







spark基础之filter、reduceByKey单词计数
来直接上代码
导入数据集
rdd = sc.textFile('F:/study\Spark/test.txt')
rdd.collect()

使用map
rdd1 = rdd.map(lambda x:x.split(','))

rdd2 = rdd1.map(lambda x:x[3])
rdd2.filter(lambda x:x=='男').count()
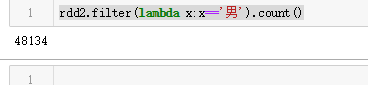
后面的就是单词计数了

将文档中的单词计数,保存为(单词,次数)的形式
rdd1 = rdd.flatMap(lambda x:x.split(' ')).flatMap(lambda x:x.split('?')).flatMap(lambda x:x.split('.'))
使用flatMap进行切割,因为句末的符号挨着单词的 ,故多次切割出来,但是还有有些小问题

会出现空字符
所以先剔除下空字符
使用filter 将不为空的提取出来
rdd1 = rdd1.filter(lambda x:x!='')
使用map将数据转换成(单词,1)的形式
rdd1.map(lambda x:(x,1)).collect()
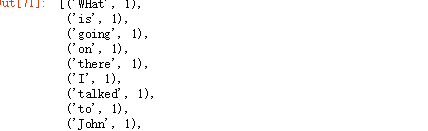
将相同单词后面的数值相加
rdd1 = rdd1.reduceByKey(lambda x,y:x+y)

将单词出现次数大于3次的提取出来
rdd1 = rdd1.filter(lambda x:x[1]>3)
rdd1.collect()















 5493
5493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









