






git地址: https://github.com/aox-lei/scrapy-rabbitmq-scheduler
一、安装
pip install scrapy-rabbitmq-scheduler
二、初始化scrapy项目
scrapy startproject example
三、配置调度器以及下载器
在项目的settings.py中增加以下配置项
# 指定配置器
SCHEDULER = "scrapy_rabbitmq_scheduler.scheduler.SaaS"
# 指定rabbitmq服务的地址
RABBITMQ_CONNECTION_PARAMETERS = 'amqp://guest:guest@localhost:5672/?heartbeat=0'
# 指定重新加回队列的http状态码
SCHEDULER_REQUEUE_ON_STATUS = [500]
# 指定下载器处理
DOWNLOADER_MIDDLEWARES = {
'scrapy_rabbitmq_scheduler.middleware.RabbitMQMiddleware': 999
}
# 指定item处理, 将item推送到rabbitmq中
ITEM_PIPELINES = {
'scrapy_rabbitmq_scheduler.pipelines.RabbitmqPipeline': 300,
}
四、编写爬虫代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy_rabbitmq_scheduler.spiders import RabbitSpider
from example.items import ArticleItem
class CcidcomSpider(RabbitSpider):
name = 'ccidcom'
allowed_domains = ['ccidcom.com']
start_urls = ['http://www.ccidcom.com/']
# 队列名称
queue_name = 'ccidcom'
# item队列名称
items_key = 'item_ccidcom'
def parse(self, response):
navigation_list = response.css(
'#nav > div.nav-main.clearfix > ul > li > div > a::attr("href")')
for _link in navigation_list:
yield response.follow(_link,
dont_filter=True,
callback=self.parse_list)
def parse_list(self, response):
article_list = response.css('div.article-item')
for info in article_list:
item = ArticleItem()
item['title'] = info.css('div.title a>font::text').get()
item['url'] = info.css('div.title a::attr("href")').get()
yield item
五、运行代码
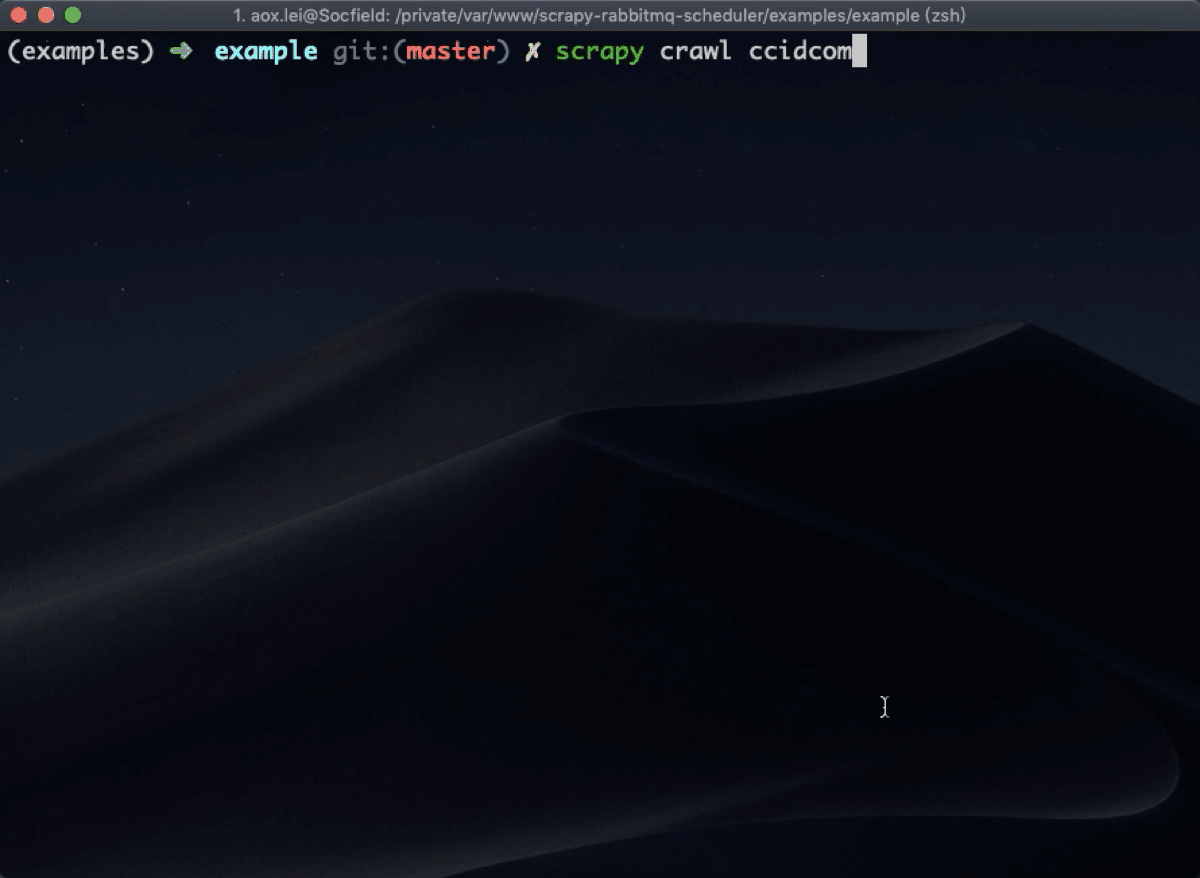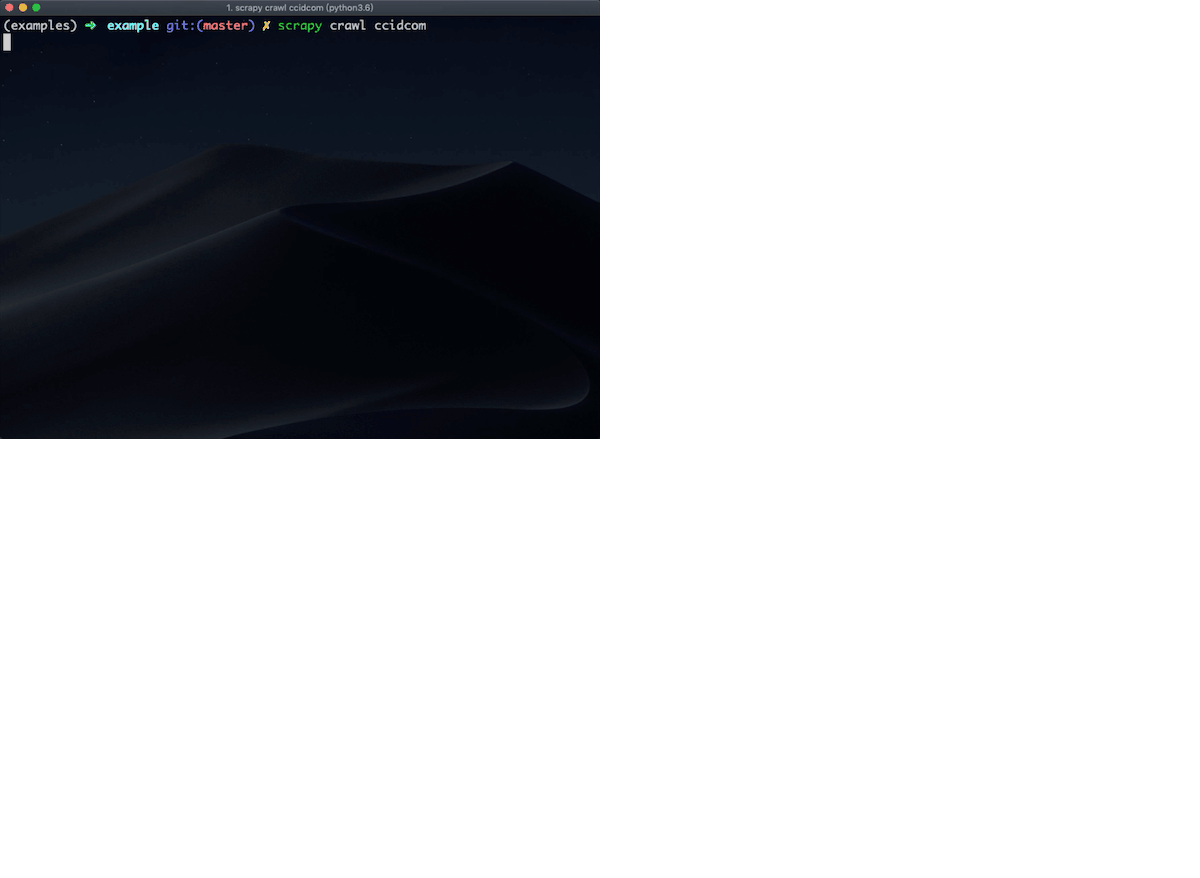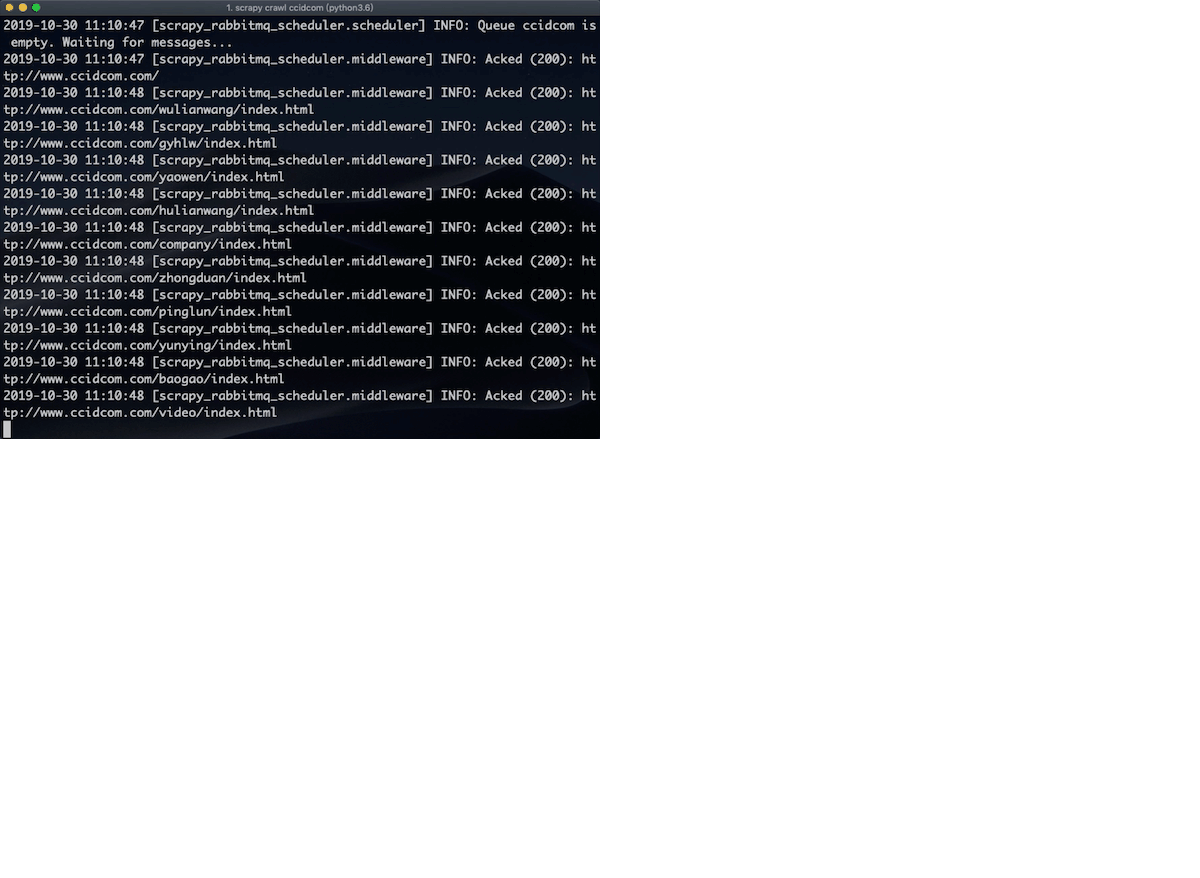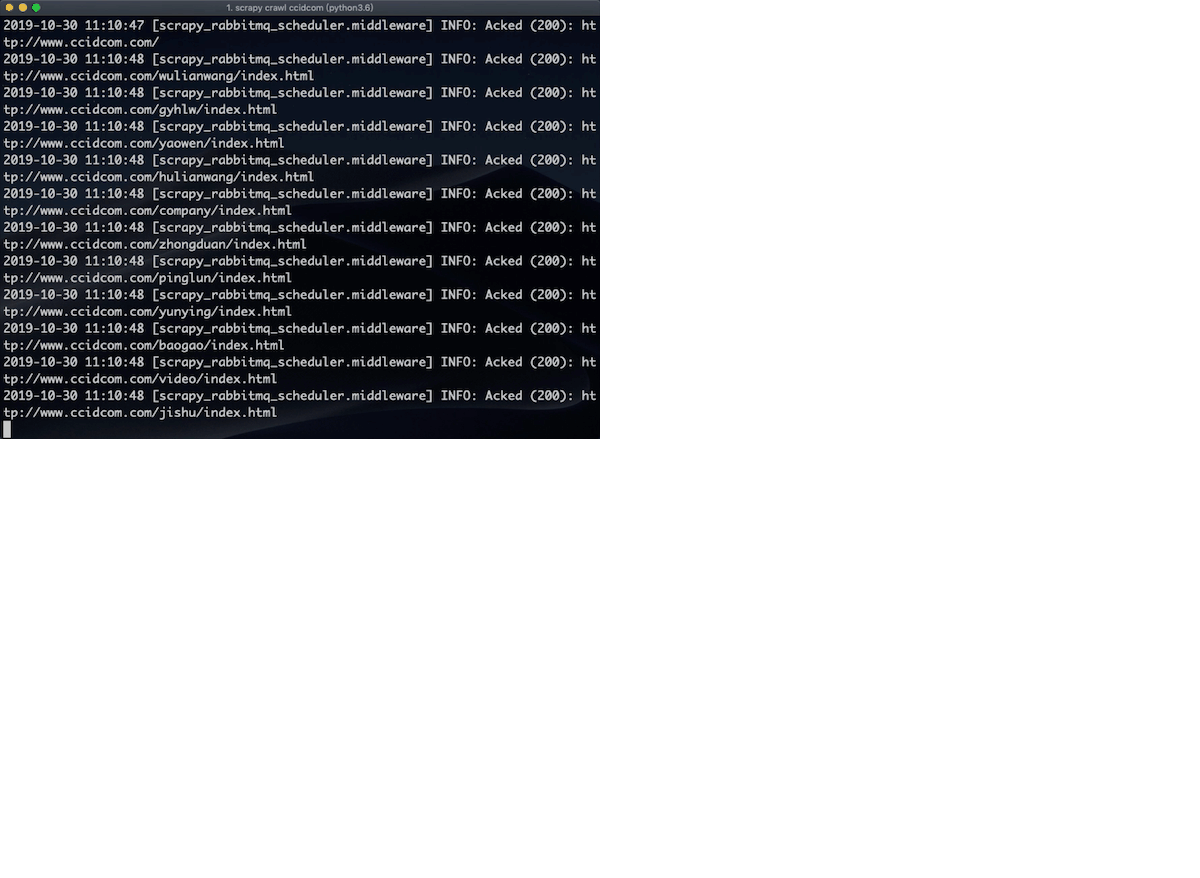
scrapy crawl ccidcom
欢迎关注微信公众号:Python开发之路(微信号: python-developer)














 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









