









 本文介绍了一种使用Python爬虫抓取微博数据的方法,并通过词频统计生成词云图来直观展示抓取到的数据内容。
本文介绍了一种使用Python爬虫抓取微博数据的方法,并通过词频统计生成词云图来直观展示抓取到的数据内容。
import csv
import requests
import json
import re
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
import PIL.Image as Image
search=input('请输入关键词:')
url='https://m.weibo.cn/api/container/getIndex?type=all&queryVal={}&featurecode=20000320&luicode=10000011&lfid=106003type%3D1&title={}&containerid=100103type%3D1%26q%3D{}'.format(search,search,search)
def cookie():
with open('cookie.txt','r') as f:
cookies={}
for line in f.read().split(';'):
name,value=line.strip().split('=',1)
cookies[name]=value
return cookies
headers = {
'User-Agent': r'xxxxxxxxxxxxxx'
r'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
'Referer': 'https://m.weibo.cn',
'Connection': 'keep-alive'
}
results=[]
links=[]
i=1
b=[1]
weibo=0
while True:
if len(b)==0:
break
else:
url_1=url+'&page='+str(i)
print(url_1)
r =requests.get(url_1,headers=headers,cookies=cookie()).text
a=json.loads(r)
b=a['data']['cards']
i+=1
for j in range(len(b)):
bb=b[j]
try:
for c in bb['card_group']:
try:
d=c['mblog']
link='https://m.weibo.cn/api/comments/show?id={}'.format(d['mid'])
links.append(link)
if d['isLongText']==False:
text=d['text']
pattern =re.compile(u"[\u4e00-\u9fa5]+")
text=re.findall(pattern,text)
else:
text=d['longText']['longTextContent']
results.append(text)
weibo+=1
except:
continue
except:
continue
print('共抓取{}条记录'.format(weibo))
pl=[]
for url_2 in links:
r =requests.get(url_2,headers=headers,cookies=cookie()).text
a=json.loads(r)
try:
num=a['data']['total_number']
j=0
for i in range(num//10+1):
url_3=url_2+'&page='+str(i+1)
r =requests.get(url_3,headers=headers,cookies=cookie()).text
a=json.loads(r)
b=a['data']
try:
c=b['hot_data']
for i in range(len(c)):
d=c[i]['text']
pattern =re.compile(u"[\u4e00-\u9fa5]+")
d=re.findall(pattern,d)
j+=1
pl.append(d)
print(d)
except:
c=b['data']
for i in range(len(c)):
d=c[i]['text']
pattern =re.compile(u"[\u4e00-\u9fa5]+")
d=re.findall(pattern,d)
j+=1
pl.append(d)
print(d)
print('%s条评论'%j)
except:
print('无评论')
def word_cloud(results,search):
siglist=[]
for ii in results:
try:
signature=ii.strip().replace('http:t.cn','').replace('的','').replace('地','').replace('了','').replace('是','').replace('在','').replace('/','').replace('emoji','')
rep=re.compile('1f\d+\w*|[<>/=]')
signature=rep.sub('',signature)
siglist.append(signature)
except:
for jj in ii:
signature=jj.strip().replace('http:t.cn','').replace('的','').replace('地','').replace('了','').replace('是','').replace('在','').replace('/','').replace('emoji','')
rep=re.compile('1f\d+\w*|[<>/=]')
signature=rep.sub('',signature)
siglist.append(signature)
text=''.join(siglist)
wordlist=jieba.cut(text,cut_all=True)
word_space_split=" ".join(wordlist)
coloring=np.array(Image.open("1.jpg"))
my_wordcloud=WordCloud(background_color='white',width=2400,height=2400,max_words=2000,
mask=coloring,max_font_size=60,
random_state=42,scale=2,
font_path="simfang.ttf").generate(
word_space_split)
image_colors=ImageColorGenerator(coloring)
plt.imshow(my_wordcloud.recolor(color_func=image_colors))
plt.imshow(my_wordcloud)
plt.axis('off')
plt.show
my_wordcloud.to_file('{}.png'.format(search))
word_cloud(pl,results)
word_cloud(pl,search)这里我爬取了有关“母亲节”的微博,并生成词云
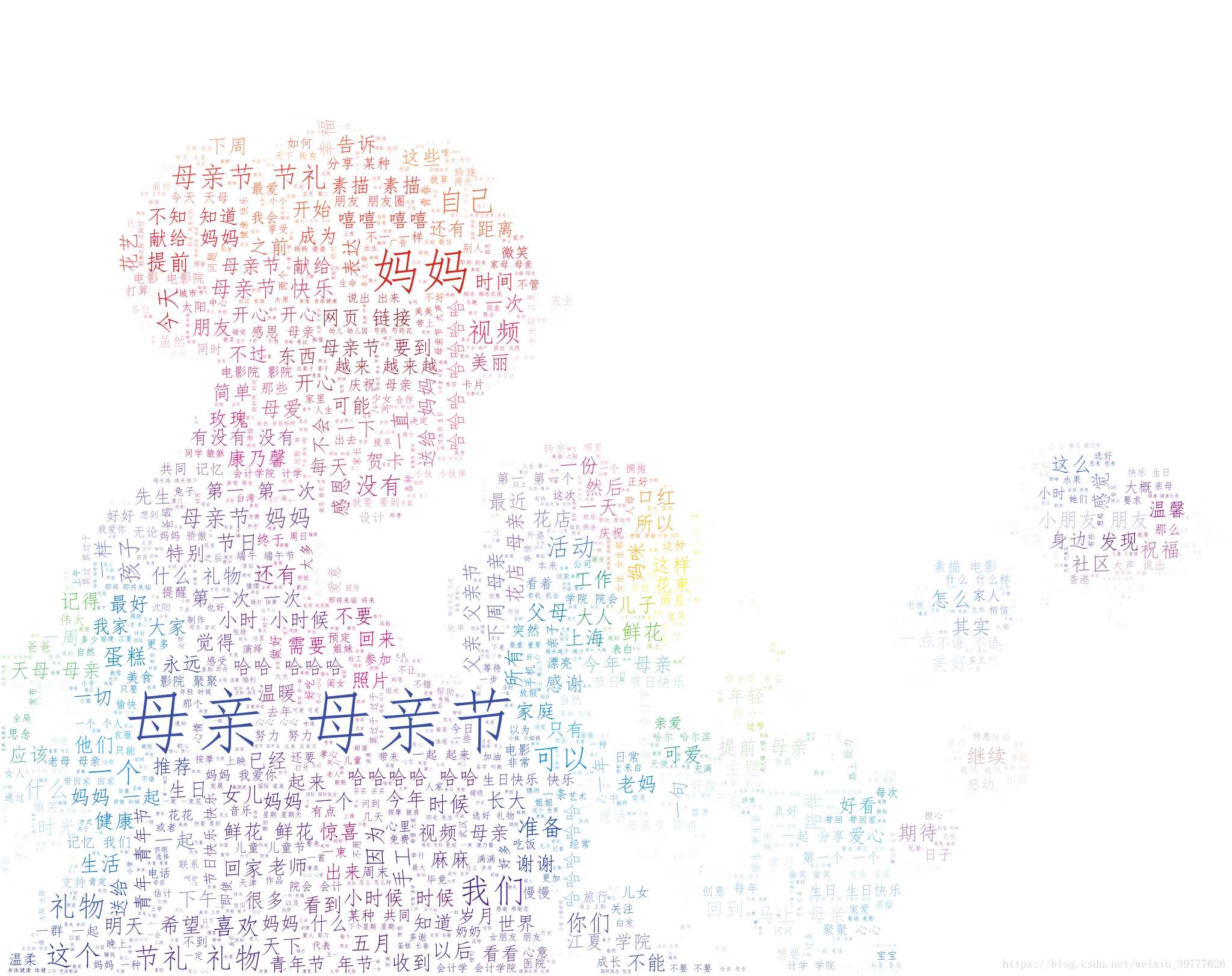


















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









