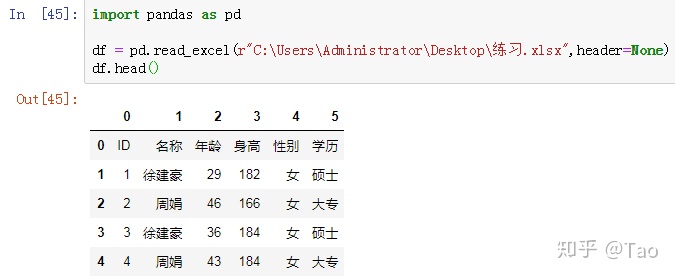
header=None :表示不使用数据源中的表头
4.names(array-like, default None)
表示自定义表头的名称,需要传递数组参数。
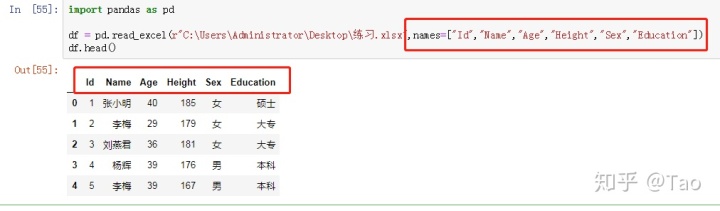
图例中更改了原始的表头。
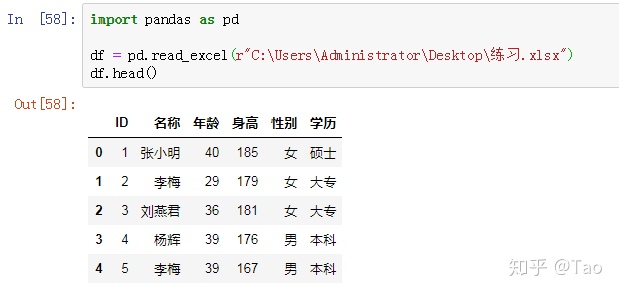
5.index_col(int, list of int, default None)
指定列为索引列,默认为None,也就是索引为0的列用作DataFrame的行标签。
None:
int整数:指定第几列为索引列
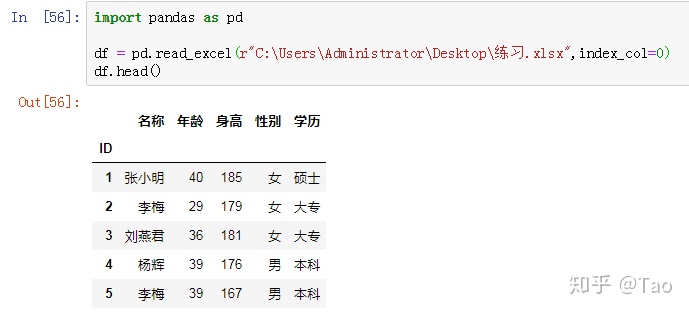
选择第一列"ID"列为索引列
list of int:选择列表中的整数列为索引列
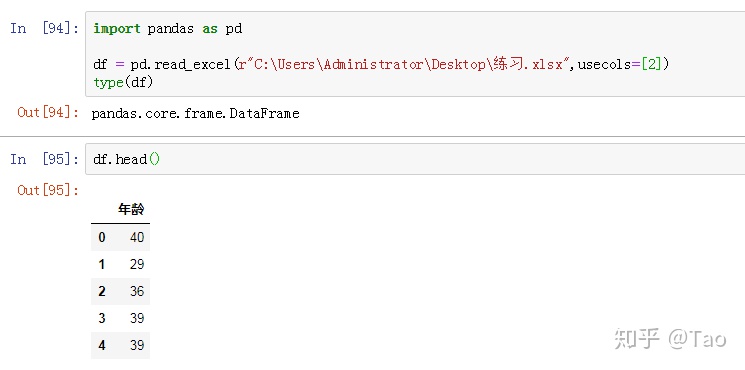
6.usecols(int, str, list-like, or callable default None)
- 默认为None,解析所有列。
- 如果为str,则表示Excel列字母和列范围的逗号分隔列表(例如“ A:E”或“ A,C,E:F”)。范围全闭。
- 如果为int,则表示解析到第几列。
- 如果为int列表,则表示解析那几列。
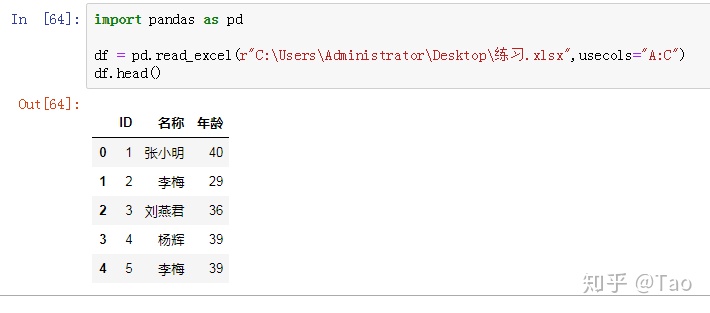
str:usecols="A:C",只读取从A列到C列的数据
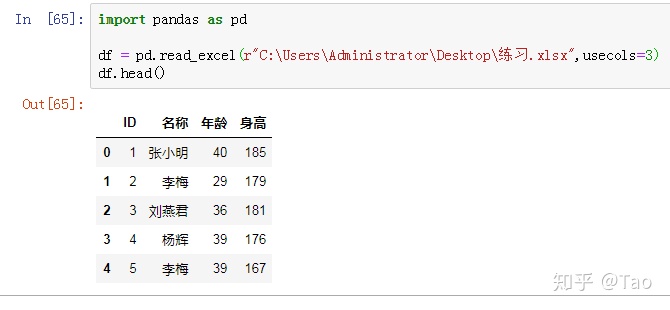
int:usecols=3,表示解析第0,1,2,3列,共4列
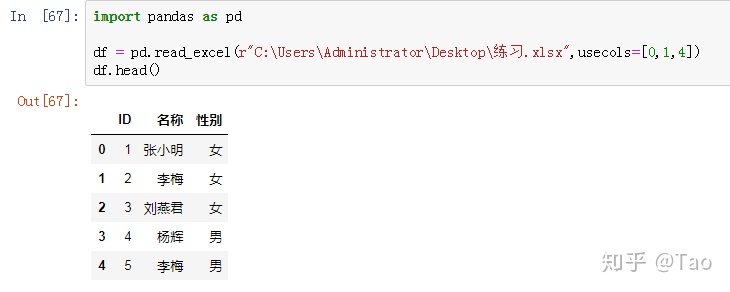
int of list:usecols=[0,1,4],表示解析第1列,第2列,第5列的数据
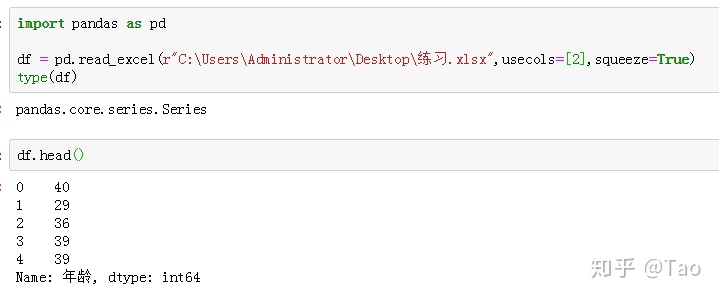
7.squeeze(bool, default False)
默认为False。如果设置squeeze=True则表示如果解析的数据只包含一列,则返回一个Series。
默认情况下:
设置squeeze=True情况下:
8.dtype(Type name or dict of column -> type, default None)
列的类型名称或字典,默认为None,也就是不改变数据类型。
其作用是指定列的数据类型。
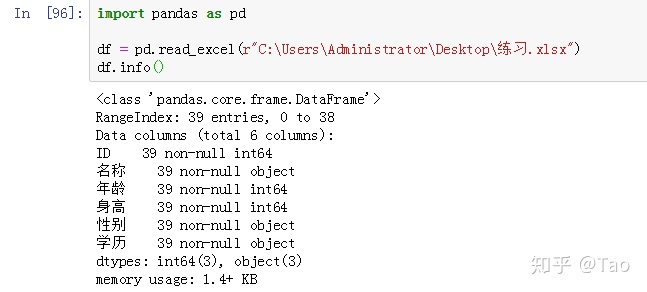
先看下目前的各列数据类型:
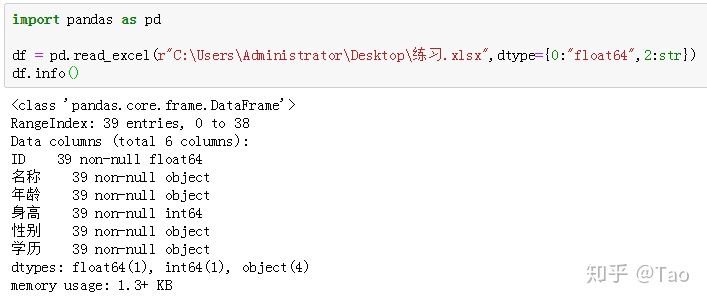
再将ID和年龄列的数据类型从int64转换为float64和str
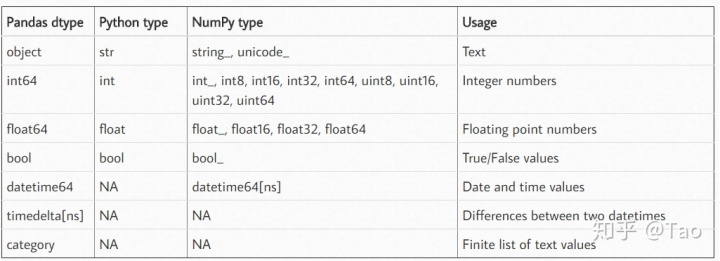
这是pandas的所有数据类型
9.engine(str, default None)
可以接受的参数有“ xlrd”,“ openpyxl”或“ odf”,用于使用第三方的库去解析excel文件。
10.converters(dict, default None)
对指定列的数据进行指定函数的处理,传入参数为列名与函数组成的字典。key 可以是列名或者列的序号,values是函数,可以def函数或者直接lambda都行。
先读取前三列数据:
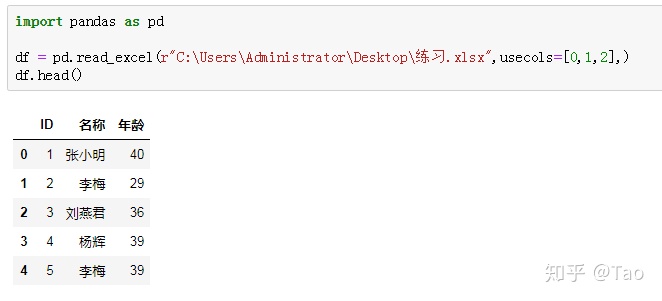
对第2列的所有名称加上"",把第三列的所有年龄都减10

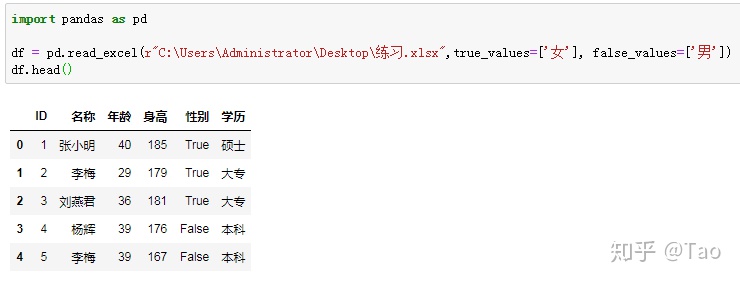
11.true_values(list,default None)
将指定的文本转换为True,默认为None
12.false_values(list,default None)
将指定的文本转换为False,默认为None
将性别中的女转换为True,男转换为False
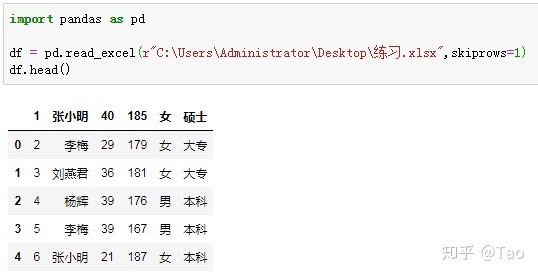
13.skiprows(list like)
跳过指定的行
skiprows=1 跳过第1行
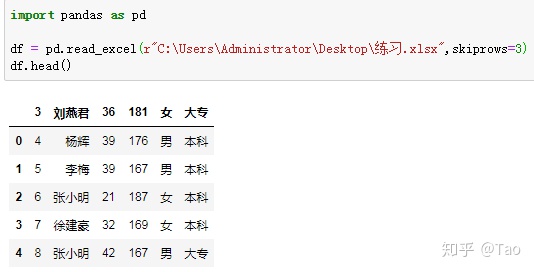
skiprows=3 跳过前3行
skiprows=[1,3,5] 跳过第1,3,5行
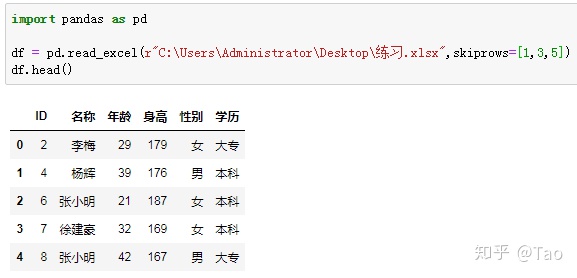
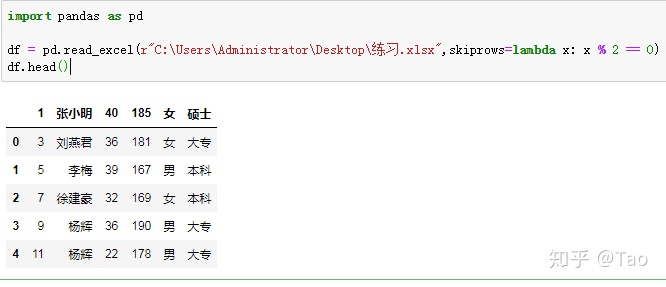
skiprows=lambda x: x % 2 == 0 跳过偶数行
14.nrows(int, default None)
默认为None
指定需要读取前多少行,通常用于较大的数据文件中。
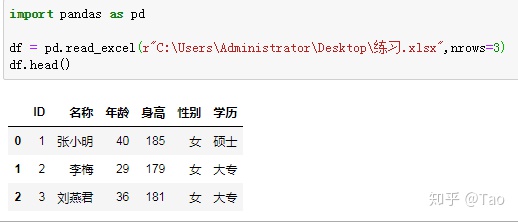
nrows=3 读取前三行
15.na_values(scalar, str, list-like, or dict, default None)
指定某些列的某些值为NaN
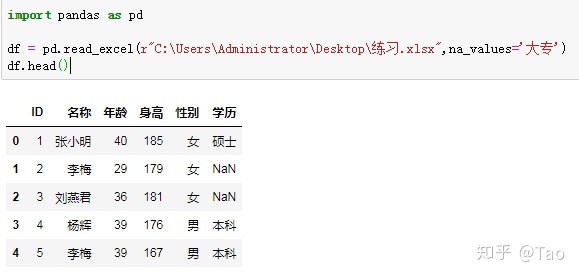
na_values='大专',指定大专为NaN
16.keep_default_na(bool, default True)
表示导入数据时是否导入空值。
默认为True,即自动识别空值并导入
常用的参数就这么多~觉得有用的各位记得点赞收藏哦~
Tao:Python处理数据常用方法(pandas版)zhuanlan.zhihu.com














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









