






对数据集进行分组并对各组应用一个函数(无论是聚合还是转换),这是数据分析工作中的重要环节。在将数据集准备好之后,通常的任务就是计算分组统计或生成透视表。pandas提供了一个灵活高效的gruopby功能,它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。
关系型数据库和SQL(Structured Query Language,结构化查询语言)能够如此流行的原因之一就是其能够方便地对数据进行连接、过滤、转换和聚合。但是,像SQL这样的查询语言所能执行的分组运算的种类很有限。在本章中你将会看到,由于Python和pandas强大的表达能力,我们可以执行复杂得多的分组运算(利用任何可以接受pandas对象或NumPy数组的函数)
本文包括:
- 根据一个或多个键(可以是函数、数组或DataFrame列名)拆分pandas对象。
- 计算分组摘要统计,如计数、平均值、标准差,或用户自定义函数。
- 对DataFrame的列应用各种各样的函数。
pandas.DataFrame.groupby
DataFrame.groupby(self, by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False, **kwargs)[source]
by : mapping, function, label, or list of labels
用于确定groupby的组。 如果by是一个函数,则调用对象索引的每个值。 如果传递了dict或Series,则将使用Series或dict VALUES来确定组(系列的值首先对齐;请参阅.align()方法)。 如果传递了ndarray,则使用这些值来确定组。 标签或标签列表可以通过self中的列传递给组。 请注意,元组被解释为(单个)键。
axis : {0 or ‘index’, 1 or ‘columns’}, default 0
按照行或列分割
level : int, level name, or sequence of such, default None
如果轴是MultiIndex(分层),则按特定级别或级别分组。
as_index : bool, default True
对于聚合输出,返回以组标签作为索引的对象。 仅与DataFrame输入相关。 as_index = False实际上是“SQL风格”的分组输出。
sort : bool, default True
对组键进行排序。 关闭它可以获得更好的性能。 请注意,这不会影响每组内观察的顺序。 Groupby保留每个组中的行顺序。
group_keys : bool, default True
调用apply时,将组键添加到索引以标识片段。
squeeze : bool, default False
如果可能,减少返回类型的维度,否则返回一致类型。
observed : bool, default False
**kwargs
Optional, only accepts keyword argument ‘mutated’ and is passed to groupby.
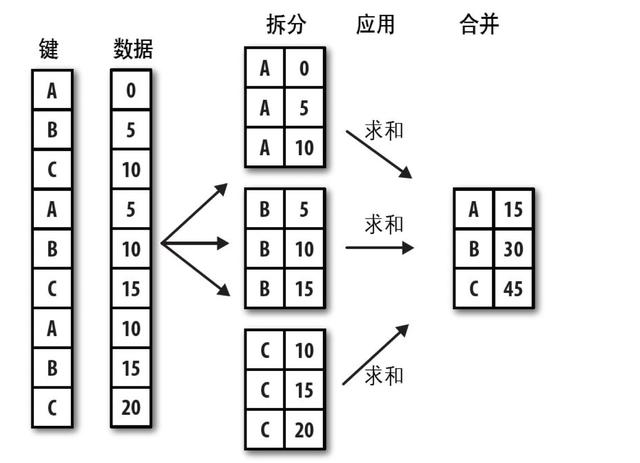
分组键可以有多种形式,且类型不必相同:
·列表或数组,其长度与待分组的轴一样。
·表示DataFrame某个列名的值。
·字典或Series,给出待分组轴上的值与分组名之间的对应关系。
·函数,用于处理轴索引或索引中的各个标签。
注意,后三种都只是快捷方式而已,其最终目的仍然是产生一组用于拆分对象的值。
简单的例子:
df = pd.DataFrame({'Animal': ['Falcon', 'Falcon','Parrot', 'Parrot'],'Max Speed': [380., 370., 24., 26.]})df
df.groupby(['Animal']).mean()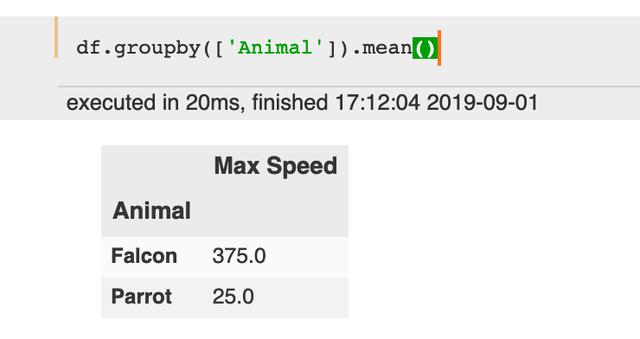
导入今天的实例:
data=pd.read_csv("hflights.csv")data
先按照一个键来分组:
data.groupby("DayofMonth").apply(np.sum)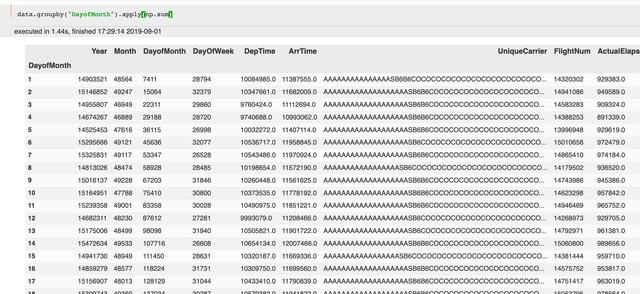
显然这不是我们想要的,通常我们会对某一列设置函数:
data.groupby("DayofMonth")["TaxiOut"].apply(np.sum)
按照多个键来分割:
data.groupby(["Year














 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









