





2.2 mapper加载与初始化
前面说过mybatis mapper文件的加载主要有两大类,通过package加载和明确指定的方式。
一般来说,对于简单语句来说,使用注解代码会更加清晰,然而Java注解对于复杂语句比如同时包含了构造器、鉴别器、resultMap来说就会非常混乱,应该限制使用,此时应该使用XML文件,因为注解至少至今为止不像XML/Gradle一样能够很好的表示嵌套关系。mybatis完整的注解列表以及含义可参考http://www.mybatis.org/mybatis-3/java-api.html或者http://blog.51cto.com/computerdragon/1399742或者源码org.apache.ibatis.annotations包:

为了更好的理解上下文语义,建议读者对XML配置对应的注解先了解,这样看起源码来会更加顺畅。我们先来回顾一下通过注解配置的典型mapper接口:
@Select("select *from User where id=#{id} and userName like #{name}")
public User retrieveUserByIdAndName(@Param("id")int id,@Param("name")String names);
@Insert("INSERT INTO user(userName,userAge,userAddress) VALUES(#{userName},#{userAge},#{userAddress})")
public void addNewUser(User user);
@Insert("insert into table3 (id, name) values(#{nameId}, #{name})")
@SelectKey(statement="call next value for TestSequence", keyProperty="nameId", before=true, resultType=int.class)
int insertTable3(Name name);
@Results(id = "userResult", value = {
@Result(property = "id", column = "uid", id = true),
@Result(property = "firstName", column = "first_name"),
@Result(property = "lastName", column = "last_name")
})
@TypeDiscriminator(column = "type",
cases={
@Case(value="1",type=RegisterEmployee.class,results={
@Result(property="salay")
}),
@Case(value="2",type=TimeEmployee.class,results={
@Result(property="time")
})
}
)
@Select("select * from users where id = #{id}")
User getUserById(Integer id);
@Results(id = "companyResults")
@ConstructorArgs({
@Arg(property = "id", column = "cid", id = true),
@Arg(property = "name", column = "name")
})
@Select("select * from company where id = #{id}")
Company getCompanyById(Integer id);
@ResultMap(id = "xmlUserResults")
@SelectProvider(type = UserSqlBuilder.class, method = "buildGetUsersByName")
List<User> getUsersByName(String name);
// 注:建议尽可能避免使用SqlBuild的模式生成的,如果因为功能需要必须动态生成SQL的话,也是直接写SQL拼接返回,而不是一堆类似SELECT()、FROM()的函数调用,这只会让维护成为噩梦,这思路的设计者不是知道怎么想的, 此处仅用于演示XXXProvider功能,但是XXXProvider模式本身的设计在关键时候还是比较清晰的。
class UserSqlBuilder {
public String buildGetUsersByName(final String name) {
return new SQL(){{
SELECT("*");
FROM("users");
if (name != null) {
WHERE("name like #{value} || '%'");
}
ORDER_BY("id");
}}.toString();
}
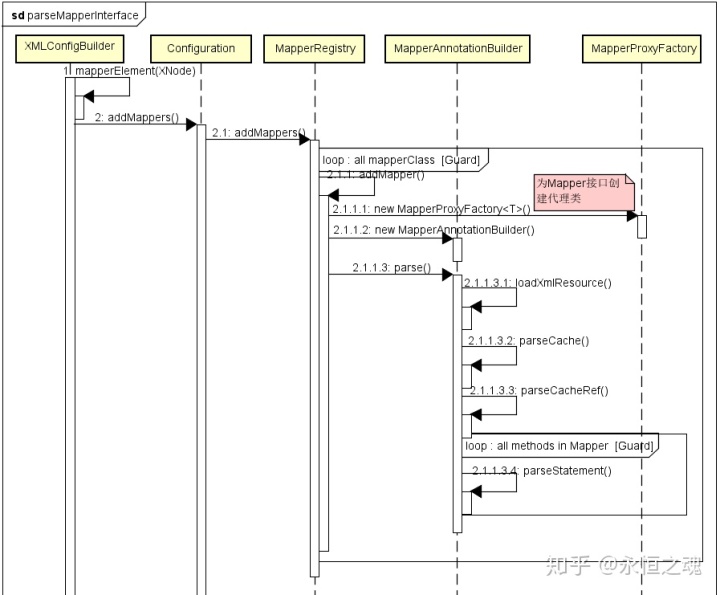
}我们先来看通过package自动搜索加载的方式,它的范围由addMappers的参数packageName指定的包名以及父类superType确定,其整体流程如下:
/**
* @since 3.2.2
*/
public void addMappers(String packageName, Class<?> superType) {
// mybatis框架提供的搜索classpath下指定package以及子package中符合条件(注解或者继承于某个类/接口)的类,默认使用Thread.currentThread().getContextClassLoader()返回的加载器,和spring的工具类殊途同归。
ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<Class<?>>();
// 无条件的加载所有的类,因为调用方传递了Object.class作为父类,这也给以后的指定mapper接口预留了余地
resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
// 所有匹配的calss都被存储在ResolverUtil.matches字段中
Set<Class<? extends Class<?>>> mapperSet = resolverUtil.getClasses();
for (Class<?> mapperClass : mapperSet) {
//调用addMapper方法进行具体的mapper类/接口解析
addMapper(mapperClass);
}
}
/**
* 外部调用的入口
* @since 3.2.2
*/
public void addMappers(String packageName) {
addMappers(packageName, Object.class);
}
public <T> void addMapper(Class<T> type) {
// 对于mybatis mapper接口文件,必须是interface,不能是class
if (type.isInterface()) {
// 判重,确保只会加载一次不会被覆盖
if (hasMapper(type)) {
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
// 为mapper接口创建一个MapperProxyFactory代理
knownMappers.put(type, new MapperProxyFactory<T>(type));
// It's important that the type is added before the parser is run
// otherwise the binding may automatically be attempted by the
// mapper parser. If the type is already known, it won't try.
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
loadCompleted = true;
} finally {
//剔除解析出现异常的接口
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}knownMappers是MapperRegistry的主要字段,维护了Mapper接口和代理类的映射关系,key是mapper接口类,value是MapperProxyFactory,其定义如下:
private final Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap<Class<?>, MapperProxyFactory<?>>();
public class MapperProxyFactory<T> {
private final Class<T> mapperInterface;
private final Map<Method, MapperMethod> methodCache = new ConcurrentHashMap<Method, MapperMethod>();
public MapperProxyFactory(Class<T> mapperInterface) {
this.mapperInterface = mapperInterface;
}
public Class<T> getMapperInterface() {
return mapperInterface;
}
public Map<Method, MapperMethod> getMethodCache() {
return methodCache;
}
@SuppressWarnings("unchecked")
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
}从定义看出,MapperProxyFactory主要是维护mapper接口的方法与对应mapper文件中具体CRUD节点的关联关系。其中每个Method与对应MapperMethod维护在一起。MapperMethod是mapper中具体映射语句节点的内部表示。
首先为mapper接口创建MapperProxyFactory,然后创建MapperAnnotationBuilder进行具体的解析,MapperAnnotationBuilder在解析前的构造器中完成了下列工作:
public MapperAnnotationBuilder(Configuration configuration, Class<?> type) {
String resource = type.getName().replace('.', '/') + ".java (best guess)";
this.assistant = new MapperBuilderAssistant(configuration, resource);
this.configuration = configuration;
this.type = type;
sqlAnnotationTypes.add(Select.class);
sqlAnnotationTypes.add(Insert.class);
sqlAnnotationTypes.add(Update.class);
sqlAnnotationTypes.add(Delete.class);
sqlProviderAnnotationTypes.add(SelectProvider.class);
sqlProviderAnnotationTypes.add(InsertProvider.class);
sqlProviderAnnotationTypes.add(UpdateProvider.class);
sqlProviderAnnotationTypes.add(DeleteProvider.class);
} 其中的MapperBuilderAssistant和XMLConfigBuilder一样,都是继承于BaseBuilder。Select.class/Insert.class等注解指示该方法对应的真实sql语句类型分别是select/insert。
SelectProvider.class/InsertProvider.class主要用于动态SQL,它们允许你指定一个类名和一个方法在具体执行时返回要运行的SQL语句。MyBatis会实例化这个类,然后执行指定的方法。
MapperBuilderAssistant初始化完成之后,就调用build.parse()进行具体的mapper接口文件加载与解析,如下所示:
public void parse() {
String resource = type.toString();
//首先根据mapper接口的字符串表示判断是否已经加载,避免重复加载,正常情况下应该都没有加载
if (!configuration.isResourceLoaded(resource)) {
loadXmlResource();
configuration.addLoadedResource(resource);
// 每个mapper文件自成一个namespace,通常自动匹配就是这么来的,约定俗成代替人工设置最简化常见的开发
assistant.setCurrentNamespace(type.getName());
parseCache();
parseCacheRef();
Method[] methods = type.getMethods();
for (Method method : methods) {
try {
// issue #237
if (!method.isBridge()) {
parseStatement(method);
}
} catch (IncompleteElementException e) {
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
parsePendingMethods();
}整体流程为:
1、首先加载mapper接口对应的xml文件并解析。loadXmlResource和通过resource、url解析相同,都是解析mapper文件中的定义,他们的入口都是XMLMapperBuilder.parse(),我们稍等会儿专门专门分析,这一节先来看通过注解方式配置的mapper的解析(注:对于一个mapper接口,不能同时使用注解方式和xml方式,任何时候只能之一,但是不同的mapper接口可以混合使用这两种方式)。
2、解析缓存注解;
mybatis中缓存注解的定义为:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface CacheNamespace {
Class<? extends org.apache.ibatis.cache.Cache> implementation() default PerpetualCache.class;
Class<? extends org.apache.ibatis.cache.Cache> eviction() default LruCache.class;
long flushInterval() default 0;
int size() default 1024;
boolean readWrite() default true;
boolean blocking() default false;
/**
* Property values for a implementation object.
* @since 3.4.2
*/
Property[] properties() default {};
}从上面的定义可以看出,和在XML中的是一一对应的。缓存的解析很简单,这里不展开细细讲解。
3、解析缓存参照注解。缓存参考的解析也很简单,这里不展开细细讲解。
4、解析非桥接方法。在正式开始之前,我们先来看下什么是桥接方法。桥接方法是 JDK 1.5 引入泛型后,为了使Java的泛型方法生成的字节码和 1.5 版本前的字节码相兼容,由编译器自动生成的方法。那什么时候,编译器会生成桥接方法呢,举个例子,一个子类在继承(或实现)一个父类(或接口)的泛型方法时,在子类中明确指定了泛型类型,那么在编译时编译器会自动生成桥接方法。参考:
http:// blog.csdn.net/mhmyqn/ar ticle/details/47342577 https:// docs.oracle.com/javase/ specs/jvms/se7/html/jvms-4.html#jvms-4.6 https:// docs.oracle.com/javase/ specs/jls/se7/html/jls-15.html#jls-15.12.4.5
所以正常情况下,只要在实现mybatis mapper接口的时候,没有继承根Mapper或者继承了根Mapper但是没有写死泛型类型的时候,是不会成为桥接方法的。现在来看parseStatement的主要实现代码(提示:因为注解方式通常不用于复杂的配置,所以这里我们进行简单的解析,在XML部分进行详细说明):
void parseStatement(Method method) {
// 获取参数类型,如果有多个参数,这种情况下就返回org.apache.ibatis.binding.MapperMethod.ParamMap.class,ParamMap是一个继承于HashMap的类,否则返回实际类型
Class<?> parameterTypeClass = getParameterType(method);
// 获取语言驱动器
LanguageDriver languageDriver = getLanguageDriver(method);
// 获取方法的SqlSource对象,只有指定了@Select/@Insert/@Update/@Delete或者对应的Provider的方法才会被当作mapper,否则只是和mapper文件中对应语句的一个运行时占位符
SqlSource sqlSource = getSqlSourceFromAnnotations(method, parameterTypeClass, languageDriver);
if (sqlSource != null) {
// 获取方法的属性设置,对应<select>中的各种属性
Options options = method.getAnnotation(Options.class);
final String mappedStatementId = type.getName() + "." + method.getName();
Integer fetchSize = null;
Integer timeout = null;
StatementType statementType = StatementType.PREPARED;
ResultSetType resultSetType = ResultSetType.FORWARD_ONLY;
// 获取语句的CRUD类型
SqlCommandType sqlCommandType = getSqlCommandType(method);
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
boolean flushCache = !isSelect;
boolean useCache = isSelect;
KeyGenerator keyGenerator;
String keyProperty = "id";
String keyColumn = null;
// 只有INSERT/UPDATE才解析SelectKey选项,总体来说,它的实现逻辑和XML基本一致,这里不展开详述
if (SqlCommandType.INSERT.equals(sqlCommandType) || SqlCommandType.UPDATE.equals(sqlCommandType)) {
// first check for SelectKey annotation - that overrides everything else
SelectKey selectKey = method.getAnnotation(SelectKey.class);
if (selectKey != null) {
keyGenerator = handleSelectKeyAnnotation(selectKey, mappedStatementId, getParameterType(method), languageDriver);
keyProperty = selectKey.keyProperty();
} else if (options == null) {
keyGenerator = configuration.isUseGeneratedKeys() ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
} else {
keyGenerator = options.useGeneratedKeys() ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
keyProperty = options.keyProperty();
keyColumn = options.keyColumn();
}
} else {
keyGenerator = NoKeyGenerator.INSTANCE;
}
if (options != null) {
if (FlushCachePolicy.TRUE.equals(options.flushCache())) {
flushCache = true;
} else if (FlushCachePolicy.FALSE.equals(options.flushCache())) {
flushCache = false;
}
useCache = options.useCache();
fetchSize = options.fetchSize() > -1 || options.fetchSize() == Integer.MIN_VALUE ? options.fetchSize() : null; //issue #348
timeout = options.timeout() > -1 ? options.timeout() : null;
statementType = options.statementType();
resultSetType = options.resultSetType();
}
String resultMapId = null;
// 解析@ResultMap注解,如果有@ResultMap注解,就是用它,否则才解析@Results
// @ResultMap注解用于给@Select和@SelectProvider注解提供在xml配置的<resultMap>,如果一个方法上同时出现@Results或者@ConstructorArgs等和结果映射有关的注解,那么@ResultMap会覆盖后面两者的注解
ResultMap resultMapAnnotation = method.getAnnotation(ResultMap.class);
if (resultMapAnnotation != null) {
String[] resultMaps = resultMapAnnotation.value();
StringBuilder sb = new StringBuilder();
for (String resultMap : resultMaps) {
if (sb.length() > 0) {
sb.append(",");
}
sb.append(resultMap);
}
resultMapId = sb.toString();
} else if (isSelect) {
//如果是查询,且没有明确设置ResultMap,则根据返回类型自动解析生成ResultMap
resultMapId = parseResultMap(method);
}
assistant.addMappedStatement(
mappedStatementId,
sqlSource,
statementType,
sqlCommandType,
fetchSize,
timeout,
// ParameterMapID
null,
parameterTypeClass,
resultMapId,
getReturnType(method),
resultSetType,
flushCache,
useCache,
// TODO gcode issue #577
false,
keyGenerator,
keyProperty,
keyColumn,
// DatabaseID
null,
languageDriver,
// ResultSets
options != null ? nullOrEmpty(options.resultSets()) : null);
}
}重点来看没有带@ResultMap注解的查询方法parseResultMap(Method):
private String parseResultMap(Method method) {
// 获取方法的返回类型
Class<?> returnType = getReturnType(method);
// 获取构造器
ConstructorArgs args = method.getAnnotation(ConstructorArgs.class);
// 获取@Results注解,也就是注解形式的结果映射
Results results = method.getAnnotation(Results.class);
// 获取鉴别器
TypeDiscriminator typeDiscriminator = method.getAnnotation(TypeDiscriminator.class);
// 产生resultMapId
String resultMapId = generateResultMapName(method);
applyResultMap(resultMapId, returnType, argsIf(args), resultsIf(results), typeDiscriminator);
return resultMapId;
}
// 如果有resultMap设置了Id,就直接返回类名.resultMapId. 否则返回类名.方法名.以-分隔拼接的方法参数
private String generateResultMapName(Method method) {
Results results = method.getAnnotation(Results.class);
if (results != null && !results.id().isEmpty()) {
return type.getName() + "." + results.id();
}
StringBuilder suffix = new StringBuilder();
for (Class<?> c : method.getParameterTypes()) {
suffix.append("-");
suffix.append(c.getSimpleName());
}
if (suffix.length() < 1) {
suffix.append("-void");
}
return type.getName() + "." + method.getName() + suffix;
}
private void applyResultMap(String resultMapId, Class<?> returnType, Arg[] args, Result[] results, TypeDiscriminator discriminator) {
List<ResultMapping> resultMappings = new ArrayList<ResultMapping>();
applyConstructorArgs(args, returnType, resultMappings);
applyResults(results, returnType, resultMappings);
Discriminator disc = applyDiscriminator(resultMapId, returnType, discriminator);
// TODO add AutoMappingBehaviour
assistant.addResultMap(resultMapId, returnType, null, disc, resultMappings, null);
createDiscriminatorResultMaps(resultMapId, returnType, discriminator);
}
private void createDiscriminatorResultMaps(String resultMapId, Class<?> resultType, TypeDiscriminator discriminator) {
if (discriminator != null) {
// 对于鉴别器来说,和XML配置的差别在于xml中可以外部公用的resultMap,在注解中,则只提供了内嵌式的resultMap定义
for (Case c : discriminator.cases()) {
// 从内部实现的角度,因为内嵌式的resultMap定义也会创建resultMap,所以XML的实现也一样,对于内嵌式鉴别器每个分支resultMap,其命名为映射方法的resultMapId-Case.value()。这样在运行时,只要知道resultMap中包含了鉴别器之后,获取具体的鉴别器映射就很简单了,map.get()一下就得到了。
String caseResultMapId = resultMapId + "-" + c.value();
List<ResultMapping> resultMappings = new ArrayList<ResultMapping>();
// issue #136
applyConstructorArgs(c.constructArgs(), resultType, resultMappings);
applyResults(c.results(), resultType, resultMappings);
// TODO add AutoMappingBehaviour
assistant.addResultMap(caseResultMapId, c.type(), resultMapId, null, resultMappings, null);
}
}
}
private Discriminator applyDiscriminator(String resultMapId, Class<?> resultType, TypeDiscriminator discriminator) {
if (discriminator != null) {
String column = discriminator.column();
Class<?> javaType = discriminator.javaType() == void.class ? String.class : discriminator.javaType();
JdbcType jdbcType = discriminator.jdbcType() == JdbcType.UNDEFINED ? null : discriminator.jdbcType();
@SuppressWarnings("unchecked")
Class<? extends TypeHandler<?>> typeHandler = (Class<? extends TypeHandler<?>>)
(discriminator.typeHandler() == UnknownTypeHandler.class ? null : discriminator.typeHandler());
Case[] cases = discriminator.cases();
Map<String, String> discriminatorMap = new HashMap<String, String>();
for (Case c : cases) {
String value = c.value();
String caseResultMapId = resultMapId + "-" + value;
discriminatorMap.put(value, caseResultMapId);
}
return assistant.buildDiscriminator(resultType, column, javaType, jdbcType, typeHandler, discriminatorMap);
}
return null;
}5、二次解析pending的方法。
2.3 解析mapper文件XMLMapperBuilder
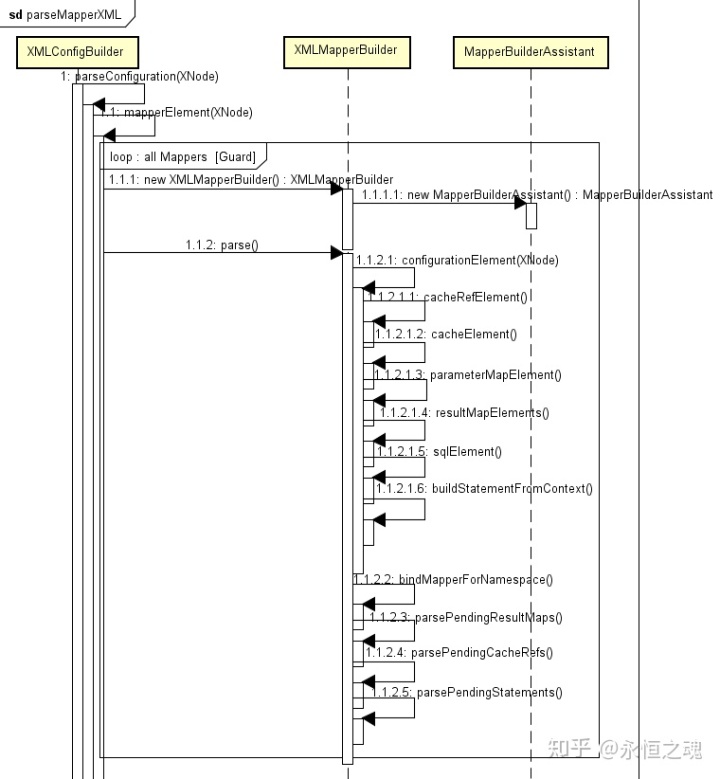
Mapper文件的解析主要由XMLMapperBuilder类完成,Mapper文件的加载流程如下:
我们以package扫描中的loadXmlResource()为入口开始。
private void loadXmlResource() {
// Spring may not know the real resource name so we check a flag
// to prevent loading again a resource twice
// this flag is set at XMLMapperBuilder#bindMapperForNamespace
if (!configuration.isResourceLoaded("namespace:" + type.getName())) {
String xmlResource = type.getName().replace('.', '/') + ".xml";
InputStream inputStream = null;
try {
inputStream = Resources.getResourceAsStream(type.getClassLoader(), xmlResource);
} catch (IOException e) {
// ignore, resource is not required
}
if (inputStream != null) {
XMLMapperBuilder xmlParser = new XMLMapperBuilder(inputStream, assistant.getConfiguration(), xmlResource, configuration.getSqlFragments(), type.getName());
xmlParser.parse();
}
}
}根据package自动搜索加载的时候,约定俗称从classpath下加载接口的完整名,比如org.mybatis.example.mapper.BlogMapper,就加载org/mybatis/example/mapper/BlogMapper.xml。对于从package和class进来的mapper,如果找不到对应的文件,就忽略,因为这种情况下是允许SQL语句作为注解打在接口上的,所以xml文件不是必须的,而对于直接声明的xml mapper文件,如果找不到的话会抛出IOException异常而终止,这在使用注解模式的时候需要注意。加载到对应的mapper.xml文件后,调用XMLMapperBuilder进行解析。在创建XMLMapperBuilder时,我们发现用到了configuration.getSqlFragments(),这就是我们在mapper文件中经常使用的可以被包含在其他语句中的SQL片段,但是我们并没有初始化过,所以很有可能它是在解析过程中动态添加的,创建了XMLMapperBuilder之后,在调用其parse()接口进行具体xml的解析,这和mybatis-config的逻辑基本上是一致的思路。再来看XMLMapperBuilder的初始化逻辑:
public XMLMapperBuilder(InputStream inputStream, Configuration configuration, String resource, Map<String, XNode> sqlFragments, String namespace) {
this(inputStream, configuration, resource, sqlFragments);
this.builderAssistant.setCurrentNamespace(namespace);
}
public XMLMapperBuilder(InputStream inputStream, Configuration configuration, String resource, Map<String, XNode> sqlFragments) {
this(new XPathParser(inputStream, true, configuration.getVariables(), new XMLMapperEntityResolver()),
configuration, resource, sqlFragments);
} 加载的基本逻辑和加载mybatis-config一样的过程,使用XPathParser进行总控,XMLMapperEntityResolver进行具体判断。
接下去来看XMLMapperBuilder.parse()的具体实现。
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
bindMapperForNamespace();
}
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}其中,解析mapper的核心又在configurationElement中,如下所示:
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}其主要过程是:
1、解析缓存参照cache-ref。参照缓存顾名思义,就是共用其他缓存的设置。
private void cacheRefElement(XNode context) {
if (context != null) {
configuration.addCacheRef(builderAssistant.getCurrentNamespace(), context.getStringAttribute("namespace"));
CacheRefResolver cacheRefResolver = new CacheRefResolver(builderAssistant, context.getStringAttribute("namespace"));
try {
cacheRefResolver.resolveCacheRef();
} catch (IncompleteElementException e) {
configuration.addIncompleteCacheRef(cacheRefResolver);
}
}
}
<cache-ref namespace=”com.someone.application.data.SomeMapper”/>缓存参考因为通过namespace指向其他的缓存。所以会出现第一次解析的时候指向的缓存还不存在的情况,所以需要在所有的mapper文件加载完成后进行二次处理,不仅仅是缓存参考,其他的CRUD也一样。所以在XMLMapperBuilder.configuration中有很多的incompleteXXX,这种设计模式类似于JVM GC中的mark and sweep,标记、然后处理。所以当捕获到IncompleteElementException异常时,没有终止执行,而是将指向的缓存不存在的cacheRefResolver添加到configuration.incompleteCacheRef中。
2、解析缓存cache
private void cacheElement(XNode context) throws Exception {
if (context != null) {
String type = context.getStringAttribute("type", "PERPETUAL");
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
boolean blocking = context.getBooleanAttribute("blocking", false);
Properties props = context.getChildrenAsProperties();
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}默认情况下,mybatis使用的是永久缓存PerpetualCache,读取或设置各个属性默认值之后,调用builderAssistant.useNewCache构建缓存,其中的CacheBuilder使用了build模式(在effective里面,建议有4个以上可选属性时,应该为对象提供一个builder便于使用),只要实现org.apache.ibatis.cache.Cache接口,就是合法的mybatis缓存。
我们先来看下缓存的DTD定义:
<!ELEMENT cache (property*)>
<!ATTLIST cache
type CDATA #IMPLIED
eviction CDATA #IMPLIED
flushInterval CDATA #IMPLIED
size CDATA #IMPLIED
readOnly CDATA #IMPLIED
blocking CDATA #IMPLIED
>所以,最简单的情况下只要声明就可以启用当前mapper下的缓存。
3、解析参数映射parameterMap
private void parameterMapElement(List<XNode> list) throws Exception {
for (XNode parameterMapNode : list) {
String id = parameterMapNode.getStringAttribute("id");
String type = parameterMapNode.getStringAttribute("type");
Class<?> parameterClass = resolveClass(type);
List<XNode> parameterNodes = parameterMapNode.evalNodes("parameter");
List<ParameterMapping> parameterMappings = new ArrayList<ParameterMapping>();
for (XNode parameterNode : parameterNodes) {
String property = parameterNode.getStringAttribute("property");
String javaType = parameterNode.getStringAttribute("javaType");
String jdbcType = parameterNode.getStringAttribute("jdbcType");
String resultMap = parameterNode.getStringAttribute("resultMap");
String mode = parameterNode.getStringAttribute("mode");
String typeHandler = parameterNode.getStringAttribute("typeHandler");
Integer numericScale = parameterNode.getIntAttribute("numericScale");
ParameterMode modeEnum = resolveParameterMode(mode);
Class<?> javaTypeClass = resolveClass(javaType);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
@SuppressWarnings("unchecked")
Class<? extends TypeHandler<?>> typeHandlerClass = (Class<? extends TypeHandler<?>>) resolveClass(typeHandler);
ParameterMapping parameterMapping = builderAssistant.buildParameterMapping(parameterClass, property, javaTypeClass, jdbcTypeEnum, resultMap, modeEnum, typeHandlerClass, numericScale);
parameterMappings.add(parameterMapping);
}
builderAssistant.addParameterMap(id, parameterClass, parameterMappings);
}
}
<!ELEMENT parameterMap (parameter+)?>
<!ATTLIST parameterMap
id CDATA #REQUIRED
type CDATA #REQUIRED
>
<!ELEMENT parameter EMPTY>
<!ATTLIST parameter
property CDATA #REQUIRED
javaType CDATA #IMPLIED
jdbcType CDATA #IMPLIED
mode (IN | OUT | INOUT) #IMPLIED
resultMap CDATA #IMPLIED
scale CDATA #IMPLIED
typeHandler CDATA #IMPLIED
>总体来说,目前已经不推荐使用参数映射,而是直接使用内联参数。所以我们这里就不展开细讲了。如有必要,我们后续会补上。
4、解析结果集映射resultMap
结果集映射早期版本可以说是用的最多的辅助节点了,不过有了mapUnderscoreToCamelCase属性之后,如果命名规范控制做的好的话,resultMap也是可以省略的。每个mapper文件可以有多个结果集映射。最终来说,它还是使用频率很高的。我们先来看下DTD定义:
<!ELEMENT resultMap (constructor?,id*,result*,association*,collection*, discriminator?)>
<!ATTLIST resultMap
id CDATA #REQUIRED
type CDATA #REQUIRED
extends CDATA #IMPLIED
autoMapping (true|false) #IMPLIED
>
<!ELEMENT constructor (idArg*,arg*)>
<!ELEMENT id EMPTY>
<!ATTLIST id
property CDATA #IMPLIED
javaType CDATA #IMPLIED
column CDATA #IMPLIED
jdbcType CDATA #IMPLIED
typeHandler CDATA #IMPLIED
>
<!ELEMENT result EMPTY>
<!ATTLIST result
property CDATA #IMPLIED
javaType CDATA #IMPLIED
column CDATA #IMPLIED
jdbcType CDATA #IMPLIED
typeHandler CDATA #IMPLIED
>
<!ELEMENT idArg EMPTY>
<!ATTLIST idArg
javaType CDATA #IMPLIED
column CDATA #IMPLIED
jdbcType CDATA #IMPLIED
typeHandler CDATA #IMPLIED
select CDATA #IMPLIED
resultMap CDATA #IMPLIED
name CDATA #IMPLIED
>
<!ELEMENT arg EMPTY>
<!ATTLIST arg
javaType CDATA #IMPLIED
column CDATA #IMPLIED
jdbcType CDATA #IMPLIED
typeHandler CDATA #IMPLIED
select CDATA #IMPLIED
resultMap CDATA #IMPLIED
name CDATA #IMPLIED
>
<!ELEMENT collection (constructor?,id*,result*,association*,collection*, discriminator?)>
<!ATTLIST collection
property CDATA #REQUIRED
column CDATA #IMPLIED
javaType CDATA #IMPLIED
ofType CDATA #IMPLIED
jdbcType CDATA #IMPLIED
select CDATA #IMPLIED
resultMap CDATA #IMPLIED
typeHandler CDATA #IMPLIED
notNullColumn CDATA #IMPLIED
columnPrefix CDATA #IMPLIED
resultSet CDATA #IMPLIED
foreignColumn CDATA #IMPLIED
autoMapping (true|false) #IMPLIED
fetchType (lazy|eager) #IMPLIED
>
<!ELEMENT association (constructor?,id*,result*,association*,collection*, discriminator?)>
<!ATTLIST association
property CDATA #REQUIRED
column CDATA #IMPLIED
javaType CDATA #IMPLIED
jdbcType CDATA #IMPLIED
select CDATA #IMPLIED
resultMap CDATA #IMPLIED
typeHandler CDATA #IMPLIED
notNullColumn CDATA #IMPLIED
columnPrefix CDATA #IMPLIED
resultSet CDATA #IMPLIED
foreignColumn CDATA #IMPLIED
autoMapping (true|false) #IMPLIED
fetchType (lazy|eager) #IMPLIED
>
<!ELEMENT discriminator (case+)>
<!ATTLIST discriminator
column CDATA #IMPLIED
javaType CDATA #REQUIRED
jdbcType CDATA #IMPLIED
typeHandler CDATA #IMPLIED
>
<!ELEMENT case (constructor?,id*,result*,association*,collection*, discriminator?)>
<!ATTLIST case
value CDATA #REQUIRED
resultMap CDATA #IMPLIED
resultType CDATA #IMPLIED
>从DTD的复杂程度就可知,resultMap相当于前面的cache/parameterMap等来说,是相当灵活的。下面我们来看resultMap在运行时到底是如何表示的。
private void resultMapElements(List<XNode> list) throws Exception {
for (XNode resultMapNode : list) {
try {
resultMapElement(resultMapNode);
} catch (IncompleteElementException e) {
// ignore, it will be retried
// 在内部实现中将未完成的元素添加到configuration.incomplete中了
}
}
}
private ResultMap resultMapElement(XNode resultMapNode) throws Exception {
return resultMapElement(resultMapNode, Collections.<ResultMapping> emptyList());
}
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings) throws Exception {
ErrorContext.instance().activity("processing " + resultMapNode.getValueBasedIdentifier());
String id = resultMapNode.getStringAttribute("id",
resultMapNode.getValueBasedIdentifier());
String type = resultMapNode.getStringAttribute("type",
resultMapNode.getStringAttribute("ofType",
resultMapNode.getStringAttribute("resultType",
resultMapNode.getStringAttribute("javaType"))));
String extend = resultMapNode.getStringAttribute("extends");
Boolean autoMapping = resultMapNode.getBooleanAttribute("autoMapping");
Class<?> typeClass = resolveClass(type);
Discriminator discriminator = null;
List<ResultMapping> resultMappings = new ArrayList<ResultMapping>();
resultMappings.addAll(additionalResultMappings);
List<XNode> resultChildren = resultMapNode.getChildren();
for (XNode resultChild : resultChildren) {
if ("constructor".equals(resultChild.getName())) {
processConstructorElement(resultChild, typeClass, resultMappings);
} else if ("discriminator".equals(resultChild.getName())) {
discriminator = processDiscriminatorElement(resultChild, typeClass, resultMappings);
} else {
List<ResultFlag> flags = new ArrayList<ResultFlag>();
if ("id".equals(resultChild.getName())) {
flags.add(ResultFlag.ID);
}
resultMappings.add(buildResultMappingFromContext(resultChild, typeClass, flags));
}
}
ResultMapResolver resultMapResolver = new ResultMapResolver(builderAssistant, id, typeClass, extend, discriminator, resultMappings, autoMapping);
try {
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
}
private void processConstructorElement(XNode resultChild, Class<?> resultType, List<ResultMapping> resultMappings) throws Exception {
List<XNode> argChildren = resultChild.getChildren();
for (XNode argChild : argChildren) {
List<ResultFlag> flags = new ArrayList<ResultFlag>();
flags.add(ResultFlag.CONSTRUCTOR);
if ("idArg".equals(argChild.getName())) {
flags.add(ResultFlag.ID);
}
resultMappings.add(buildResultMappingFromContext(argChild, resultType, flags));
}
}
private Discriminator processDiscriminatorElement(XNode context, Class<?> resultType, List<ResultMapping> resultMappings) throws Exception {
String column = context.getStringAttribute("column");
String javaType = context.getStringAttribute("javaType");
String jdbcType = context.getStringAttribute("jdbcType");
String typeHandler = context.getStringAttribute("typeHandler");
Class<?> javaTypeClass = resolveClass(javaType);
@SuppressWarnings("unchecked")
Class<? extends TypeHandler<?>> typeHandlerClass = (Class<? extends TypeHandler<?>>) resolveClass(typeHandler);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
Map<String, String> discriminatorMap = new HashMap<String, String>();
for (XNode caseChild : context.getChildren()) {
String value = caseChild.getStringAttribute("value");
String resultMap = caseChild.getStringAttribute("resultMap", processNestedResultMappings(caseChild, resultMappings));
discriminatorMap.put(value, resultMap);
}
return builderAssistant.buildDiscriminator(resultType, column, javaTypeClass, jdbcTypeEnum, typeHandlerClass, discriminatorMap);
}我们先来看下ResultMapping的定义:
public class ResultMapping {
private Configuration configuration;
private String property;
private String column;
private Class<?> javaType;
private JdbcType jdbcType;
private TypeHandler<?> typeHandler;
private String nestedResultMapId;
private String nestedQueryId;
private Set<String> notNullColumns;
private String columnPrefix;
private List<ResultFlag> flags;
private List<ResultMapping> composites;
private String resultSet;
private String foreignColumn;
private boolean lazy;
...
}所有下的最底层子元素比如、、等本质上都属于一个映射,只不过有着额外的标记比如是否嵌套,是否构造器等。
总体逻辑是先解析resultMap节点本身,然后解析子节点构造器,鉴别器discriminator,id。最后组装成真正的resultMappings。我们先来看个实际的复杂resultMap例子,便于我们更好的理解代码的逻辑:
<resultMap id="detailedBlogResultMap" type="Blog">
<constructor>
<idArg column="blog_id" javaType="int"/>
<arg column="blog_name" javaType="string"/>
</constructor>
<result property="title" column="blog_title"/>
<association property="author" javaType="Author">
<id property="id" column="author_id"/>
<result property="username" column="author_username"/>
<result property="password" column="author_password"/>
<result property="email" column="author_email"/>
<result property="bio" column="author_bio"/>
<result property="favouriteSection" column="author_favourite_section"/>
</association>
<collection property="posts" ofType="Post">
<id property="id" column="post_id"/>
<result property="subject" column="post_subject"/>
<association property="author" javaType="Author"/>
<collection property="comments" ofType="Comment">
<id property="id" column="comment_id"/>
</collection>
<collection property="tags" ofType="Tag" >
<id property="id" column="tag_id"/>
</collection>
<discriminator javaType="int" column="draft">
<case value="1" resultType="DraftPost"/>
</discriminator>
</collection>
</resultMap>resultMap里面可以包含多种子节点,每个节点都有具体的方法进行解析,这也体现了单一职责原则。在resultMapElement中,主要是解析resultMap节点本身并循环遍历委托给具体的方法处理。下面来看构造器的解析。构造器主要用于没有默认构造器或者有多个构造器的情况,比如:
public class User {
//...
public User(Integer id, String username, int age) {
//...
}
//...
}就可以使用下列的构造器设置属性值,比如:
<constructor>
<idArg column="id" javaType="int"/>
<arg column="username" javaType="String"/>
<arg column="age" javaType="_int"/>
</constructor>遍历构造器元素很简单:
private void processConstructorElement(XNode resultChild, Class<?> resultType, List<ResultMapping> resultMappings) throws Exception {
List<XNode> argChildren = resultChild.getChildren();
for (XNode argChild : argChildren) {
List<ResultFlag> flags = new ArrayList<ResultFlag>();
flags.add(ResultFlag.CONSTRUCTOR);
if ("idArg".equals(argChild.getName())) {
flags.add(ResultFlag.ID);
}
resultMappings.add(buildResultMappingFromContext(argChild, resultType, flags));
}
}构造器的解析比较简单,除了遍历构造参数外,还可以构造器参数的ID也识别出来。最后调用buildResultMappingFromContext建立具体的resultMap。buildResultMappingFromContext是个公共工具方法,会被反复使用,我们来看下它的具体实现(不是所有元素都包含所有属性):
private ResultMapping buildResultMappingFromContext(XNode context, Class<?> resultType, List<ResultFlag> flags) throws Exception {
String property;
if (flags.contains(ResultFlag.CONSTRUCTOR)) {
property = context.getStringAttribute("name");
} else {
property = context.getStringAttribute("property");
}
String column = context.getStringAttribute("column");
String javaType = context.getStringAttribute("javaType");
String jdbcType = context.getStringAttribute("jdbcType");
String nestedSelect = context.getStringAttribute("select");
// resultMap中可以包含association或collection复合类型,这些复合类型可以使用外部定义的公用resultMap或者内嵌resultMap, 所以这里的处理逻辑是如果有resultMap就获取resultMap,如果没有,那就动态生成一个。如果自动生成的话,他的resultMap id通过调用XNode.getValueBasedIdentifier()来获得
String nestedResultMap = context.getStringAttribute("resultMap",
processNestedResultMappings(context, Collections.<ResultMapping> emptyList()));
String notNullColumn = context.getStringAttribute("notNullColumn");
String columnPrefix = context.getStringAttribute("columnPrefix");
String typeHandler = context.getStringAttribute("typeHandler");
String resultSet = context.getStringAttribute("resultSet");
String foreignColumn = context.getStringAttribute("foreignColumn");
boolean lazy = "lazy".equals(context.getStringAttribute("fetchType", configuration.isLazyLoadingEnabled() ? "lazy" : "eager"));
Class<?> javaTypeClass = resolveClass(javaType);
@SuppressWarnings("unchecked")
Class<? extends TypeHandler<?>> typeHandlerClass = (Class<? extends TypeHandler<?>>) resolveClass(typeHandler);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
return builderAssistant.buildResultMapping(resultType, property, column, javaTypeClass, jdbcTypeEnum, nestedSelect, nestedResultMap, notNullColumn, columnPrefix, typeHandlerClass, flags, resultSet, foreignColumn, lazy);
}上述过程主要用于获取各个属性,其中唯一值得注意的是processNestedResultMappings,它用于解析包含的association或collection复合类型,这些复合类型可以使用外部定义的公用resultMap或者内嵌resultMap, 所以这里的处理逻辑是如果是外部resultMap就获取对应resultMap的名称,如果没有,那就动态生成一个。如果自动生成的话,其resultMap id通过调用XNode.getValueBasedIdentifier()来获得。由于colletion和association、discriminator里面还可以包含复合类型,所以将进行递归解析直到所有的子元素都为基本列位置,它在使用层面的目的在于将关系模型映射为对象树模型。例如:
<resultMap id="blogResult" type="Blog">
<id property="id" column="blog_id" />
<result property="title" column="blog_title"/>
<association property="author" column="blog_author_id" javaType="Author" resultMap="authorResult"/>
<collection property="posts" javaType="ArrayList" column="id" ofType="Post" select="selectPostsForBlog"/>
</resultMap>注意“ofType”属性,这个属性用来区分JavaBean(或字段)属性类型和集合中存储的对象类型。
private String processNestedResultMappings(XNode context, List<ResultMapping> resultMappings) throws Exception {
if ("association".equals(context.getName())
|| "collection".equals(context.getName())
|| "case".equals(context.getName())) {
if (context.getStringAttribute("select") == null) {
ResultMap resultMap = resultMapElement(context, resultMappings);
return resultMap.getId();
}
}
return null;
}对于其中的每个非select属性映射,调用resultMapElement进行递归解析。其中的case节点主要用于鉴别器情况,后面我们会细讲。
注:select的用途在于指定另外一个映射语句的ID,加载这个属性映射需要的复杂类型。在列属性中指定的列的值将被传递给目标 select 语句作为参数。在上面的例子中,id的值会作为selectPostsForBlog的参数,这个语句会为每条映射到blogResult的记录执行一次selectPostsForBlog,并将返回的值添加到blog.posts属性中,其类型为Post。
得到各属性之后,调用builderAssistant.buildResultMapping最后创建ResultMap。其中除了 javaType,column外,其他都是可选的,property也就是中的name属性或者中的property属性,主要用于根据@Param或者jdk 8 -parameters形参名而非依赖声明顺序进行映射。
public ResultMapping buildResultMapping(
Class<?> resultType,
String property,
String column,
Class<?> javaType,
JdbcType jdbcType,
String nestedSelect,
String nestedResultMap,
String notNullColumn,
String columnPrefix,
Class<? extends TypeHandler<?>> typeHandler,
List<ResultFlag> flags,
String resultSet,
String foreignColumn,
boolean lazy) {
Class<?> javaTypeClass = resolveResultJavaType(resultType, property, javaType);
TypeHandler<?> typeHandlerInstance = resolveTypeHandler(javaTypeClass, typeHandler);
List<ResultMapping> composites = parseCompositeColumnName(column);
return new ResultMapping.Builder(configuration, property, column, javaTypeClass)
.jdbcType(jdbcType)
.nestedQueryId(applyCurrentNamespace(nestedSelect, true))
.nestedResultMapId(applyCurrentNamespace(nestedResultMap, true))
.resultSet(resultSet)
.typeHandler(typeHandlerInstance)
.flags(flags == null ? new ArrayList<ResultFlag>() : flags)
.composites(composites)
.notNullColumns(parseMultipleColumnNames(notNullColumn))
.columnPrefix(columnPrefix)
.foreignColumn(foreignColumn)
.lazy(lazy)
.build();
}在实际使用中,一般不会在构造器中包含association和collection。















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









