







一.Scrapy爬虫框架介绍
Scrapy是功能强大的非常快速的网络爬虫框架,是非常重要的python第三方库。scrapy不是一个函数功能库,而是一个爬虫框架。
1.1 Scrapy库的安装
pip install scrapy -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
安装后小测: scrapy -h
环境具体搭建
pip install wheel -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com 下载twisted 网址:下载对应版本https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 需要将下载好的文件放在要安装的目录下 pip install Twisted-20.3.0-cp37-cp37m-win_amd64.whl -i http://mirrors.aliyun.com/pypi/si mple/ --trusted-host mirrors.aliyun.com pip install pywin32 -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.ali yun.com pip install scrapy -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
1.2 爬虫框架
爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫。
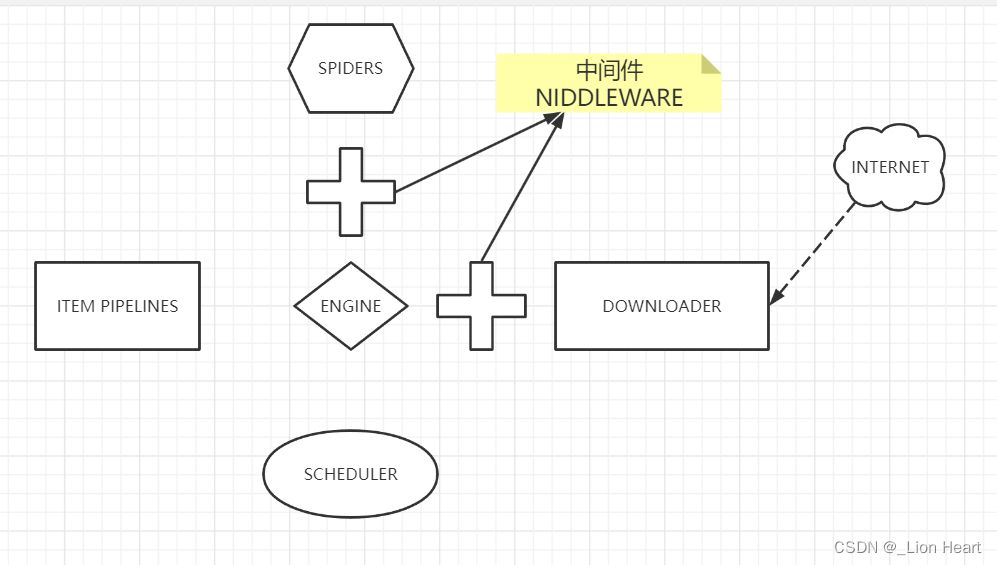
1.3 Scrapy结构
功能:高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式
Scrapy包含七个部分,称为“5+2”结构,五个部分是框架的主体部分,另外包含两个中间件。
引擎;
用来处理整个系统的数据流处理,触发事务(框架核心)
调度器:
用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回,可以想象成一个URL(抓取网页的网址或者是链接)的优先队列,由它来决定下一个要抓取的网址是什么,同时去掉重复的网址
下载器:
用来下载网页内容,并将网页内容返回给spider(Scrapy下载器是建立在twisted)这个高效的异步模型上的
爬虫:
爬虫主要是干活的,用于从特定的网页中提取自己需要的信息,即所谓的实体(item),用户也可以从中提取链接让Scrapy继续抓取下一个页面
项目管道:
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息,当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
1.3 Scrapy框架包含三条主要的数据流路径
1.SPIDERS->ENGINE->SCHEDULER 2.SCHEDULER->ENGINE->DOWNLOADER->ENGINE->SPIDERS 3.SPIDERS->ENGINE->ITEM PIPELINES |SPIDERS->ENGINE->SCHEDULER
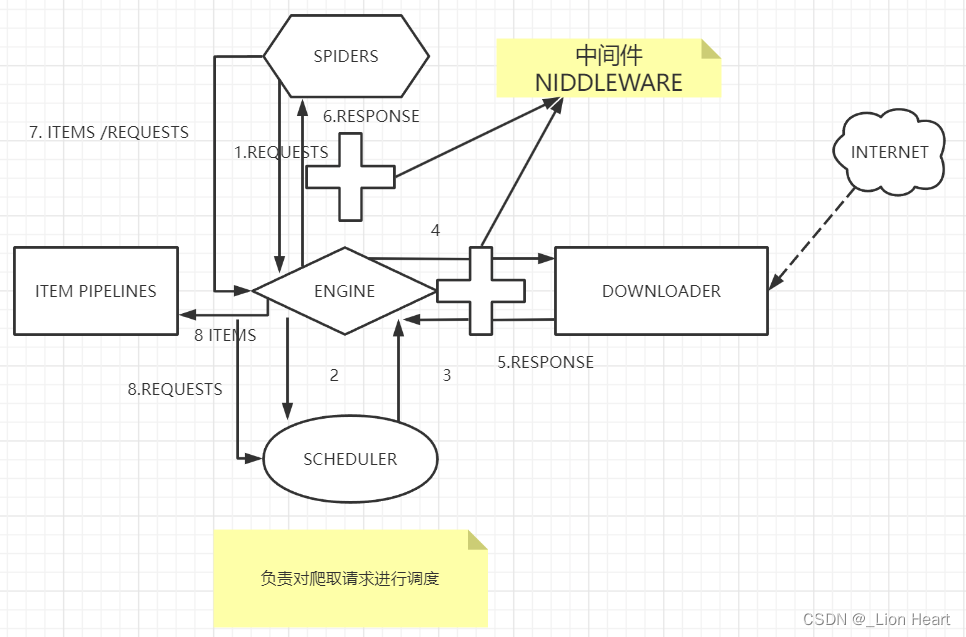
ENDINE:控制各个模块的数据流 SPIDERS:是入口 ITEM PIPELINES:是出口 ENDINE、DOWNLOADER、SCHEDULER已有实现 SPIDERS、ITEM PIPELINES需要用户编写 SPIDERS模块用来向整个框架提供要访问的url链接,同时要解析从网络上获得的页面的内容 ITEM PIPELINES对提取的信息进行后处理 用框架也叫做配置
1.4 Scrapy爬虫框架解析
Engine:(框架的核心)(不需要用户修改) 1.控制所有模块之间的数据流 2.根据条件除法事件 Downloader(不需要用户修改) 根据请求下载网页 Scheduler(不需要用户修改) 对所有爬取请求进行调度管理 中间件:Downloader Middleware(用户可以编写配置代码) 目的:实施Engine、Scheduler和Downloader之间进行用户可配置的控制 功能:修改、丢弃、新增请求或响应 Spider(需要用户编写配置代码) 1.解析Downloader返回的响应(Response) 2.产生爬取项(scraped item) 3.产生额外的爬取请求(Requset) 向框架提供了最开始的访问链接,同时对每次爬取回来的内容进行解析,产生再次产生新的爬取请求,并且从内容中分析出提取出相关的数据 Item Pipelines(需要用户编写配置代码)(数据清洗或者存储到数据库) 1.以流水线方式处理Spider产生的爬取项 2.由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型 可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库 Spider Middleware(用户可以编写配置代码) 目的:对请求和爬取项的再处理 功能:修改、丢弃、新增请求或爬取项
1.5 requests库和Scrapy爬虫的比较
requests vs Scrapy 相同点 两者都可以进行 页面请求和爬取,Python爬虫的两个重要技术路线 两者可用性都好,文档丰富,入门简单。 两者都没有处理js、提交表单、应对验证码等功能(可扩展)。
| requests | Scrapy |
|---|---|
| 页面级爬虫 | 网站级爬虫 |
| 功能库 | 框架 |
| 并发性考虑不足,性能较差 | 并发性好,性能较高 |
| 重点在于页面下载 | 重点在于爬虫结构 |
| 定制灵活 | 一般定制灵活,深度定制困难 |
| 上手十分简单 | 入门稍难 |
选用哪个技术路线开发爬虫
非常小的需求,requess库
不太小的需求,Scrapy框架
定制程度很高的需求(不考虑规模),自搭框架,requests>Scrapy
1.6 Scrapy 爬虫的常用命令
Scrapy命令行
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行。
Scrapy命令行格式
scrapy<command>options
Scrapy常用命令
| 命令 | 说明 | 格式 |
|---|---|---|
| startproject | 创建一个新工程 | scrapy startproject 工程名 |
| genspider | 创建一个爬虫 | scrapy genspider 爬虫名称 起始的url |
| settings | 获得爬虫配置信息 | scrapy settings [ options] |
| crawl | 运行一个爬虫 | scrapy crawl 爬虫名称/scrapy crawl 爬虫名 --nolog ---去掉日记 |
| list | 列出工程中所有爬虫 | scrapy list |
| shell | 启动URL调试命令行 | scrapy shell [url] |
在settings文件中配置
#显示指定类型的日志信息 LOG_LEVEL='ERROR' 将日志文件简化
二.Scrapy基本使用
2.1 Scrapy 爬虫的第一个实例
产生步骤
步骤1.建立一个Scrapy爬虫工程
scrapy startproject python123demo
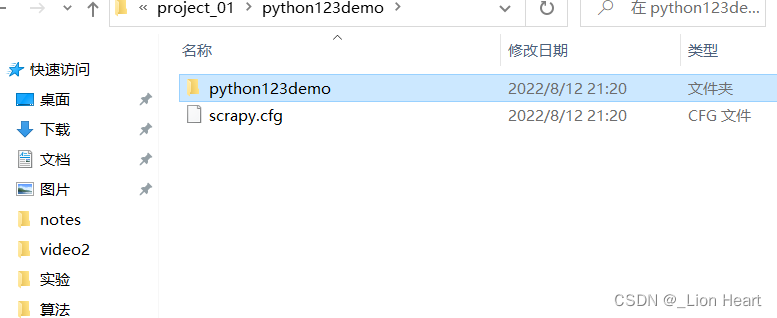
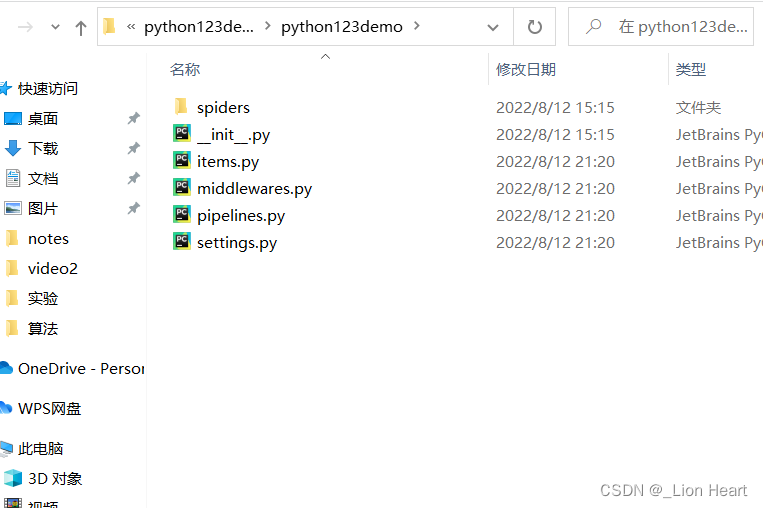
生成的工程目录
python123demo/ ---->外层目录
scrapy.cfg ---->部署Scrapy爬虫的配置文件
部署的概念是指将这样的爬虫放在特定的服务器上,并在服务器配置好相关的操作接口(本机部署不需要改变配置文件)
python123demo/-->Scrapy框架的用户自定义Python代码
__init__.py ---->初始化脚本 不需要编写代码
items.py ------>Items代码模块(继承类) 不需要编写代码
middlewares.py --->Middlewares代码模块(继承类)
pipelines.py ---->Pipelines代码模块(继承类)
setting.py ----->Scrapy爬虫的配置文件
spiders/ ------->Spiders代码模块目录(继承类)存放着爬虫
spiders/ -------->Spiders代码模块目录(继承类)
__init__.py ---->初始文件,无需修改
__pycache__/---->缓存目录,无需修改
步骤2:再工程中产生一个Scrapy爬虫
cd python123demo scrapy genspider demo python123.io
生成demo.py文件
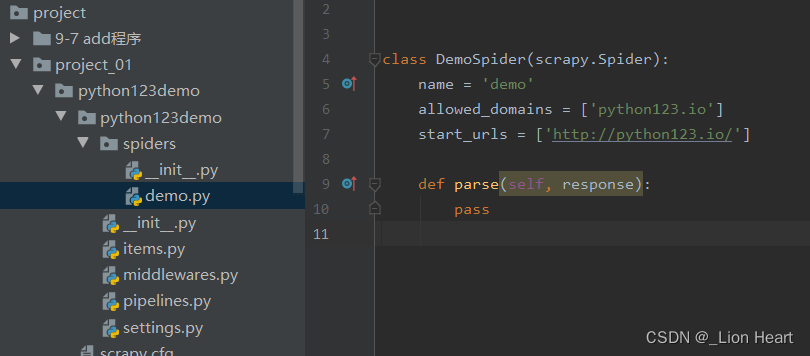
parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求。
步骤3:配置产生的spider爬虫(修改demo.py文件)
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['python123.io']
start_urls = ['https://python123.io/ws/demo.html']
def parse(self, response):
filename=response.url.split('/')[-1]
with open(filename,'w') as fp:
fp.write(response.body)
self.log('Saved file %s.' % filename)
步骤4:运行爬虫,获取网页
命令行下:scrapy crawl demo
步骤3的等价写法
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['python123.io']
# start_urls = ['https://python123.io/ws/demo.html']
def start_requests(self):
urls=[
'https://python123.io/ws/demo.html'
]
for url in urls:
yield scrapy.Request(url=url,callback=self.parse())
def parse(self, response):
filename=response.url.split('/')[-1]
with open(filename,'wb') as fp:
fp.write(response.body)
self.log('Saved file %s.' % filename)
2.2 yield关键字的使用
yield <-----> 生成器 生成器是一个不断产生值的函数 包含yield语句的函数是一个生成器 生成器每次产生一个值(yield语句),函数被冻结,被唤醒后再产生
生成器写法及使用
def gen(n): for i in range(n): yield i**2 for i in gen(5): print(i," ",end='')
普通写法
def square(n): ls=[i**2 for i in range(n)] return ls for i in square(5): print(i," ",end='')

生成器相比一次列出所有内容的优势
1.更节省存储空间
2.响应更迅速
3.使用更灵活
2.3 Scrapy爬虫的基本使用
2.3.1 Scrapy爬虫的使用步骤
步骤1:创建一个工程和Spider模板
步骤2:编写Spider
步骤3;编写Item Pipeline
步骤4:优化配置策略
2.4.2 Scrapy爬虫的数据类型
Request类 Response类 Item类
2.4.3 Request类
Request对象表示一个HTTP请求
由Spider生成,由Downloader执行
| 属性或方法 | 说明 |
|---|---|
| .url | Request对应的请求URL地址 |
| .method | 对应的请求方法,‘GET’ 'POST' |
| .headers | 字典类型风格的请求头 |
| .body | 请求内容主体,字符串类型 |
| .meta | 用户添加的扩展信息,在Scrapy内部模块间传递信息使用 |
| .copy | 复制该请求 |
2.4.4 Response类
Response对象表示一个HTTP响应。
由Downloader生成,由Spider处理。
| 属性或方法 | 说明 |
|---|---|
| .url | Response对应的URL地址 |
| .status | HTTP状态码,默认是200 |
| .headers | Response对应的头部信息 |
| .body | Response对应的内容信息,字符串类型 |
| .flags | 一组标记 |
| .request | 产生Response类型对应的Requset对象 |
| .copy | 复制该响应 |
2.4.5 Item类
Item对象表示一个从HTML页面中提取的信息内容。
由Spider生成,由Item Pipeline处理
Item类似字典类型,可以按照字典类型操作
2.4.6 爬虫提取信息的方法
Scrapy爬虫支持多种HTML信息提取方法
Beautiful Soup
lxml
re
XPath Selector
CSS Selector:例子 < HTML >.css('a::attr(href)').extract()
三.Scrapy 实例
3.1 Scrapy数据解析
抓取题目和正文
步骤1:scrapy startproject fjnu
cd fjnu
步骤2:scrapy genspideer fjnuspider www.xxx.com
步骤3:settings设置
ROBOTSTXT_OBEY = False
LOG_LEVEL='ERROR'
步骤4:编写spider代码
import scrapy
class FjnuspiderSpider(scrapy.Spider):
name = 'fjnuspider'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.fjnu.edu.cn/11/4a/c13a332106/page.htm']
def parse(self, response):
#解析题目和正文
#xpath返回的是列表,但是列表元素一定Selector类型的对象
#extract可以将Selector对象中的data参数存储的字符串提取出来
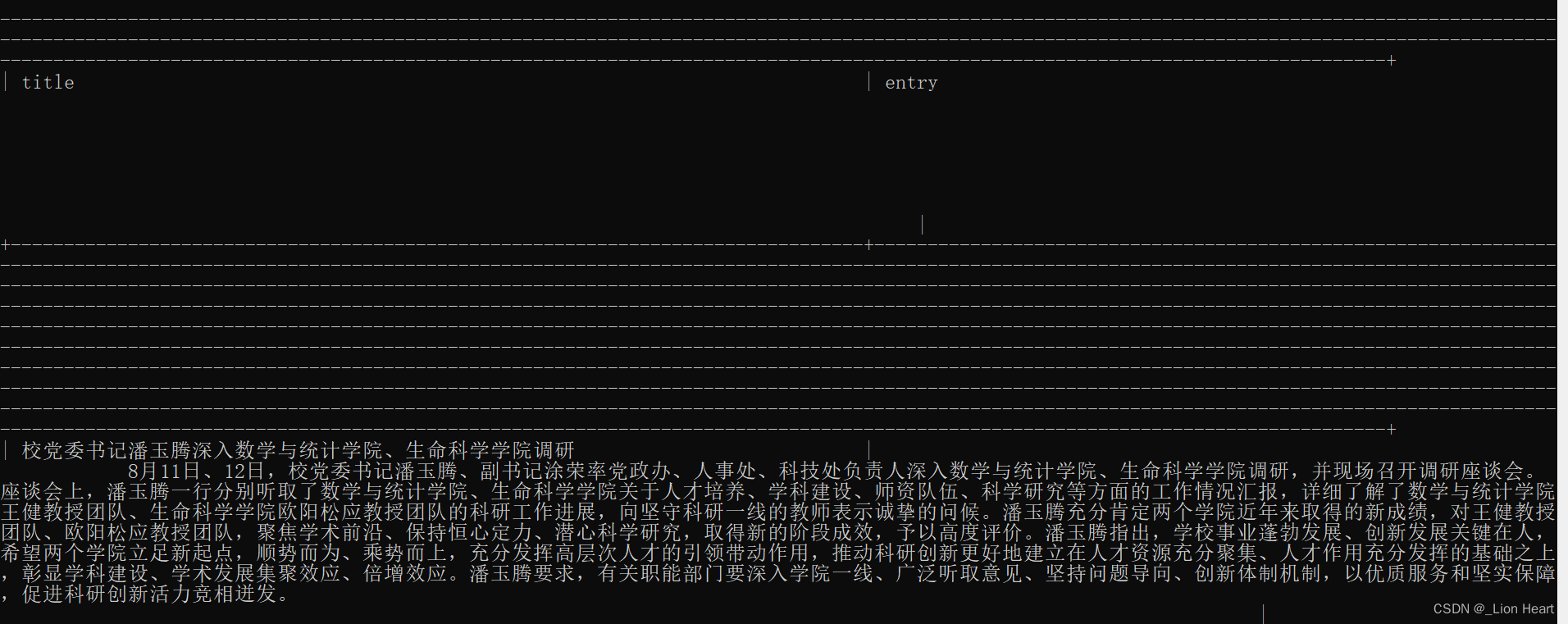
title=response.xpath('/html/body/div[3]/div/div[2]/div/h1/text()')[0].extract()
#列表调用了extract之后,则表示将列表中每一个Selector对象中data对应的字符串提取出来
entry=response.xpath('/html/body/div[3]/div/div[2]/div/div[2]//text()').extract()
entry=''.join(entry)
print(title)
print(entry)
步骤5:scrapy crawl fjnuspideer
3.2 基于终端指令的持久化存储
方式:
基于终端指令:
要求;只可以将parse方法返回值存储到本地的文本文件中
持久化存储对应的文本文件的类型只可以为'json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle'
代码:
spider代码:
import scrapy
class FjnuspiderSpider(scrapy.Spider):
name = 'fjnuspider'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.fjnu.edu.cn/11/4a/c13a332106/page.htm']
def parse(self, response):
#解析题目和正文
#xpath返回的是列表,但是列表元素一定Selector类型的对象
#extract可以将Selector对象中的data参数存储的字符串提取出来
title=response.xpath('/html/body/div[3]/div/div[2]/div/h1/text()')[0].extract()
#列表调用了extract之后,则表示将列表中每一个Selector对象中data对应的字符串提取出来
entry=response.xpath('/html/body/div[3]/div/div[2]/div/div[2]//text()').extract()
entry=''.join(entry)
dic={
'title':title,
'entry':entry
}
return dic
终端指令:scrapy crawl spidername -o filepath
scrapy crawl fjnuspider -o ./fjnuspider.csv
好处:简洁高效便捷
缺点:局限性比较强(数据只可以存储到指定后缀的文本wen)
基于管道:
编码流程:
数据解析
在item类中定义相关的属性
将解析的数据封装存储到item类型的对象
将item类型的对象提交给管道进行持久化存储的操作
在管道类的process_item中要将其接收到的item对象中存储的数据进行持久化存储操作
在配置文件中开启管道
好处:
通用性强。
1:数据解析:
import scrapy
from fjnu.items import FjnuItem
class FjnuspiderSpider(scrapy.Spider):
name = 'fjnuspider'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.fjnu.edu.cn/11/4a/c13a332106/page.htm']
def parse(self, response):
#解析题目和正文
#xpath返回的是列表,但是列表元素一定Selector类型的对象
#extract可以将Selector对象中的data参数存储的字符串提取出来
title=response.xpath('/html/body/div[3]/div/div[2]/div/h1/text()')[0].extract()
#列表调用了extract之后,则表示将列表中每一个Selector对象中data对应的字符串提取出来
entry=response.xpath('/html/body/div[3]/div/div[2]/div/div[2]//text()').extract()
entry=''.join(entry)
item=FjnuItem()
item['title']=title
item['entry']=entry
yield item #将item提交给了管道
2:在item类中定义相关的属性
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class FjnuItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()
entry=scrapy.Field()
#pass
3:将解析的数据封装存储到item类型的对象/将item类型的对象提交给管道进行持久化存储的操作
在spider中
item=FjnuItem()
item['title']=title
item['entry']=entry
yield item #将item提交给了管道
4:在管道类的process_item中要将其接收到的item对象中存储的数据进行持久化存储操作(在pipelines中)
class FjnuPipeline:
fp=None
#重写父类的一个方法:该方法只在开始爬虫的时候被调用一次
def open_spider(self,spider):
print("开始爬虫")
self.fp=open('./fjnu.txt','w',encoding='utf-8')
#专门用来处理item类型对象
#该方法可以接收爬虫文件提交过来的item对象
#该方法每接收到一个item就会被调用一次
def process_item(self, item, spider):
title=item['title']
entry=item['entry']
self.fp.write(title+':'+entry+'\n')
return item
def close_spider(self,spider):
print('结束爬虫')
self.fp.close()
5:在配置文件中开启管道
settings中
ITEM_PIPELINES = {
'fjnu.pipelines.FjnuPipeline': 300,
#300表示的是优先级,数值越小优先级越高
}
6:scrapy crawl spidername
结果:

3.3 基于终端指令的持久化存储(将爬取到的数据一份存储到本地一份存储到数据库)
思路定义多个管道类
管道文件中一个管道类对应的是将数据存储到一种平台 爬虫文件提交的item只会给管道文件中的第一个被执行的管道类接收 process_item 中的return item表示将item传递给下一个即将被执行的管道类
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class FjnuPipeline(object):
fp=None
#重写父类的一个方法:该方法只在开始爬虫的时候被调用一次
def open_spider(self,spider):
print("开始爬虫")
self.fp=open('./fjnu.txt','w',encoding='utf-8')
#专门用来处理item类型对象
#该方法可以接收爬虫文件提交过来的item对象
#该方法每接收到一个item就会被调用一次
def process_item(self, item, spider):
title=item['title']
entry=item['entry']
self.fp.write(title+':'+entry+'\n')
return item #就会传递给下一个即将被执行的管道类
def close_spider(self,spider):
print('结束爬虫')
self.fp.close()
#管道文件中一个管道类对应将一组数据存储到一个平台或者载体中
class mysqlPipeLine(object):
conn=None
cursor=None
def open_spider(self,spider):
self.conn=pymysql.Connect(host='localhost',port=3306,user='root',password='123321abc',db='db_bookmall')
def process_item(self,item,spider):
self.cursor=self.conn.cursor()
print(item)
try:
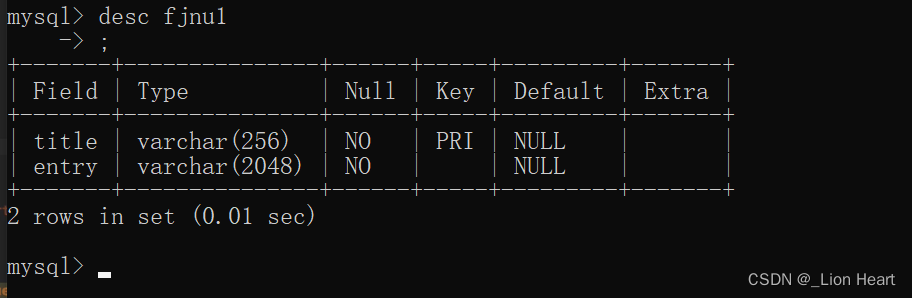
self.cursor.execute('insert into fjnu1 values("%s","%s")'%(item["title"],item["entry"]))
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
#爬虫文件提交的item类型的对象最终会提交给哪一个管道类?
#先执行的管道类
设置settings
ITEM_PIPELINES = {
'fjnu.pipelines.FjnuPipeline': 300,
'fjnu.pipelines.mysqlPipeLine':301
#300表示的是优先级,数值越小优先级越高
}
最后 scrapy crawl spidername
查看musql
3.4 基于spider的全站数据爬取
全站数据爬取:就是将网站中某板块下的全部页码对应的页面数据进行爬取
需求:爬取大学校花板块所有的校花照片名称
实现方式:
将所有页面的url添加到start_urls列表中(不推荐使用)
自行手动进行请求发送(推荐)
yied scrapy.Request(url,callback):callback专门用做于数据解析
spider代码
import scrapy
class XhspiderSpider(scrapy.Spider):
name = 'xhspider'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.ruyile.com/nice/?f=5']
#生成一个通用的url模板(不可变的)
url='https://www.ruyile.com/nice/?f=5&p=%d'
page_num=2
def parse(self, response):
div_list=response.xpath('/html/body/div[4]/div[1]/div[2]/div[@class="tp_list"]')
for div in div_list:
title_name=div.xpath('./div[2]/a/text()')[0].extract()
# title_name=div.xpath('./div[@class="tp_mz"]/a/text()')[0].extract()
print(title_name)
#这边只打印前三页
if self.page_num<=11:
new_url=format(self.url%self.page_num)
self.page_num+=1
#手动请求发送:callback回调函数是专门用作于数据解析
yield scrapy.Request(url=new_url,callback=self.parse)
或者这种
import scrapy
class XhspiderSpider(scrapy.Spider):
name = 'xhspider'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.ruyile.com/nice/?f=5']
#生成一个通用的url模板(不可变的)
url='https://www.ruyile.com/nice/?f=5&p='
page_num=2
def parse(self, response):
div_list=response.xpath('/html/body/div[4]/div[1]/div[2]/div[@class="tp_list"]')
for div in div_list:
title_name=div.xpath('./div[2]/a/text()')[0].extract()
# title_name=div.xpath('./div[@class="tp_mz"]/a/text()')[0].extract()
print(title_name)
#这边只打印前三页
if self.page_num<=11:
new_url=self.url+str(self.page_num)
self.page_num+=1
#手动请求发送:callback回调函数是专门用作于数据解析
yield scrapy.Request(url=new_url,callback=self.parse)
3.5 请求传参01
使用场景:如果爬取解析的数据不在用一张页面中。(深度爬取)
需求:爬取安居客租房二手房的房源名称和具体房源信息
已知一个网页url,需要在这个网页上抓取新的 url继续访问抓取
网址:北京租房信息|北京租房租金_价格_房价|房产网-安居客租房网
#spider settings配置如之前
import scrapy
from bosspro.items import BossproItem
class BossspiderSpider(scrapy.Spider):
name = 'bossspider'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://bj.zu.anjuke.com/?t=1&from=0&comm_exist=on&kw=%E4%BA%8C%E6%89%8B%E6%88%BF']
#回调函数接受item
def parse_detail(self,response):
item=response.meta['item']
home_desc=response.xpath('/html/body/div[3]/div[2]/div[1]/div[6]/b/text()').extract()
desc=""
for i in home_desc:
desc+=i
# print(desc)
item['desc']=desc
yield item
# home_desc=''.join(home_desc)
# print(home_desc)
def parse(self, response):
div_list=response.xpath('//*[@id="list-content"]/div[@class="zu-itemmod"]')
for div in div_list:
item=BossproItem()
title=div.xpath('./div[1]/h3/a/b/text()')[0].extract()
detail_url=div.xpath('./div[1]/h3/a/@href')[0].extract()
item['title']=title
# print(title)
#对详情页发请求获取详情页的页面数据源码数据
#手动请求的发送
detail_url=detail_url.rsplit("?")[0]
#请求传参:meta={},可以将meta字典传递给请求对应的回调函数
yield scrapy.Request(detail_url,callback=self.parse_detail,meta={'item':item})
pipelines class BossproPipeline: def process_item(self, item, spider): print(item) return item
items
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class BossproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()
desc=scrapy.Field()
pass
3.6 请求传参02(全站数据爬取)
import scrapy
from bosspro.items import BossproItem
class BossspiderSpider(scrapy.Spider):
name = 'bossspider'
url1='https://bj.zu.anjuke.com/fangyuan/p'
url2='/?t=1&comm_exist=on&kw=%E4%BA%8C%E6%89%8B'
# allowed_domains = ['www.xxx.com']
pagenum=2
start_urls = ['https://bj.zu.anjuke.com/?t=1&from=0&comm_exist=on&kw=%E4%BA%8C%E6%89%8B%E6%88%BF']
#回调函数接受item
def parse_detail(self,response):
item=response.meta['item']
home_desc=response.xpath('/html/body/div[3]/div[2]/div[1]/div[6]/b/text()').extract()
desc=""
for i in home_desc:
desc+=i
# print(desc)
item['desc']=desc
yield item
# home_desc=''.join(home_desc)
# print(home_desc)
def parse(self, response):
div_list=response.xpath('//*[@id="list-content"]/div[@class="zu-itemmod"]')
for div in div_list:
item=BossproItem()
title=div.xpath('./div[1]/h3/a/b/text()')[0].extract()
detail_url=div.xpath('./div[1]/h3/a/@href')[0].extract()
item['title']=title
# print(title)
#对详情页发请求获取详情页的页面数据源码数据
#手动请求的发送
detail_url=detail_url.rsplit("?")[0]
#请求传参:meta={},可以将meta字典传递给请求对应的回调函数
yield scrapy.Request(detail_url,callback=self.parse_detail,meta={'item':item})
#分页操作
if self.pagenum<=3:
new_url=self.url1+str(self.pagenum)+self.url2
self.pagenum+=1
yield scrapy.Request(new_url,callback=self.parse)
3.7 scrapy 图片爬取之ImagePipeline
基于scrapy爬取字符串类型的数据和爬取图片类型的数据区别?
字符串:只需要基于xpath进行解析且提交管道进行持久化存储
图片:xpath解析出图片src属性值。单独的对图片地址发送请求获取图片二进制类型的数据
ImagePipeline:
只需要将img的src的属性值进行解析,提交到管道,管道就会对图片的src进行请求发送获取图片的二进制类型的数据,且还会帮我们进行持久化存储
需求:爬取站长素材中的高清图片
使用流程:
数据解析(图片的地址)
将存储图片地址的item提交到指定的管道类
在管道文件中自定制一个基于ImagesPipeLine的一个管道类
get_media_request()
file_path()
item_completed()
在配置文件中:
指定图片存储的目录: IMAGES_STORE='./imgs'
指定开启的管道:自定制的管道类
#spider
import scrapy
from imgPro.items import ImgproItem
class ImgspiderSpider(scrapy.Spider):
name = 'imgspider'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://sc.chinaz.com/tupian/']
def parse(self, response):
div_list=response.xpath('/html/body/div[3]/div[2]/div')
print(div_list)
for div in div_list:
src=div.xpath('./img/@data-original')[0].extract()
print('https:'+src)
item=ImgproItem()
item['src']='https:'+src
yield item
#items import scrapy class ImgproItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() src=scrapy.Field()
#pipelines
import scrapy
from scrapy.pipelines.images import ImagesPipeline
# class ImgproPipeline:
# def process_item(self, item, spider):
# return item
class imgPileLine(ImagesPipeline):
#就是可以根据图片地址进行图片数据的请求
def get_media_requests(self, item, info):
yield scrapy.Request(item['src'])
#指定图片存储的路径
def file_path(self, request, response=None, info=None, *, item=None):
imgName=request.url.split('/')[-1]
return imgName
def item_completed(self, results, item, info):
return item #返回给下一个即将被执行的管道类
3.8 scrapy中间件
中间件:
下载中间件:
位置:引擎和下载器之间
作用:批量拦截到整个工程中所有的请求和响应
拦截请求:
UA伪装:process_request
代理IP:process_exception :return request
拦截响应:
篡改响应数据,响应内容
#middlewares
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
import random
class MiddleproSpiderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, or item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class MiddleproDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
user_agent_list = [
# Opera
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60",
"Opera/8.0 (Windows NT 5.1; U; en)",
"Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50",
# Firefox
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
# Safari
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2",
# chrome
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16",
# 360
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko",
# 淘宝浏览器
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
# 猎豹浏览器
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
# QQ浏览器
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
# sogou浏览器
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)",
# maxthon浏览器
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.3.4000 Chrome/30.0.1599.101 Safari/537.36",
# UC浏览器
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36",
# 各种移动端
# IPhone
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
# IPod
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
# IPAD
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
# Android
"Mozilla/5.0 (Linux; U; Android 2.2.1; zh-cn; HTC_Wildfire_A3333 Build/FRG83D) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
# QQ浏览器 Android版本
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
# Android Opera Mobile
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
# Android Pad Moto Xoom
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
# BlackBerry
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
# WebOS HP Touchpad
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
# Nokia N97
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
# Windows Phone Mango
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
# UC浏览器
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
# UCOpenwave
"Openwave/ UCWEB7.0.2.37/28/999",
# UC Opera
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999"
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
PROXY_http=[
'153.180.102.104:80',
'195.208.131.189:56055'
]
PROXY_https=[
'120.83.49.90:9000',
'95.189.112.214:35508'
]
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
#拦截请求
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
#UA伪装
request.headers['User-Agent']='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
#为了验证代理的操作是否生效
request.meta['proxy']='http://112.28.231.248:36670'
return None
#拦截所有的响应
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
#拦截发生异常的请求
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
if request.url.split(':')[0]=='http':
#代理
request.meta['proxy']='http://'+random.choice(self.PROXY_http)
else:
request.meta['proxy'] = 'https://' + random.choice(self.PROXY_https)
return request #将修正之后的请求对象进行重新的请求发送
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
#spider
import scrapy
class MiddleSpider(scrapy.Spider):
#爬取百度
name = 'middle'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.baidu.com/s?ie=UTF-8&wd=ip']
def parse(self, response):
page_text=response.text
with open('./ip.html','w',encoding='utf-8') as fp:
fp.write(page_text)
3.10 网易新闻
拦截响应:
需求:爬取网易新闻中的新闻数据(标题和内容)
1.通过网易新闻的首页解析出五大板块对应的详情页的url(没有动态加载)
2.每一个板块对应的新闻标题都是动态加载出来的
3.通过解析出每一条新闻的详情页的url获取详情页的页面yuan'ma
网址:https://news.163.com/
#spider
import scrapy
from selenium import webdriver
from wangyiPro.items import WangyiproItem
class WangyinewsSpider(scrapy.Spider):
name = 'wangyinews'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://news.163.com/']
models_url=[] #存储五个板块详情页的url
#解析板块对应详情页的url
#实例化一个浏览器对象
def __init__(self):
self.bro=webdriver.Chrome(executable_path='D:\Python_workplace\project\project_01\wangyiPro\chromedriver.exe')
# self.bro=Chrome()
def parse(self, response):
li_list=response.xpath('//*[@id="index2016_wrap"]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
alist=[1,2,4,5]
for index in alist:
href=li_list[index].xpath('./a/@href')[0].extract()
self.models_url.append(href)
#依次对每一个板块对应的页面进行请求
for url in self.models_url:#对每一个模块的url进行请求发送
yield scrapy.Request(url,callback=self.parse_model)
def parse_model(self,response):#解析每一个板块页面中对应新闻的标题和新闻详情页的url
div_list=response.xpath('/html/body/div/div[3]/div[3]/div[1]/div[1]/div/ul/li/div/div')
for div in div_list:
title=div.xpath('./div/div[1]/h3/a/text()')[0].extract()
new_detail_url=div.xpath('./div/div[1]/h3/a/@href')[0].extract()
#对新闻的详情页的url发起请求
item=WangyiproItem()
item['title']=title
yield scrapy.Request(url=new_detail_url,callback=self.parse_detail,meta={'item':item})
def parse_detail(self,response):#解析新闻内容
content=response.xpath('//*[@id="content"]/div[2]//text()').extract()
content=''.join(content)
item=response.meta['item']
item['content']=content
yield item
def close(self,spider):
self.bro.quit()
#Pipeline class WangyiproPipeline: def process_item(self, item, spider): print(item) return item
#middlewares from scrapy.http import HtmlResponse import time class WangyiproDownloaderMiddleware: # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the downloader middleware does not modify the # passed objects. def process_request(self, request, spider): # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called return None #该方法拦截板块对应的响应对象进行篡改 def process_response(self, request, response, spider): #挑选出指定的响应对象进行篡改 #通过url指定request #通过request指定response bro=spider.bro #获取了在爬虫类中定义的浏览器对象 if request.url in spider.models_url: bro.get(request.url) #对板块的url进行请求 time.sleep(2) page_text=bro.page_source #包含了动态加载的新闻数据 #response #板块对应的响应对象 #针对定位道德这些response进行纂改 #实例化一个新的响应对象(符合需求:包含动态加载出的新闻数据),替代原来旧的响应对象 #如何获取加载后的动态新闻数据? #基于selenium便捷的动态加载数据 new_response=HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request) return new_response else: #response#其他请求对应的响应对象 return response def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain pass
#item import scrapy class WangyiproItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() content=scrapy.Field()
3.11 CrawSpider的全站数据爬取
CrawSpider类:Spider的一个子类
全站数据爬取的方式;
基于Spider:手动请求
基于CrawlSpider
CrawlSpider的使用:
创建一个工程
cd xxx
创键爬虫文件(CrawlSpider)、
scrapy genspider -t crawl spidername www.xxx.com
链接提取器:
作用:根据指定规则(allow=‘正则表达式’)进行指定链接的提取
规则解析器:
作用:将链接提取器提取到的链接进行指定规则(callback)的解析
#需求:爬取标题、日期以及详情页的内容
分析:爬取的数据没有在同一张页面中。
1.可以使用链接提取器提取所有的页码链接
2.让链接ti
#spider
import scrapy
#链接提取器
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from sunPro.items import SunproItem,DatailItem,qqItem
#需求:爬取标题、日期以及详情页的内容
class SunSpider(CrawlSpider):
name = 'sun'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://gs.xmu.edu.cn/zhxx.htm']
#链接提取器:根据指定规则(allow='正则表达式')进行指定链接的提取
link=LinkExtractor(allow=r'zhxx/\d+\.htm')
link_detail=LinkExtractor(allow=r'https://gs.xmu.edu.cn/info/\d+/\d+\.htm')
link_detail_qq=LinkExtractor(allow=r'https://mp.weixin.qq.com/s/.*?')
rules = (
#规则解析器:将链接提取器提取到的链接进行指定规则(callback)的解析操作
Rule(link, callback='parse_item', follow=True),
#follow=True:可以将链接提器 继续作用到 链接提取器提取到的链接 所对应的页面中
Rule(link_detail,callback='parse_detail'),
Rule(link_detail_qq,callback='parse_detail_qq')
)
#如下解析方法中是不可以实现请求传参!
#无法将解析方法解析的数据存储到同一个item中,可以依次存储到两个item中
#解析标题和日期
def parse_item(self, response):
# item = {}
# #item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# #item['name'] = response.xpath('//div[@id="name"]').get()
# #item['description'] = response.xpath('//div[@id="description"]').get()
# return item
#注意:xpath表达式中不可以出现tbody标签
div_list=response.xpath('/html/body/div/div[3]/div/div/div[2]/div/div[2]/div[@class="row list-item"]')
for div in div_list:
title=div.xpath('./div[1]/a/text()')[0].extract()
date=div.xpath('./div[2]/text()')[0].extract()
# print(title,date)
item=SunproItem()
item['title']=title
item['date']=date
yield item
#解析文件内容
def parse_detail(self,response):
print(response)
detail_title=response.xpath('//div/div[3]/div/div/div/form/div/div[1]/text()')[0].extract()
content=response.xpath('//*[@id="vsb_content"]/div//text()').extract()
content=''.join(content)
# print(detail_title,content)
item=DatailItem()
item['detail_title']=detail_title
item['content']=content
yield item
def parse_detail_qq(self,response):
if response.status==200:
detail_qq_title=response.xpath('//*[@id="activity-name"]/text()')[0].extract()
qq_content=response.xpath('//*[@id="js_content"]/section/section//text()').extract()
qq_content=''.join(qq_content)
# print(detail_qq_title,qq_content)
item=qqItem()
item['detail_qq_title']=detail_qq_title
item['qq_content']=qq_content
yield item
#items import scrapy class SunproItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title=scrapy.Field() date=scrapy.Field() class DatailItem(scrapy.Item): detail_title = scrapy.Field() content = scrapy.Field() class qqItem(scrapy.Item): detail_qq_title = scrapy.Field() qq_content = scrapy.Field()
#pipelines class SunproPipeline: def process_item(self, item, spider): #如何判定item的类型 if item.__class__.__name__=='SunproItem': print(item['title'],item['date']) elif item.__class__.__name__=='DatailItem': print(item['detail_title'],item['content']) else: print(item['detail_qq_title'],item['qq_content']) return item















 2709
2709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









