






承接上一篇文档《Spark应用的结构》
参数说明:

创建一个Maven项目
Pom文件引入jar,配置信息已经完成,大家可以直接去网盘下载,版本号根据自己的安装情况调整
部分示例

创建一个scala文件,编写代码
1. 构建SparkContext上下文对象
val conf = new SparkConf()val sc = new SparkContext(conf)此时可以运行这两行代码

会出现错误

需要添加一行代码
setMaster("local")// 指定应用在哪儿执行,可以是local、或者stadnalone、yarn、mesos集群
再运行一次
又报一次错,这个是要求指定应用的名字

添加代码
.setAppName("pvtest") //指定应用的名字
再运行就可以了(启动hadoop)
2. 基于sc构建RDD
端口为core-site.xml中配置的
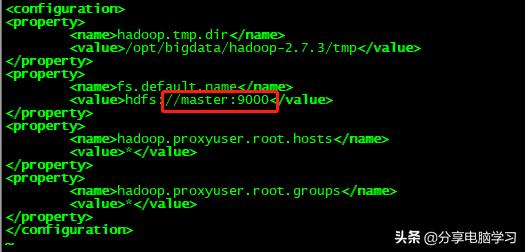
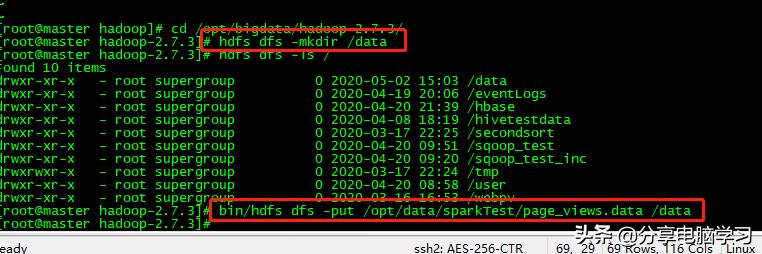
将文件上传到指定目录
val path = "hdfs://ip:8020/data/page_views.data" //HDFS的schema 给定数据的路径val rdd: RDD[String] = sc.textFile(path)println("总共有" + rdd.count()+ "条数据")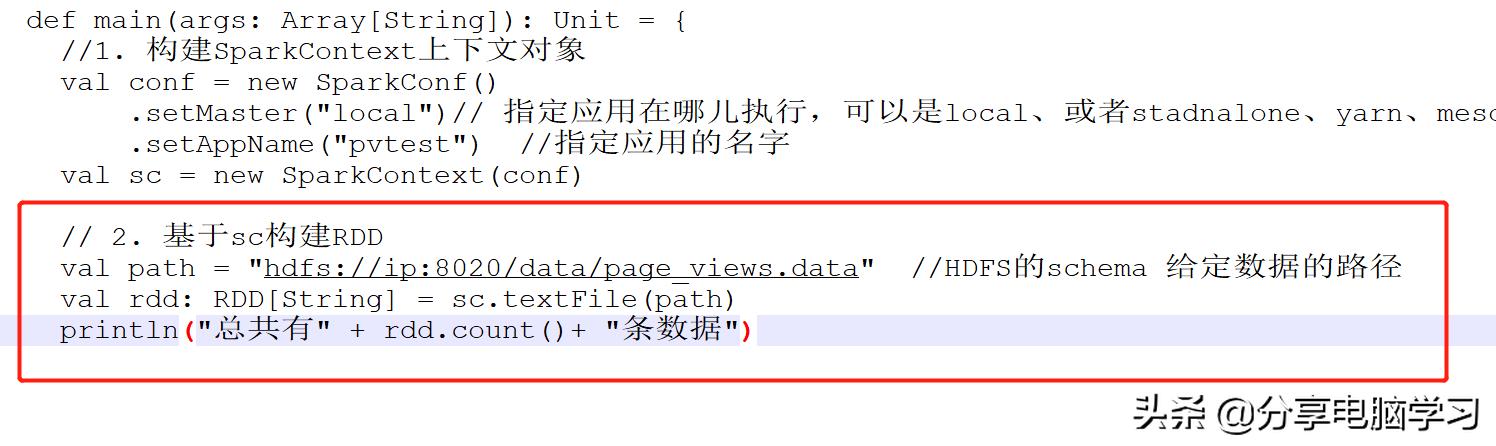
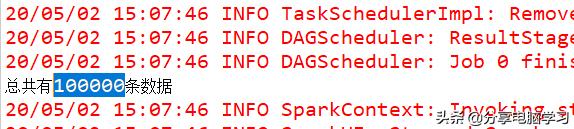
运行可以看到显示
如果不想写schema的话,需要将hadoop的两个文件拷贝到项目的src/main/resources中
两个文件是hadoop的:hdfs-site.xml和core-site.xml

编写代码
val path = /data/page_views.data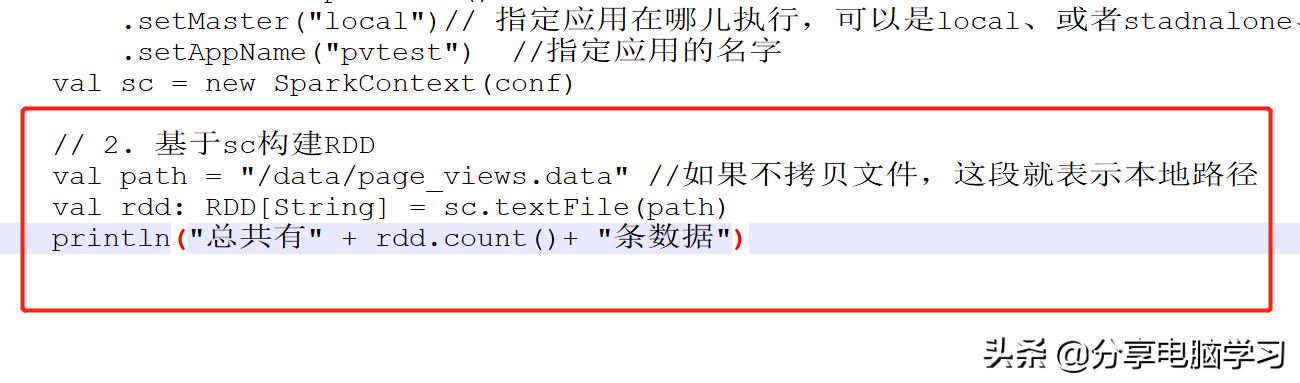
运行也可以查看到结果
3. 业务实现
思路:
(1)分析可知道:数据分为7个字段,业务需要三个字段(时间,URL,guid),计算某一个时间的PV的值(2)数据进行过滤清洗,获取两个字段(时间、url)(3)url非空,时间非空,时间字符串的长度必须大于10(4)sql: select date, count(url) from page_view group by date;(5)sql: select date, count(1) from page_view group by date;(6)分别用reduceByKey和groupByKey进行数据处理我们一步步来
先分割数据
val rdd1 = rdd.map(line => line.split(""))数据进行过滤清洗,获取两个字段(时间、url)
url非空,时间非空,时间字符串的长度必须大于10
.filter(arr => {//保留正常数据arr.length >2 && arr(1).trim.nonEmpty && arr(0).trim.length > 10})截取数据
.map(arr => {val date = arr(0).trim.substring(0,10)val url = arr(1).trim(date,1) // (date,url)})
基于reduceByKey做统计pv
val pvRdd = rdd1.reduceByKey(_+_)println("pv------------------" + pvRdd.collect().mkString(";"))数据表示2013年5月19日一共有100000条访问数据

也可以基于groupByKey实现pv统计(这个可以试一下,如果不行就使用reduceByKey)
groupByKey相当于把相同的key的value放到迭代器里面,也就是这些value都放到内存里面,如果value值数据量撑爆内存,就会OOM异常
val pvRdd = rdd1.groupByKey().map(t => {val date = t._1val pv = t._2.size(date,pv)})println("pv------------------" + pvRdd.collect().mkString(";"))与上面值相同















 5427
5427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









