







前言
对于学习过爬虫的同学来说,如果要爬取的数据不在当前url地址所对应的网页源码中那真是比较痛苦了。这种情况下,数据要么是通过后期动态添加到网页中,要么就是通过ajax进行加载的。无论是哪一种对于初学者的同学来说都是异常的头疼。今天我们就以一种通俗简单的方式来分析一下ajax数据的特点(凡事有特殊,所以场景不同还需要特殊对待)实战
先解决一个问题什么是ajax?下面引入百度百科的一段解释 Ajax即"Asynchronous Javascript And XML"(异步 JavaScript和XML),是一种创建交互式、快速动态网页应用的网页开发技术,无需重新加载整个网页的情况下,能够更新部分网页的技术。 在这段话里面有一个关键点就是无需加载整个网页,就可以更新部分网页的技术 例如下面是一个12306的车次列表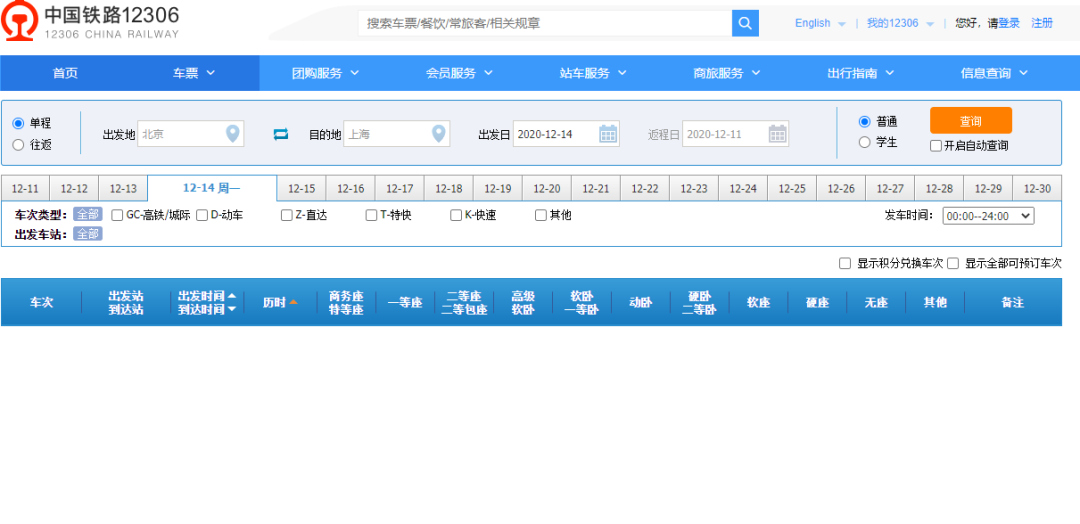
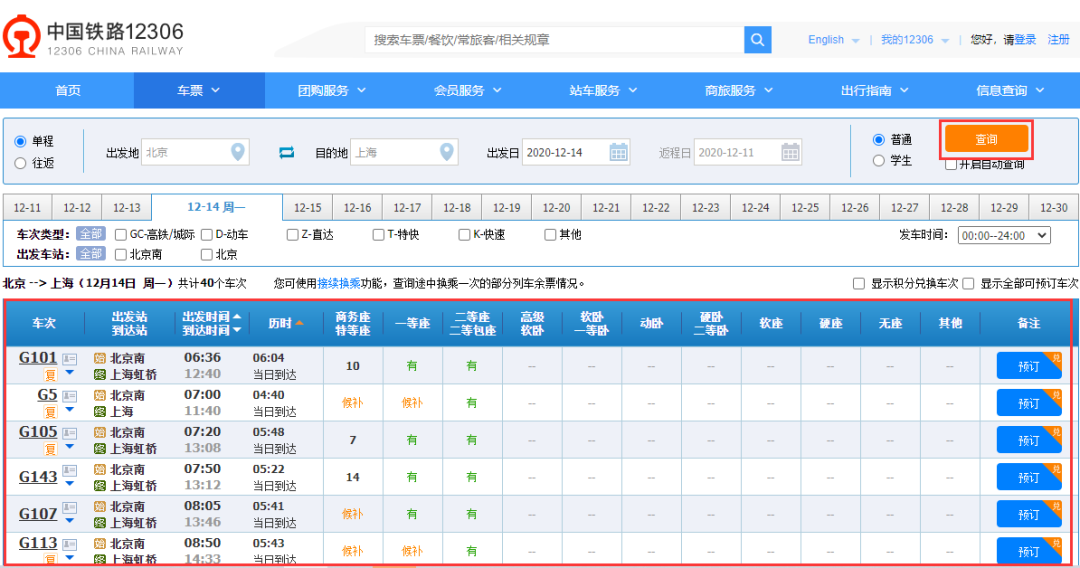
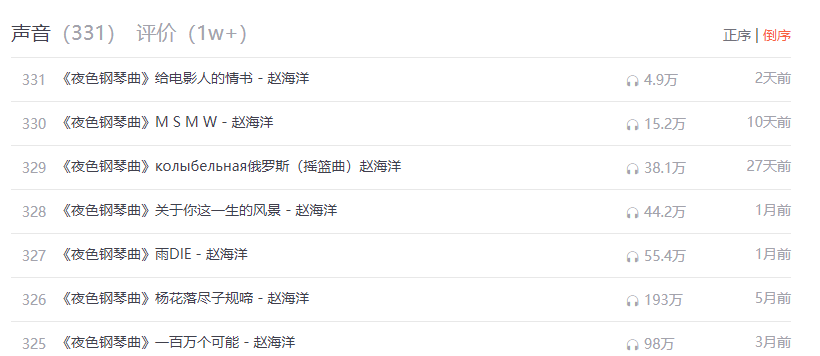
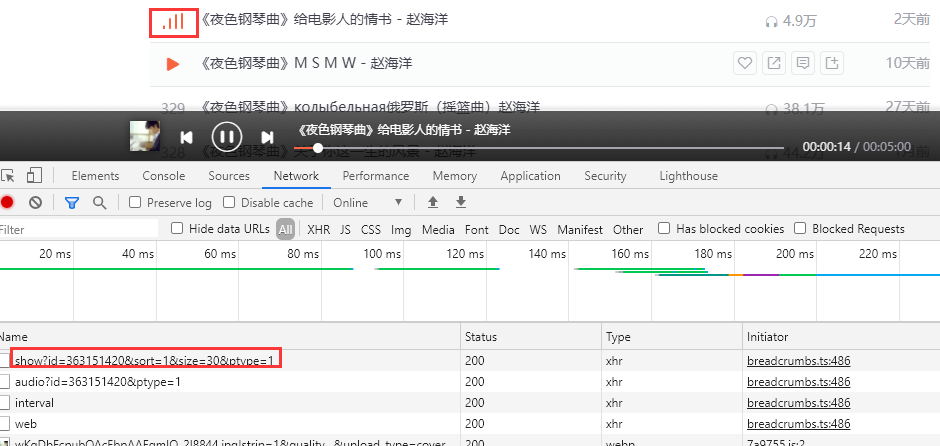
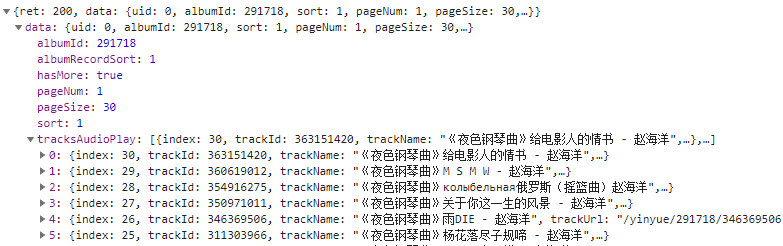



代码演示
import requests
import json# 1.拿到统一的url
url = 'https://www.ximalaya.com/revision/play/v1/show?id=231012348&sort=1&size=30&ptype=1'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
r = requests.get(url,headers=headers)
ret = r.text# 2.拿到音乐的id# print(type(ret))
result = json.loads(ret)
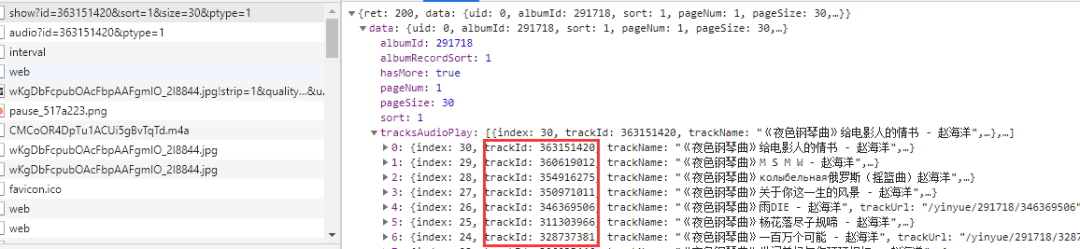
content_list = result['data']['tracksAudioPlay']for content in content_list:
t_id = content['trackId'] # 音频的id
name = content['trackName'] # 音频的name# print(t_id,type(t_id))
url = 'https://www.ximalaya.com/revision/play/v1/audio?id=%d&ptype=1'%t_id# print(url)# 请求音频的链接地址
mus_response = requests.get(url,headers=headers)# 拿到音频的网页数据
mus_html = mus_response.text# 把数据转换成字典
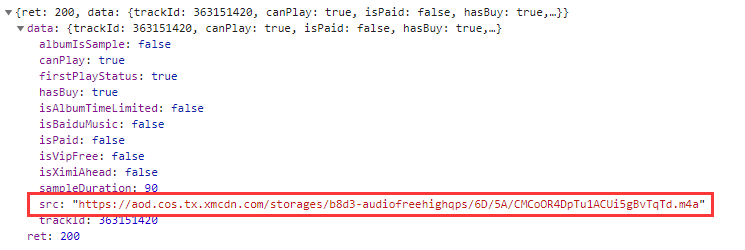
mus_result = json.loads(mus_html)# print(mus_html,type(mus_result))# 3 拿到音频的url
mus_src = mus_result['data']['src']# print(mus_src)# 4.保存所有的音频
with open('img/%s.m4a'% name,'wb') as f:
mus = requests.get(mus_src)
f.write(mus.content)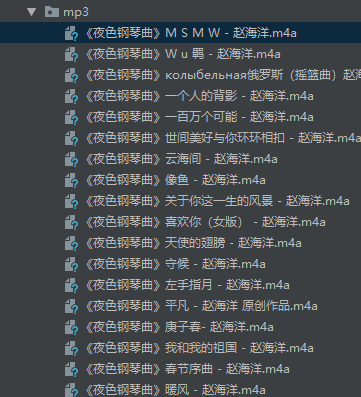
















 3235
3235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









