






概述
递归函数都不陌生,比如计算n的阶乘:
当然,有人可能会这么写:
上面两种方式看着好像没什么区别,但是在cpu眼中,可就不一样了。
分析
函数在调用的时候会开辟一块函数栈,用来保存函数的局部变量、参数、上一个栈的指针、返回值等信息,当函数调用结束后会销毁。递归函数会一直递归下去,上层的函数栈一直不会销毁,知道递归结束,全部退出。
举个栗子,当调用f(3)的时候,对于上面的第一种情况,函数栈大概长这样(仅保留参数和返回值,忽略其他内容):
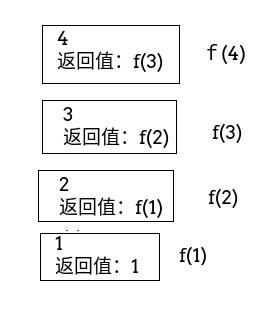
文字描述就是:
f(1)=1
f(2)=2*f(1)=2*1=2
f(3)=3*f(2)=3*2=6
f(4)=4*f(3)=4*6=24
也就是每一次调用,都会保存本次的变量n以及递归调用的返回值,这就会导致如果递归的太神,就会开辟太多的内存。
如果使用第二种写法,会有什么不同么?
套用刚才的分析,先用文字描述一下:
f(4, 1)=f(3, 4*1)=f(2, 3*4)=f(1, 2*12)=24
有没有发现区别,区别就是,前一种写法要保存一个局部变量n,而后一种写法,都写到下一个方法的参数中了。也就是说,第二种方式,可以直接返回下层方法,不需要退回去了。当然,cpu发现这种情况,会复用函数栈,也就是说,函数栈大概是这么个情况:
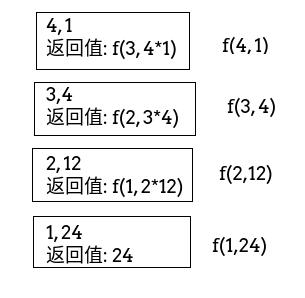
看着好像也没啥区别,但是!因为可以直接返回,上图的四个栈使用的都是同一个栈。
当递归返回的是递归调用,并且讲调用直接返回,没有参与运算等,就会被这样优化,复用栈。














 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









