






百度收录问题一直是不少渣渣头痛的问题,而官方其实提供了普通收录和快速收录这样的接口,直接调用官方api接口,大力出奇迹,你需要相信,你尽管seo,有排名算我输,不收录,怎么会呢,不是给你留了一个首页网址么?以前写过熊掌号的api网址提交,可惜被清退了,也不知道能不能用了。
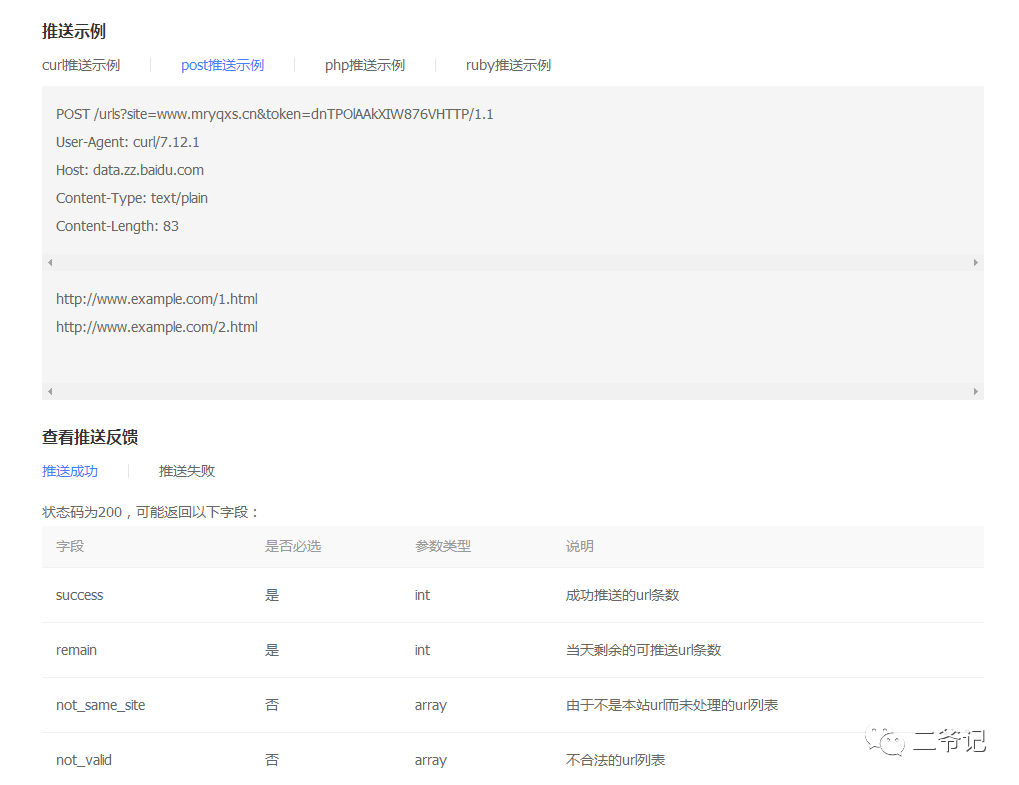
其实调用官方api还是比较简单,直接按照官方给出的示例和参数就能实现,稍微抄抄改改,你也能够实现,至于收录效果,还是前面说的那句话,也是国内seo人员的核心,大力出奇迹!
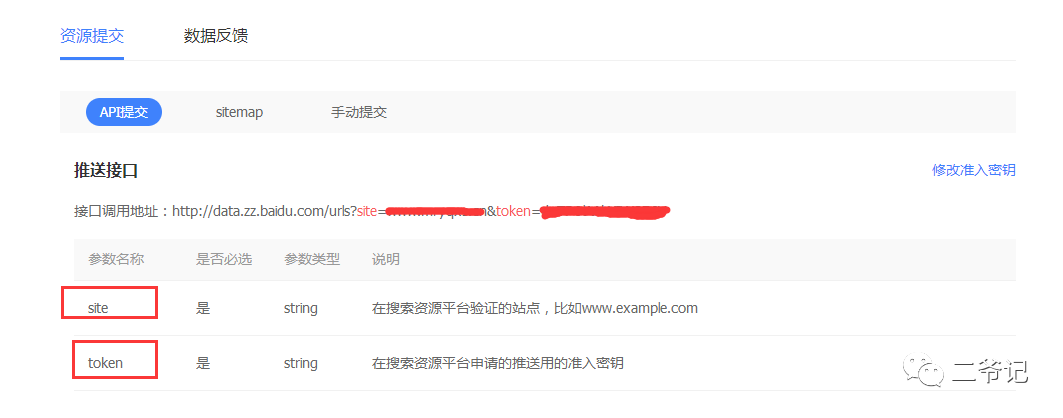
示例代码
#百度普通收录 资源提交 API提交
#微信:huguo00289
# -*- coding: UTF-8 -*-
import requests
import json
def api(site,token,url):
print(f">>> 正在向百度推送链接-- {url} ..")
post_url=f"http://data.zz.baidu.com/urls?site={site}&token={token}"
headers = {
'User-Agent': 'curl/7.12.1',
'Host': 'data.zz.baidu.com',
'Content-Type': 'text/plain',
'Content-Length': '83',
}
response=requests.post(post_url,headers=headers,data=url)
req=response.text
if "success" in req:
print(f"恭喜,{url} -- 百度推送成功!")
req_json=json.loads(req)
print(f'当天剩余的可推送url条数: {req_json["remain"]}')
else:
print(f"{url} -- 百度推送失败!")
下面我们继续来优化完善一下!
首先网站地图,想必大家都知道,sitemap.xml格式文件,里面包含有网站所有的网站,我们可以通过它来向搜索引擎提交网业地址,同时我们也可以在它身上下功夫,这里我使用的网站地图文件为老虎地图所制作。
从sitemap.xml文件读取到网页链接地址,使用正则表达式就可以很轻松的实现目的!
示例代码
def get_url(self):
with open(self.path,'r',encoding='utf-8') as f:
xml_data=f.read()
print(">>> 读取网站地图文件成功!")
urls=re.findall(r'(.+?)',xml_data,re.S)
print(urls)
print(f">>> 共有网页链接数 :{len(urls)} 条!")
return urls
考虑到大部分大佬哥的网站链接推送数量可不少,这里应用了线程池的技术,多线程推送网址,比较简单,复制粘贴即可完成!
示例代码
def main(self):
urls=self.get_url()
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(self.api,urls)
pool.close()
pool.join()
print(">> 采集所有链接百度推送完成!")
except Exception as e:
print(f'错误代码:{e}')
print("Error: unable to start thread")
完整代码参考
#百度普通收录 资源提交 API提交
#微信:huguo00289
# -*- coding: UTF-8 -*-
import requests
import json,re
from multiprocessing.dummy import Pool as ThreadPool
class Ts():
def __init__(self,site,token,path):
self.site=site
self.token=token
self.path=path
def api(self,url):
print(f">>> 正在向百度推送链接-- {url} ..")
post_url = f"http://data.zz.baidu.com/urls?site={self.site}&token={self.token}"
headers = {
'User-Agent': 'curl/7.12.1',
'Host': 'data.zz.baidu.com',
'Content-Type': 'text/plain',
'Content-Length': '83',
}
response = requests.post(post_url, headers=headers, data=url)
req = response.text
if "success" in req:
print(f"恭喜,{url} -- 百度推送成功!")
req_json = json.loads(req)
print(f'当天剩余的可推送url条数: {req_json["remain"]}')
else:
print(f"{url} -- 百度推送失败!")
return None
def get_url(self):
with open(self.path,'r',encoding='utf-8') as f:
xml_data=f.read()
print(">>> 读取网站地图文件成功!")
urls=re.findall(r'(.+?)',xml_data,re.S)
print(urls)
print(f">>> 共有网页链接数 :{len(urls)} 条!")
return urls
def main(self):
urls=self.get_url()
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(self.api,urls)
pool.close()
pool.join()
print(">> 采集所有链接百度推送完成!")
except Exception as e:
print(f'错误代码:{e}')
print("Error: unable to start thread")
if __name__ == '__main__':
site="网站地址"
token="秘钥"
path=r"网站地图文件存储路径"
spider=Ts(site,token,path)
spider.main()
相关阅读:
百度主动推送工具汇总,Python POST工具实例源码

微信公众号:二爷记
不定时分享python源码及工具















 1619
1619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









