






折腾:
【未解决】Python的html网页主体内容提取
期间,去试试BeautifulSoup提取HTML网页主体内容
先去随便找个合适的网页
-》
简单看了看网页内容结构:
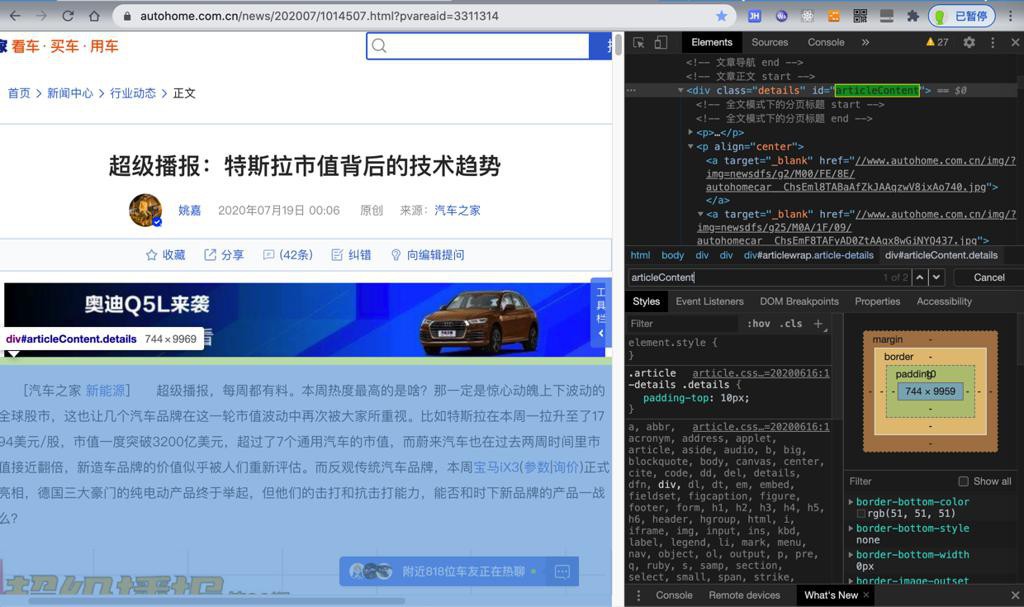
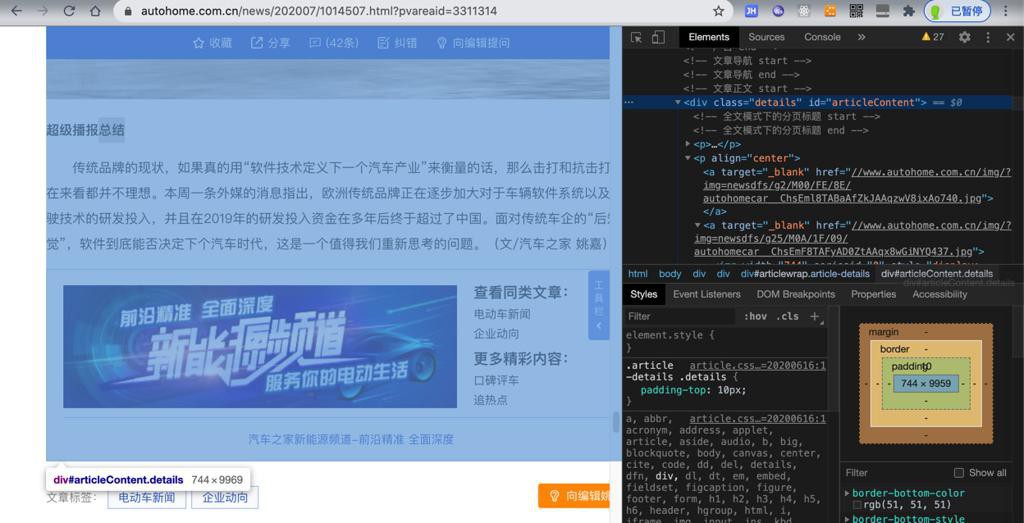
发现是:
网页主体内容是://*[@id="articleContent"]
/html/body/div[4]/div[1]/div[1]/div[4]
这部分其下的内容,才是新闻主体内容。
此处暂时就模拟获取articleContent其下的内容,视为文章主体内容
然后用代码:# Function: Use BeautifulSoup to extract body content of HTML web page
# Author: Crifan
# Update: 20200721
import os
import codecs
from datetime import datetime, timedelta
from bs4 import BeautifulSoup
import requests
################################################################################
# Config
################################################################################
CurrentFolder = os.getcwd()
CurrentFolder = os.path.abspath(CurrentFolder)
OutputRoot = os.path.join(CurrentFolder, "HtmlExtract", "output")
################################################################################
# Util Functions
################################################################################
def datetimeToStr(inputDatetime, format="%Y%m%d_%H%M%S"):
"""Convert datetime to string
Args:
inputDatetime (datetime): datetime value
Returns:
str
Raises:
Examples:
datetime.datetime(2020, 4, 21, 15, 44, 13, 2000) -> '20200421_154413'
"""
datetimeStr = inputDatetime.strftime(format=format)
# print("inputDatetime=%s -> datetimeStr=%s" % (inputDatetime, datetimeStr)) # 2020-04-21 15:08:59.787623
return datetimeStr
def getCurDatetimeStr(outputFormat="%Y%m%d_%H%M%S"):
"""
get current datetime then format to string
eg:
20171111_220722
:param outputFormat: datetime output format
:return: current datetime formatted string
"""
curDatetime = datetime.now() # 2017-11-11 22:07:22.705101
# curDatetimeStr = curDatetime.strftime(format=outputFormat) #'20171111_220722'
curDatetimeStr = datetimeToStr(curDatetime)
return curDatetimeStr
def saveTextToFile(fullFilename, text, fileEncoding="utf-8"):
"""save text content into file"""
with codecs.open(fullFilename, 'w', encoding=fileEncoding) as fp:
fp.write(text)
fp.close()
################################################################################
# Main
################################################################################
# 【图】超级播报:特斯拉市值背后的技术趋势_汽车之家
postUrl = "https://www.autohome.com.cn/news/202007/1014507.html?pvareaid=3311314"
resp = requests.get(postUrl)
respHtml = resp.text
# soup = BeautifulSoup(respHtml)
soup = BeautifulSoup(respHtml, "html.parser")
postHtml = str(soup.html)
# print("postHtml=%s" % postHtml)
curDatetimeStr = getCurDatetimeStr()
saveHtmlFileName = "html_%s.html" % curDatetimeStr
saveHtmlFilePath = os.path.join(OutputRoot, saveHtmlFileName)
saveTextToFile(saveHtmlFilePath, postHtml)
就保存出对应html文件了:
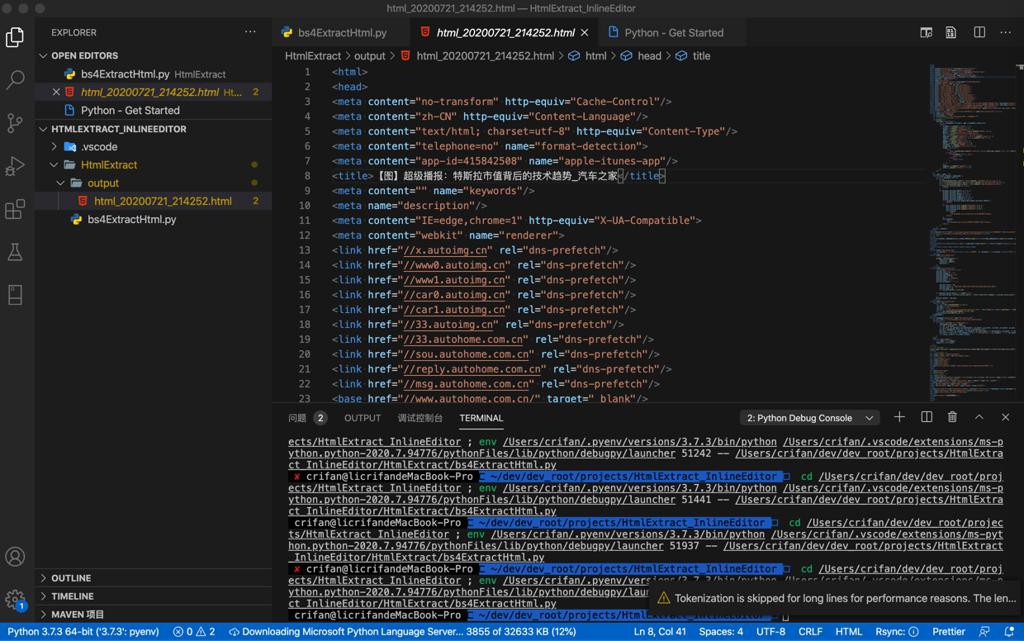
然后去打开看看效果,结果:
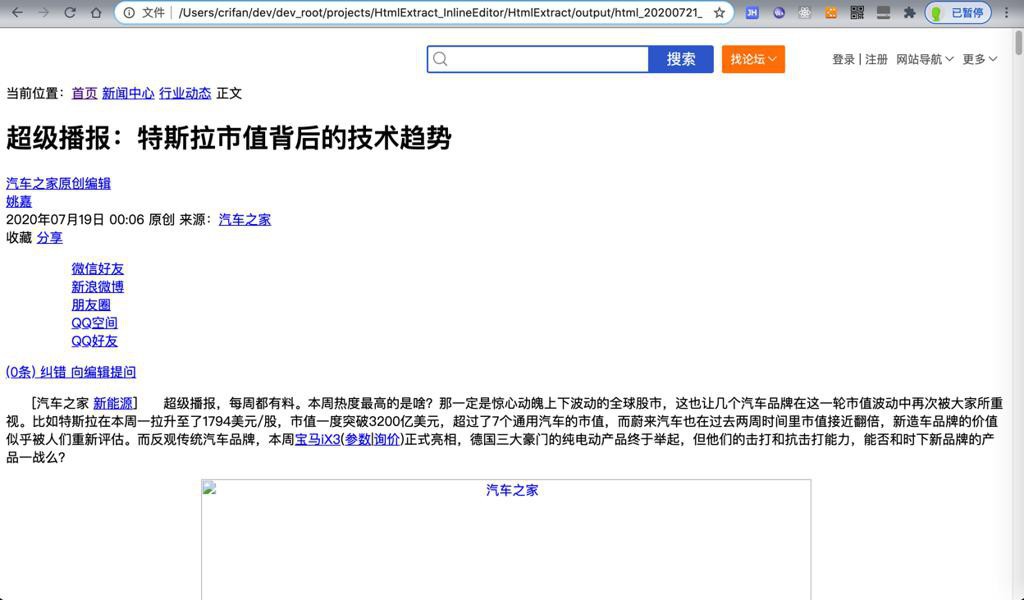
即:
【已解决】BeautifulSoup导出的网页内容中图片无法显示原因是把前缀https:变成file:了
至此,算是内容上,就基本OK了。
对于提取主体内容,即:
的://*[@id="articleContent"]
和此处
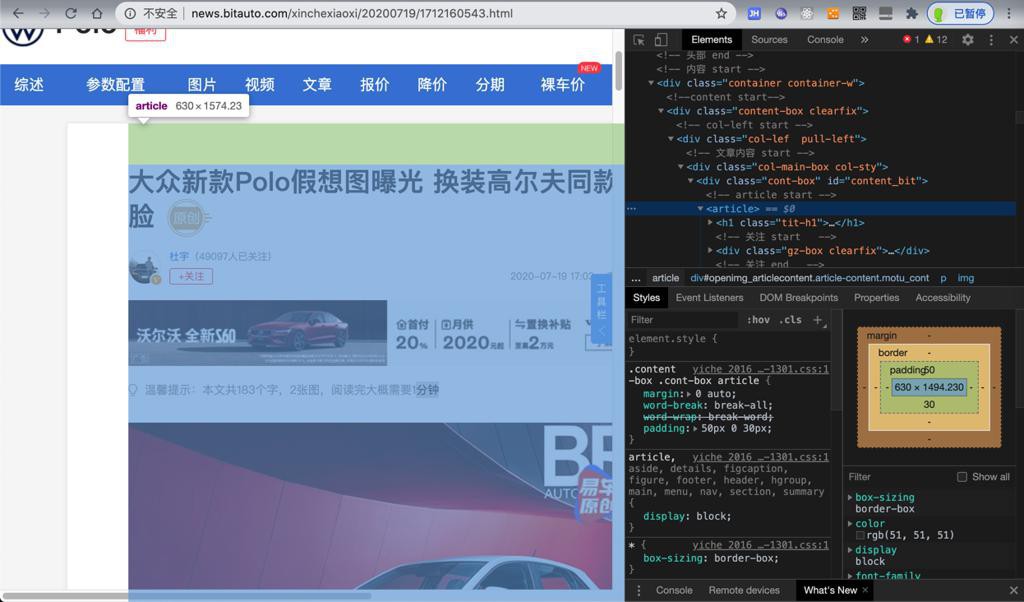
的:article
就以后再折腾。
【后记20200722】
再去折腾,提取主体内容,此处暂时用手动写规则的办法。
借用Chrome去复制出xpath:
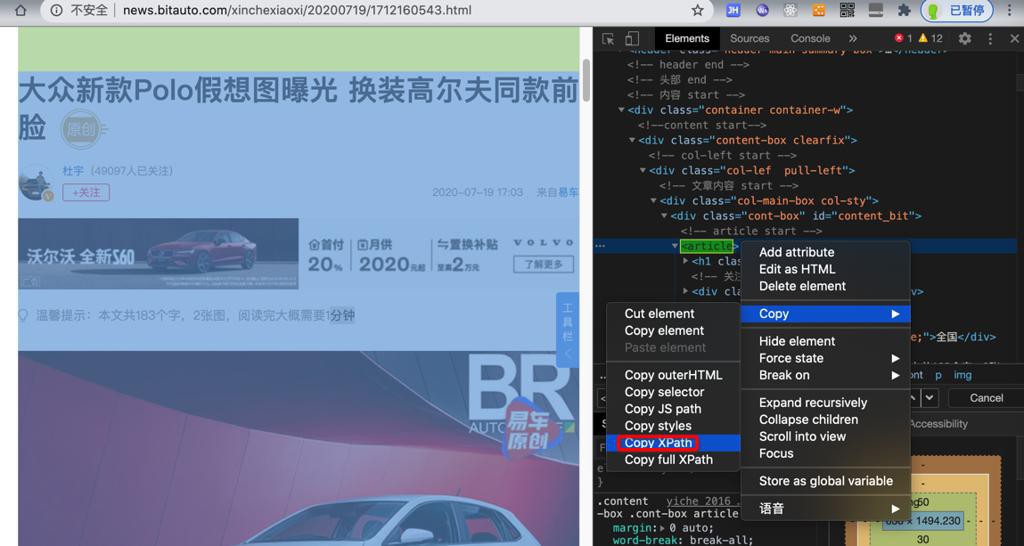
//*[@id="content_bit"]/article
不过此处发现article只有一处:
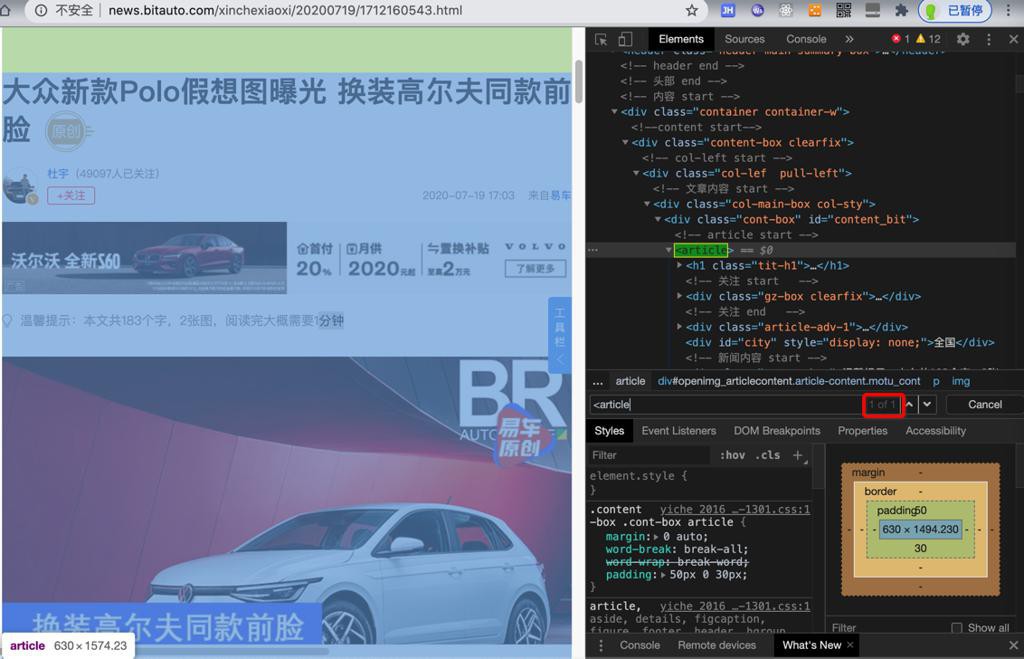
所以为了简单起见,直接用article也就可以了。
不过其中遇到:
【已解决】BeautifulSoup中find得到的soup节点如何获取自身及其下子孙节点的html源码
继续














 8322
8322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









