






1 开门不见山
随着深度学习发展,深度学习的框架也层出不穷。现在最流行的深度学习框架应该非PyTorch莫属了。有数据显示,在2020的CVPR论文中PyTorch占比是TensorFlow 4 倍。从公司退来之后,终于有机会接触PyTorch。上手PyTorch之后,只能用两个子形容:真香。
在过去工作的两年里,从令人跺脚的Caffe到后来快速稳定的TensorFlow,我一直对PyTorch带着有色眼镜。讲道理,之前的PyTorch还是更适合做研究,对于工业界的一整套东西(数据整合,模型训练,模型验证,模型服务)支持的并不是很理想。现在的PyTorch,可谓是深度学习框架的翘楚。首先,各种类的封装做的没话说,理解和自定义类非常简单。其次,API设计的非常人性,功能很全,使用起来非常方便。最后,官方文档写的很详细,官方教程很多,并且还有PyTorch社区帮忙回答各种问题。
PyTorch的接口是Python,但底层主要都是用C++实现的。PyTorch使用一种称之为 imperative/eager 的范式,即每一行代码都要求构建一个图以定义完整计算图的一个部分。即使完整的计算图还没有完成构建,我们也可以独立地执行这些作为组件的小计算图,这种动态计算图被称为define-by-run方法。- 机器之心
上面这段摘自机器之心对PyTorch基本描述看起来很高大上,其实对同学入门PyTorch并没有太大帮助。但是因为上面这个设计理念,让PyTorch变的清新脱俗。因为大部分入门PyTorch的同学主要关心如何快速上手,所以,这里我就不再对这些高大上的设计理念展开更多的介绍。
牛顿说过:“如果我看得更远一点的话,是因为我站在巨人的肩膀上”。 PyTorch之所以能变的如此流行,也是因为站在了巨人的肩上。PyTorch不是闭门造车,更不是从头一点一点开始。很多人说:“PyTorch的工作流程非常接近于Python的科学计算库NumPy”。如此说来,PyTorch站在了NumPy的肩膀上。后面的内容,我会说明为什么PyTorch站在了NumPy的肩膀上。
由于PyTorch各类教程很多,我在最后列出了一些PyTorch学习资源,希望同学们对这些学习资源各取所需。这篇博客,我以介绍如何快速上手PyTorch为例子,同时介绍一种快速上手大型项目的方法。希望这样的学习方法可以帮助到一些学生。
2 拨开迷雾见月明
现在,如果你对PyTorch非常感兴趣,让我带你来走进PyTorch世界。那么,如何快速上手PyTorch,应对实战项目呢?
- 看官方文档
- 看开源PyTorch项目
- 看推荐PyTorch书籍
- 上精品PyTorch网课
- 大量练习写PyTorch代码!
上面5点,最重要的是大量练习写PyTorch代码!但是,一般来讲接触到一个陌生的东西,第一步是源自开源项目,然后开始看官方文档。那么现在就看一个例子 - 如何正确的自学成才。
import 很多开源PyTorch项目会看到上面的API。这也是PyTorch最重要的两个APIs。第一个API是torch, 基本是NumPy换了一个马甲,但是同时增加很多一个深度学习的框架应该有的基本功能。可以说,正式因为torch,才组建了如此高大上的深度学习的框架。我们可以用下面的例子来说明,让我们试试如何用torch实现torch.nn的功能。
import 上面的代码展示了一个分类问题损失函数 - 逻辑回归。其数学表达式如下:
最后结果两边的计算结果都是1.884。从这里开始很明显的看出:用torch基本的算子可以实现torch.nn的功能。看到这里,是不是感到很惊讶,感觉自己可以去做一个深度学习的框架了?别急,如果直接用torch的基本的算子实现的各种函数功能,可能需要写上万行多余的代码。而且这样的代码,对后期的维护、功能扩展、代码的性能优化、和其他硬软件的兼容都是灾难的铺垫!所以,PyTorch的开发人员利用编程中很重要的基本思想 - 面向对象编程。这个可能你都不清楚的基本思想,加上套了马甲的NumPy。不仅实现了torch.nn,还实现了许多PyTorch 1.5版本的APIs(接下来一章会对其进行详细介绍)。日后如果PyTorch继续发达了,请参考官方文档!一般同学看到这么复杂的文档,心情肯定是很糟糕的。但是,正如我最开始举的例子,它们都是继承者们,没错是torch的继承者们。所以,读到这里,你应该明白一件事情:
想要快速上手大型开源项目,首先抓住这个项目的核心。
这里的核心很明显就是torch,当你理解了torch。再开始找最需要理解的下一个继承者,很明显torch.nn需要搞明白。至于其他继承者们,应该怎么学呢?请看下面的分析。
3 分类讨论和按需理解
如果你也需要和有时间去了解这些继承者们。除了搞明白官方文档,还需要看书,上课,写代码。这里,我教同学一招如何快速搞明白官方文档。快速搞明白官方文档分两步,具体操作如下。
3.1 分类讨论
上面列出的一堆继承者们。大致可以分为下面这个几类(根据个人理解分类,没有绝对的正确)。分类的目的,是帮助同学快速逆向推理出项目的大致架构,从而可以快速理解项目的开发过程,进而可以更准确的根据需要理解对应的文档。
基本函数
- torch.nn
- torch.nn.functional
- torch.nn.init
- torch.autograd
- torch.optim
进阶函数
- torch.random
- torch.sparse
- torch.Storage
- Quantization
基本数据结构
- Tensor Attributes
- Tensor Views
进阶数据结构
- Type Info
- Named Tensors
- Named Tensors operator coverage
基本数据存储
- torch.cuda
- torch.cuda.amp
并行和分布式计算
- torch.distributed
- torch.distributions
- Distributed RPC Framework
模型库
- torch.hub
模型转换和调用
- torch.jit
- torch.onnx
常用工具箱
- torch.utils.bottleneck
- torch.utils.checkpoint
- torch.utils.cpp_extension
- torch.utils.data
- torch.utils.dlpack
- torch.utils.model_zoo
- torch.utils.tensorboard
各种深度学习任务数据接口
- torchaudio
- torchtext
- torchvision
集群训练和服务
- TorchElastic
- TorchServe
3.2 按需理解
3.2.1 例子-线性回归
经过上一轮分析,基本函数肯定要要搞明白的。这里面有:
- torch.nn
- torch.nn.functional
- torch.nn.init
- torch.autograd
- torch.optim
这部分我就用一个最简单的例子 - 线性回归,来帮助同学逐步理解这些PyTorch的基本函数。
机器学习有五大问题:分类、回归、聚类、降维、和强化。应用最广的可能就属回归分析了,其目的是帮助人们了解在只有一个自变量变化时因变量的变化量。在回归分析中,线性回归可谓是任何一门机器学习课程或者书籍的第一课,也是最简单和最先需要讲的算法。
import 上面是一个完整展示,用PyTorch中的基本函数来解决一个线性回归分析。其中我用到torch.nn中的Linear来构建一个线性回归的算法模型(行22)。然后用torch.optim中的SGD建立一个优化方法(行25)。最后用,torch.nn中的MSELoss来定义损失函数(26行)。利用Pytoch训练定义好的模型和参数非常简单,只需要六行就可以搞定(上面行30到行35的代码)。剩下的代码都是做可视化用的,这个同学不需要理解。
为了让同学更直观的看到训练过程,我将输入变量(特征值)的维度设置成1维。并且,我把整个训练过程可视化出来。
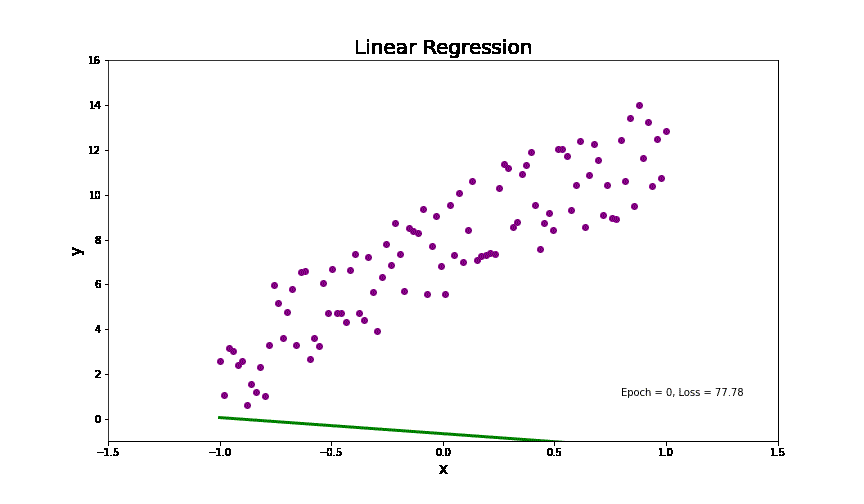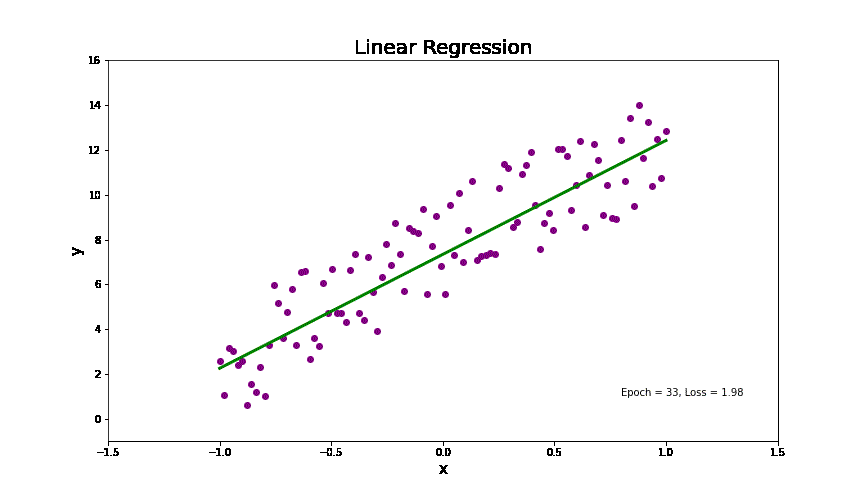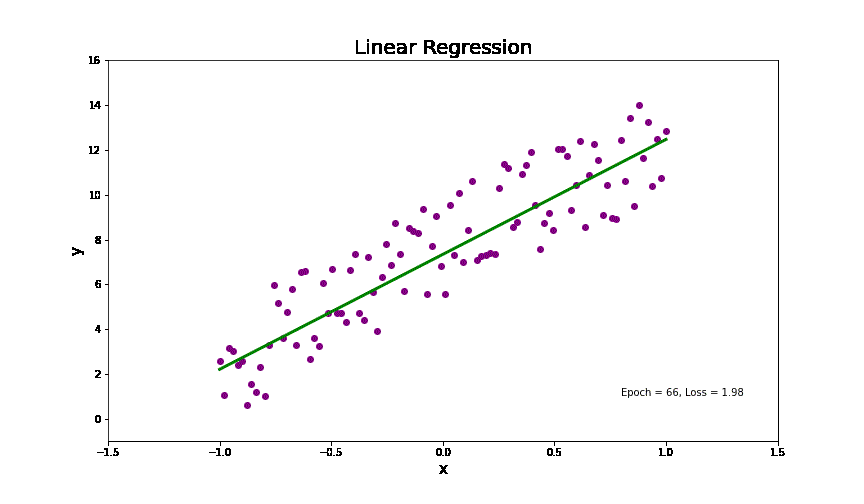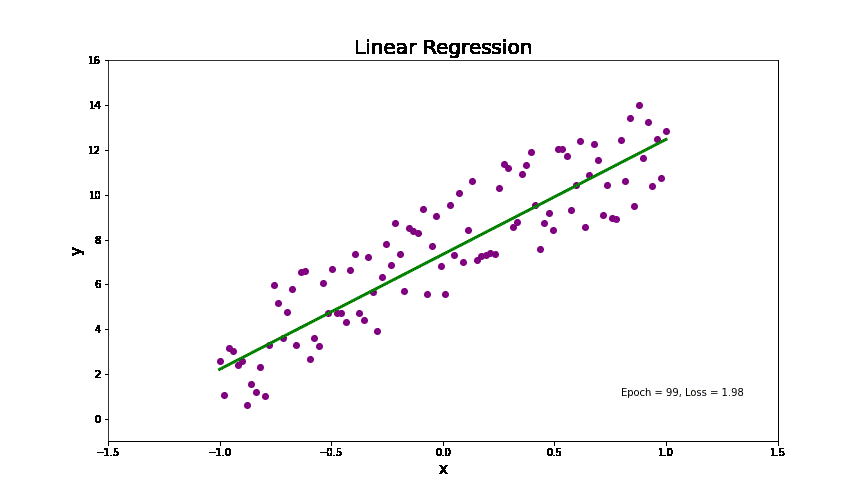
线性回归分析简单来讲就是在一个线性分布的数据中,找到一个线(如图中的绿色的线),来拟合整个数据分布。代码中(9行到12行),我创建了一个线性分布的数据根据下面的式子(其中我加了一些高斯噪音,为了模拟真实生活中的数据)。
所以要拟合的的函数就是:
看到这个公式,很多同学会想到:
没错,这就是我们小学课堂上面讲的一元一次函数。是不是瞬间感觉高大上的线性回归也不过如此。但是,实际生活中的数据并不是完美落在这条线上面的,而会像动图中的点一样,分布在这条线的两边。所以,给定一些点(训练数据)去找这条线的方法(模型训练)就是,找到一条线离各个点的距离最小。这里,衡量一条线到所有点的距离就叫损失,而去找离各个点距离最小的线就是去找损失函数最小的解,也就是估计上面公式中参数(b, k)。其最终的高维的数学表达式如下:
通过训练得到损失函数最小的解,就有可能得到原始函数(假设)的参数。最后可以将下面式子中所有的参数都换成了具体的数字:
上面提供的代码例子其实有很多缺点。第一,不易维护。第二,不易拓展。第三,不易开发。所以,我们这里需要把,数据的载入封装起来,通过继承torch.utils.data中的Dataset来实现。
import 然后再把模型的建立也封装起来,通过继承torch.nn中的Module来实现。
import 最后代码就被精简成这个样子(这里,我去掉可视化数据的代码)
#.... Omit above visualization code!
这样修改的代码可以完美解决上面我说的三个问题:不易维护、不易拓展、和不易开发。同时,通过调整DataLoader中参数batch_size的大小,可以随意切换训练方式(梯度下降、随机梯度下降、和小批量随机梯度下降)。最后,有一些基础知识的同学就能看出代码里还有一个问题:缺少验证数据集和测试数据集。这里,我只是像展示PyTorch这些基本函数的用法。如果,同学有兴趣,可以自己创造一个验证数据集和测试数据集,将其加入到整个模型训练和测试的流水线中。
3.2.2 例子-逻辑回归
经过上一个例子,同学们应该对PyTorch的基本函数有所了解了。现在,我们就换一个例子,用逻辑回归来进一步了解PyTorch的基本函数。
机器学习有五大问题:分类、回归、聚类、降维、和强化。除了回归分析的应用最广,分类问题也是生活中遇到最多的问题之一。与回归分析不同,分类问题的目标是根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类。根据类别的数量还可以进一步将分类问题划分为二元分类和多元分类。同样,在分类问题中,最基本的算法就应当是逻辑回归了
这里,我们用到一个最简单的分类问题数据集-安德森鸢尾花卉数据集。同学们可以从这个链接下载这个数据集。同样,这里我需要把数据的载入封装起来,通过继承torch.utils.data中的Dataset来实现。
import 然后再把模型的建立也封装起来,通过继承torch.nn中的Module来实现。
import 最后完整代码如下:
import 上面的代码就是用PyTorch中的基本函数来解决一个逻辑回归问题。在LogisticRegression这个封装好的类里面,用到torch.nn中的Linear来先构建一个线性算子(行6),加上一个Sigmoid函数(行7),来构建一个逻辑回归算法模型。从实现逻辑回归算法模型的过程中,同学们可以清楚的看到逻辑回归就是线性回归套了一个Sigmoid函数的马甲。也可以说是线性回归站到了线性回归的肩膀上,看清楚了分类问题的本质。
逻辑回归被很多人认为是处理回归问题的算法,但其实都被他的名字所欺骗。这个算法其实是用来处理分类问题的,为什么叫逻辑回归不叫逻辑分类。其原因是可以从统计和数学两个角度来解释其联系。从数学上,逻辑回归本质上是线性回归的延申,线性回归加了一个Sigmoid函数来处理线性可分的问题。从统计上,两个模型都属于广义线性模型,线性回归模型中要假设随机误差等方差并且服从正态分布,而逻辑回归需要假设随机变量的参数服从伯努利分布
同样,我用torch.optim中的SGD建立一个优化方法(行32)。最后用,torch.nn中的BCELoss来定义损失函数(行31)。利用Pytoch训练定义好的模型和参数非常简单,只需要七行就可以搞定(上面行36到行42的代码)。剩下的代码都是做可视化用的,这个同学不需要理解。
为了让同学更直观的看到训练过程,我将输入变量(特征值)的维度设置成2维,并且处理的是一个二元分类问题。并且,我把整个训练过程可视化出来。
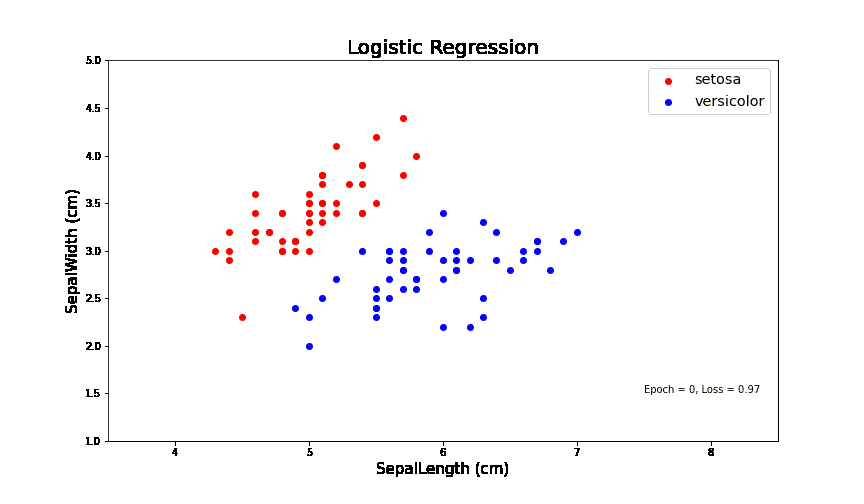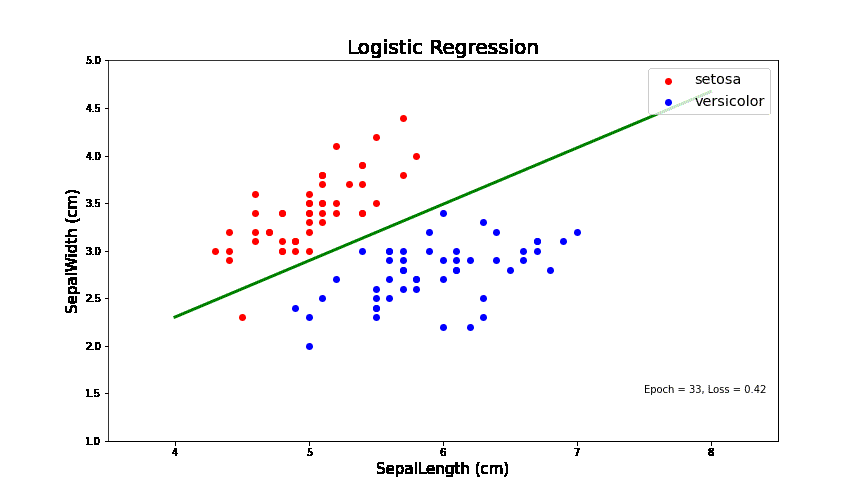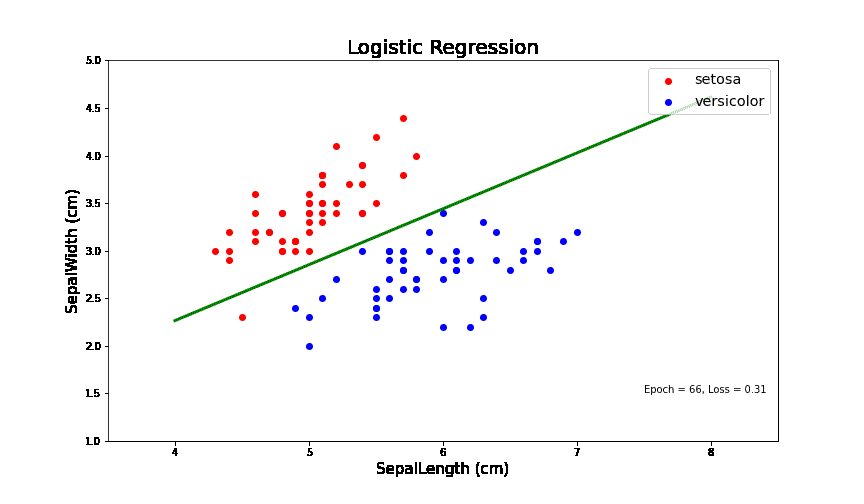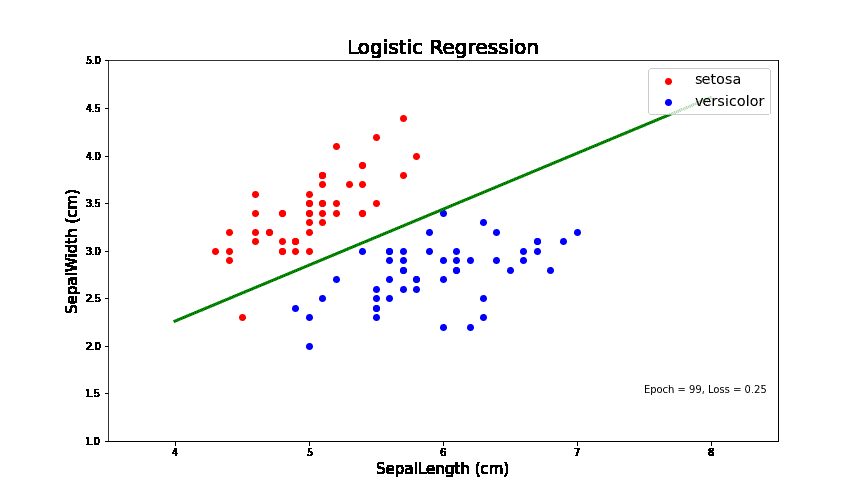
逻辑回归问题简单来讲就是在一个线性可分的数据中,找到一个线(如图中绿色的线),可以把两类数据分开。在IrisData这个封装好的类中,我抽取了两种花的数据(Setosa和versicolor)。
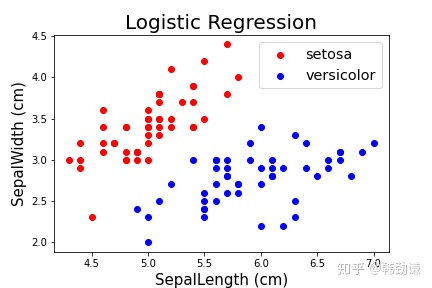
其中,红色点代表一类花,蓝色的点代表另一类花。萼片长度为X轴和萼片宽度为Y轴。从中的数据可以看出,这个数据在这两个维度上是线性可分的。
第二节的公式(1)可以作为二元分类问题的损失函数。那么,逻辑回归的原始函数(假设)和参数应该怎么表达呢?其数学公式如下。
从逻辑回归的数学表达式子中,可以看出其输出的是可能性(因为Sigmoid函数的值域是0到1)。所以需要进一步根据下面公式,输出具体的判定(0代表不是或者1代表是)
最后,同3.2.1一样,这里缺少验证数据集和测试数据集。感兴趣同学有兴趣,可以自己分一个训练数据集、验证数据集、和测试数据集,然后将其加入到整个模型训练和测试的流水线中。
3.2.3 例子-神经网络
PyTorch是一个非常优秀的深度学习框架,而深度学习可以说是最简单的神经网络的延申。所以,我这里就用一个简单的神经网络做为例子,继续帮助学生理解这些PyTorch的基本函数。
人工神经网络是一种计算模型,启发自人类大脑处理信息的生物神经网络。其本质上是多层感知器,也就是多层多路输出线性回归加一个激活函数。通过这个激活函数,每一路的输出最终形成一个神经元。这里,同一级众多的神经元最后形成了一层神经网络。其中第一层叫做输入层,中间所有层叫做隐藏层,最后一层叫做输出层。由于神经网络可以拟合任何函数,所以只需要将最后一个输出层替换成不同的结构,就可以处理各种机器学习问题
下面我们就用PyTorch是实现一个神经网络来处理回归分析。由于神经网络可以拟合任何函数, 我这里利用一个非线性函数生成一个非线性的数据分布,看看这个神经网络可否帮我拟合这个函数。首先,我们还是需要将数据的载入封装起来,通过继承torch.utils.data中的Dataset来实现。
import 然后再把模型的建立也封装起来,通过继承torch.nn中的Module来实现。
import 最后完整代码如下:
import 上面是的代码,我用PyTorch中的基本函数来构造一个简单神经网络,去解决复杂的非线性回归分析。在NeuralNetworks这个封装好的类里面,利用torch.nn中的Linear构建一个输入层(行6),利用torch.nn中的Linear构建一个隐藏层(行7),利用torch.nn中的Linear构建一个输出层(行8)。同时,需要定义一个激活函数,利用torch.nn中的ReLU来实现(行9)。最后在forward函数中,把定义好的各种层和激活函数依次串起来。
接下来,我用torch.optim中的Adam建立一个优化方法(行29)。最后用,torch.nn中的MSELoss来定义损失函数(26行)。利用Pytoch训练定义好的模型和参数非常简单,只需要七行就可以搞定(上面行34到行40的代码)。剩下的代码都是做可视化用的,这个同学不需要理解。
为了让同学更直观的看到训练过程,我将输入变量(特征值)的维度设置成1维。并且,我把整个训练过程可视化出来。
在3.2.1中,我解释过线性回归分析的算法。同理,这里用神经网络做回归分析,只需要将最后一个输出层改成输出的具体数值即可。这样就可以用来分析一个非线性分布的数据。从而找到一条线(如图中的绿色的线),来拟合整个数据分布。在ComplexeData这个封装好的类中, 我用下面的式子(其中我加了一些高斯噪音,为了模拟真实生活中的数据),创造了一个非线性的数据分布。
所以要拟合的的函数就是:
因为还是回归分析,所以损失函数还是去衡量一条线到所有点的距离就叫损失。也就是,给定一些点(训练数据)去找这条线的方法(模型训练)就是,找到一条线离各个点的距离最小。所以其数学表达式还是:
由于神经网络是一个黑盒子,我们无法具体知道可能得到原始函数(假设)会是什么。所以,原始函数的参数也不知道是什么。但是我们每次训练好神经网络会产生一个所有神经元的权重信息。大部分情况下,这些权重信息并不能说明什么问题(现在很多研究开始尝试可视化这些权重信息,并且去尝试解释神经网络认为哪些是重要的信息)。
在这节给出的例子中,我们知道生成这些数据的原始函数是什么。同时,这些数据的维度只有一个。所以,通过上面可视化训练过程,我们可以很直观的知道,这个神经网络是很好的拟合了原始函数(假设)。
在实际生活中,很多非结构数据过于复杂,使得我们无法得知其真实的分布应该是什么。所以,我们无法正确的猜测其假设。因此,就需要一个更加庞大的训练集、验证集、和测试集去判定一个模型表现的好与坏。但是,即使有些神经网络在测试集上表现很好,也不会代表这个模型在实际生产和生活中表现的很好。个人认为,在实际生产和生活中,数据的分布可能不止一种。同时,没有通用的方法可以判定,这个数据或这类数据是什么什么分布。最重要,数据的收集过程和数据的标记会不会有很大的人为偏差?
构建神经网络还有PyTorch还提供了另一种更加简单的方式。利用torch.nn中的Sequential可以将NeuralNetworks这个类替换掉。所以,我们只需要一个ComplexeData的类负责加载数据集就好了。
import ComplexeData没有什么改动。但是,NeuralNetworks被换成了如下(这里,我去掉可视化数据的代码)
#.... Omit above visualization code!
这两种建立神经网络都一样,但是不同的方法有不同的用户使用群。同理,torch.nn.functional 和 torch.nn也类似。另外,torch.nn.init为科研人员提供了更为自由的权重初始化API。最后基础函数中的torch.autograd提供了类和函数用来对任意标量函数进行求导。要想使用自动求导,只需要对已有的代码进行微小的改变,并且将所有的tensor包含进Variable对象中即可。
3.2.4 深度神经网络
深度神经网络可以看作是神经网络的进一步延申。深度神经网络拥有更多隐藏层,每一层的神经元也更多。同时,深度神经网络还有更复杂的结构,来处理各种不同的数据(例如,音频,文本,图片)。例如,卷积神经网络(CNN),专门用于处理图片数据;而循环神经网络(RNN),则更适合去处理文本数据。现在随着科技的发展,以及各行各业对AI的需求加大。更多类型的数据变的越来越流行(例如,点云),对应的深度神经网络结构也有很大变化。如果要继续细化深度神经网络,还可以根据所处理的不同问题(例如,音频的音频分类,文本的机器翻译,图像的目标检测),在结构上有千变万化的组合。
最后,很多机器/深度学习的知识搞死记硬背是行不通的。需要自己同手推导公式,自己动手用代码实现公式。那么,PyTorch做为这么优秀的开源学习软件,为什么不去自己试试呢?用它来实现各种算法和网络,会不会是一件很酷的事情呢?
4 站在巨人肩上眺望
根据第三节中的三个例子,希望同学们能对PyTorch有一个大致的了解。同时从上面的三个例子中,可以看出PyTorch作为优秀的深度学习的框架,在搭建各种各样的深度神经网络可谓是非常简单。这里,也希望同学可以根据所处理和研究的问题,搭建起属于自己的深度神经网络。
分析完基本函数,我们再来看基本数据结构。之前我说过,PyTorch之所以如此成功,是因为它站在了NumPy的肩膀是。为什么这个说呢?PyTorch中储存数据的基本单元叫tensor,而NumPy叫做ndarray。
import 在上面的例子中,PyTorch的tensor不仅可以和NumPy中的ndarray相互切换,访问数据类型的函数都是一样的。更重要的是,NumPy中有的对ndarray的各种操作,PyTorch中的tensor也都一摸一样。这时很多同学就会反问了:“这不是基本操作吗?”对,正式因为基本操作,PyTorch就直接拿来一用,这不香吗?虽然,NumPy底层是用C实现的,而PyTorch大多功能是用C++实现的。但是,用什么方式和语言实现都是次要,关键是PyTorch模仿了很多NumPy东西。比如功能设计的非常人性,运算速度快,误差极小,从数据结构到各种算法的优化方式。最最最重要的是ndarray支持并行化运算(向量化运算),而且底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制。这些NumPy的优点使得PyTorch去实现很多设计理念变的非常容易。所以站在巨人肩膀上的方式,不是简单的复制粘贴被人的东西;而是,借鉴巨人的设计思路,模仿巨人的实现方式。
最后PyTorch站在NumPy的肩膀上,一举横扫诸深度神经网络框架。那你是否想站在PyTorch的肩膀上,去探索深度学习的世界?
5 最后寄语
大量练习写PyTorch代码!很多东西靠看是学不会的,自动动手写一写。哪怕重写一些教程都比死记硬背的要好的多。
在创业公司工作,每年都会遇到一到两个大型开源项目,时不时还有很多小的开源项目。在FLAG工作也一样,虽然基本都在做公司的东西,但是也需要经常去学习和参考别人是怎么做的,有什么新的设计理念,有什么新的技术,有什么新功能需要实现。所以,希望同学可以掌握或者总结一套自己的学习方法,去面对未来高速发展的社会。
再次感谢这些做开源项目的人!致敬!
欢迎去我的个人网站,了解更多我做的项目和实验。
Weikun Han's Websiteweikunhan.github.io
6 学习资料
PyTorch学习文档 PyTorch Documentationpytorch.org PyTorch学习教程 PyTorch Tutorialspytorch.org 深度学习 Deep Learning with PyTorchpytorch.org


7 引用
- PyTorch: An Imperative Style, High-Performance Deep Learning Library, Adam Paszke et al., NeurIPS, 2019 - paper link
- Regression with Neural Networks in PyTorch, Ben Phillips, Medium - link














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









