







excel表的读取在python中是非常重要的,为了方便今后的使用,我将我学习用python读取excel表的过程记录下来,以便今后回顾时能快速想起各种方法。下图为示例中使用的excel表中的内容
sheet1:学生的信息
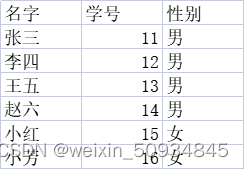
sheet2:成绩
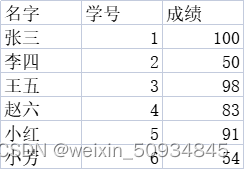
在pandas中一般使用函数read_excel来进行excel表的读取,其参数如下:
pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, decimal='.', comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options=None)
下面先来分析该函数比较常见的参数:
io(文件路径):
文件的路径,既可以是本地的地址,也可以是网络地址。本文主要关注本地地址。
参数可能的种类str, bytes, ExcelFile, xlrd.Book, path object, or file-like object
import pandas as pd
from numpy import disp
#路径前面的r表示对路径中的'\'进行转义,否则会出现'\n'之类的转义字符,导致文件的路径出错
#没r和有r的对比
test1 = pd.read_excel("D:\python\pycharm_workplace\excel_ctrl\a.xlsx");#即使在相应的路径有这个文件,这个会出错
test1 = pd.read_excel(r"D:\python\pycharm_workplace\excel_ctrl\a.xlsx");
#相对路径:我测试的时候excel文件和py文件是在同一目录下
data1 = pd.read_excel(r"z.xlsx");
#绝对路径
data2 = pd.read_excel(r"D:\python\pycharm_workplace\excel_ctrl\z.xlsx");
disp(data1);
disp(data2);
结果如下
D:\python\python\python.exe D:/python/pycharm_workplace/excel_ctrl/excel_ctrl_test.py
名字 学号 性别
0 张三 11 男
1 李四 12 男
2 王五 13 男
3 赵六 14 男
4 小红 15 女
5 小芳 16 女
名字 学号 性别
0 张三 11 男
1 李四 12 男
2 王五 13 男
3 赵六 14 男
4 小红 15 女
5 小芳 16 女
Process finished with exit code 0
该参数没有默认值,也就是说是必须要填的,其余参数都有默认值,可以不填。
sheet_name(选择sheet)
选择不同的sheet,可以输入sheet的名字或者序号,默认值为0
参数可能的种类str, int, list, or None, default 0
import pandas as pd
from numpy import disp
#参数类型为str,表示选择的sheet的名字
data1 = pd.read_excel(r"z.xlsx", sheet_name="学生的信息");
disp(data1);
disp("===========");
#int类型,表示选择的sheet的索引(从0开始)
data2 = pd.read_excel(r"z.xlsx", sheet_name=1);
disp(data2);
disp("===========");
#list类型,表示选择多个sheet,list的元素可以为str、int
data3 = pd.read_excel(r"z.xlsx", sheet_name=[0, 1]);
disp(data3);
disp("===========");
#None,表示选择全部sheet
data4 = pd.read_excel(r"z.xlsx", sheet_name=0);
disp(data4);
D:\python\python\python.exe D:/python/pycharm_workplace/excel_ctrl/excel_ctrl_test.py
名字 学号 性别
0 张三 11 男
1 李四 12 男
2 王五 13 男
3 赵六 14 男
4 小红 15 女
5 小芳 16 女
===========
名字 学号 成绩
0 张三 1 100
1 李四 2 50
2 王五 3 98
3 赵六 4 83
4 小红 5 91
5 小芳 6 54
===========
{0: 名字 学号 性别
0 张三 11 男
1 李四 12 男
2 王五 13 男
3 赵六 14 男
4 小红 15 女
5 小芳 16 女, 1: 名字 学号 成绩
0 张三 1 100
1 李四 2 50
2 王五 3 98
3 赵六 4 83
4 小红 5 91
5 小芳 6 54}
===========
{'学生的信息': 名字 学号 性别
0 张三 11 男
1 李四 12 男
2 王五 13 男
3 赵六 14 男
4 小红 15 女
5 小芳 16 女, '成绩': 名字 学号 成绩
0 张三 1 100
1 李四 2 50
2 王五 3 98
3 赵六 4 83
4 小红 5 91
5 小芳 6 54, 'Sheet3': Empty DataFrame
Columns: []
Index: []}
Process finished with exit code 0
header(选择表头)
表示以第几行为表头,默认为0
参数可能的种类int, list of int, default 0
import pandas as pd
from numpy import disp
#参数类型为int,表示选择第几行为表头,行数比表头小的都抛弃
data1 = pd.read_excel(r"z.xlsx", header=2);
disp(data1);
disp("===============");
#参数类型为list,表示选择那几行为表头,那些没被选上的行数比表头中行数小的都抛弃
data1 = pd.read_excel(r"z.xlsx", header=[2,4]);
disp(data1);
D:\python\python\python.exe D:/python/pycharm_workplace/excel_ctrl/excel_ctrl_test.py
李四 12 男
0 王五 13 男
1 赵六 14 男
2 小红 15 女
3 小芳 16 女
===============
李四 12 男
赵六 14 男
0 小红 15 女
1 小芳 16 女
Process finished with exit code 0
names(改变表头名字)
长度不能超出excel中列的数目,作用是代替原来表头,由于names只有一维,所以header中不能指定多个表头,而且即使names中的长度小于列的数目(即使数组中的元素个数为0),names也会完全替代原来的表头
参数可能的种类array-like, default None
import pandas as pd
from numpy import disp
#代替原来的 1 2 3 作为表头
data1 = pd.read_excel(r"z.xlsx", names=["stu","ID","sex"]);
disp(data1);
disp("===============");
#代替某行成为表头
data2 = pd.read_excel(r"z.xlsx", header=[3] , names=["stu","ID","sex"]);
disp(data2);
disp("===============");
#元素个数小于列数时的情况
data1 = pd.read_excel(r"z.xlsx", header=[3] , names=["stu","ID"]);
disp(data1);
结果如下:
D:\python\python\python.exe D:/python/pycharm_workplace/excel_ctrl/excel_ctrl_test.py
stu ID sex
0 张三 11 男
1 李四 12 男
2 王五 13 男
3 赵六 14 男
4 小红 15 女
5 小芳 16 女
===============
stu ID sex
0 赵六 14 男
1 小红 15 女
2 小芳 16 女
===============
stu ID
赵六 14 男
小红 15 女
小芳 16 女
Process finished with exit code 0
index_col(选择索引列)
选择索引列,默认为None,选择索引列的时候不会像之前选择表头那样丢掉一部分数据,而仅仅是改变次序而已
参数可能的种类int, list of int, default None
None表示使用默认的列(不属于输入的内容)作为索引列
import pandas as pd
from numpy import disp
#参数类型为int,表示选择第几列作为索引列
data1 = pd.read_excel(r"z.xlsx", index_col=2);
disp(data1);
disp("===============");
#参数类型为str,表示选择名字为什么的列作为索引列(我也不知道为什么能)
data2 = pd.read_excel(r"z.xlsx", index_col="学号");
disp(data2);
disp("===============");
#参数类型为list of int,表示选择那些列作为索引列
data3 = pd.read_excel(r"z.xlsx", index_col=[1,2]);
disp(data3);
D:\python\python\python.exe D:/python/pycharm_workplace/excel_ctrl/excel_ctrl_test.py
名字 学号
性别
男 张三 11
男 李四 12
男 王五 13
男 赵六 14
女 小红 15
女 小芳 16
===============
名字 性别
学号
11 张三 男
12 李四 男
13 王五 男
14 赵六 男
15 小红 女
16 小芳 女
===============
名字
学号 性别
11 男 张三
12 男 李四
13 男 王五
14 男 赵六
15 女 小红
16 女 小芳
Process finished with exit code 0
usecols(选择读入的列)
选择解析的行,也就是选择读入的行。
参数可能类型str, list-like, or callable, default None
注意,int类型不行,多列选择时,返回的列的先后与输入需要的列的先后无关,而是与列在excel表中原来顺序相同
import pandas as pd
from numpy import disp
#参数类型为str,对应excel表中每列上面的数字
data1 = pd.read_excel(r"z.xlsx", usecols="A");
disp(data1);
disp("===============");
#还可以利用str进行多列的选择
data2 = pd.read_excel(r"z.xlsx", usecols="C,B");
disp(data2);
disp("===============");
#参数为list-like类型,表示选择哪些列
data3 = pd.read_excel(r"z.xlsx", usecols=[1,2]);
disp(data3);
D:\python\python\python.exe D:/python/pycharm_workplace/excel_ctrl/excel_ctrl_test.py
名字
0 张三
1 李四
2 王五
3 赵六
4 小红
5 小芳
===============
学号 性别
0 11 男
1 12 男
2 13 男
3 14 男
4 15 女
5 16 女
===============
学号 性别
0 11 男
1 12 男
2 13 男
3 14 男
4 15 女
5 16 女
Process finished with exit code 0
squeeze(读入只有1列时返回一个Series)
当该参数为True的时候,若读入只有一列,则返回一个Series,如果是两列或多列,则与该参数为true的时候返回相同
import pandas as pd
from numpy import disp
#一列的时候两者的对比
data1 = pd.read_excel(r"z.xlsx", usecols=[1]);
disp(data1);
disp("=========");
data1 = pd.read_excel(r"z.xlsx", usecols=[1], squeeze=True);
disp(data1);
disp("=========");
#两列的时候两者的对比
data1 = pd.read_excel(r"z.xlsx", usecols=[1,2]);
disp(data1);
disp("=========");
data1 = pd.read_excel(r"z.xlsx", usecols=[1,2], squeeze=True);
disp(data1);
D:\python\python\python.exe D:/python/pycharm_workplace/excel_ctrl/excel_ctrl_test.py
学号
0 11
1 12
2 13
3 14
4 15
5 16
=========
0 11
1 12
2 13
3 14
4 15
5 16
Name: 学号, dtype: int64
=========
学号 性别
0 11 男
1 12 男
2 13 男
3 14 男
4 15 女
5 16 女
=========
学号 性别
0 11 男
1 12 男
2 13 男
3 14 男
4 15 女
5 16 女
Process finished with exit code 0
不常用参数
碰到再总结
结语
以上只是read_excel的一些常用参数,还有其他很多参数,当以后碰到时再总结















 2787
2787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









