





我是一只正在迭代的分析狮天天。
最近看了B站UP主好好玩量化的视频《回答沈逸老师,新冠疫情下越民主死越多吗?》,用到的分析方法就是线性回归,决定猛学习一下,再来评判视频里的结论。

图片来源:B站视频截图
提前预习

统计学
定距、定序、定类
线性回归方程
复相关与决定系数
偏相关系数、标准化偏相关系数
残差
SPSS操作
分析-回归-线性回归
图形-图表构建器
01 线性回归的应用场景
线性回归,首先应用于定距变量之间,本质上是分析一个因变量和一组自变量之间的相关关系,既可以解释,也可以做预测。
沈逸老师提出的,新冠疫情下越民主死越多吗?就是一个用线性回归解释相关性的问题。
再举几个商业应用的简单例子:
1、根据投资规模、员工数量,对生产规模进行预测;
2、探索潮牌店的收入,与人均收入水平、年轻人数量的关系;
3、价格、促销、季节因素等对销量的影响;
……
02 重要!线性回归的适用条件
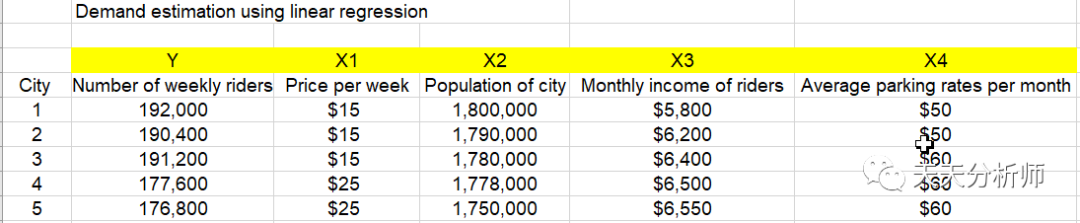
【案例】今天用到的是一个分析交通运输需求的数据集。在这个案例中,需要预测的是因变量Y“每周乘客数量”,自变量分别是X1至X4。
国内的小伙伴,可以直接在bing国际版 or 搜狗英文里,搜索第一个变量的名称“Number of weekly riders”,就可以找到很多提供该数据集的网址,自行下载就好了。
【适用条件】
根据我总结的学SPSS的黄金三步法,区分场景-适用的统计学条件-操作及报告解读
对于回归分析,适用条件这一part特别重要,一定要拿小本本记下来!
1、最重要!自变量与因变量之间是线性关系,严格要求,如果不满足,可以做非线性回归,不要硬上;
2、样本量要足够,经验值是希望分析的自变量数量的20倍。比如根据理论,有5个变量是必须进入模型的,还有6个是可以考虑的,即使最后用不上,希望分析的自变量数量也是11个,20倍就是最少220个样本;案例是一个练习用的数据集,有4个自变量,但只有27个样本量,凑合用;
3、因变量和自变量都是定距变量。有时候,定序自变量会作为定距变量处理,或者和定类变量一样,变换为虚拟变量(哑变量)放入模型;
4、残差的独立性、正态性和方差齐性,残差是估计值与真实测量值之间的差,所以要在构建模型后,才能计算残差,再分析、调整;如果只是做相关关系的探索,不做预测,这一条可以放宽;
5、强影响点的诊断;
6、自变量的多重共线性问题,即自变量之间有较强的相关性,这条很常见,要根据理论框架和严重程度做取舍。
03 建模的流程
回归分析的SPSS操作特别简单,但相应的准备、诊断、调整流程比较复杂,我先按教科书上的标准流程分享,日后有机会多应用,再分享经验。
3.1线性关系的考察
方法:每一个自变量与因变量的散点图
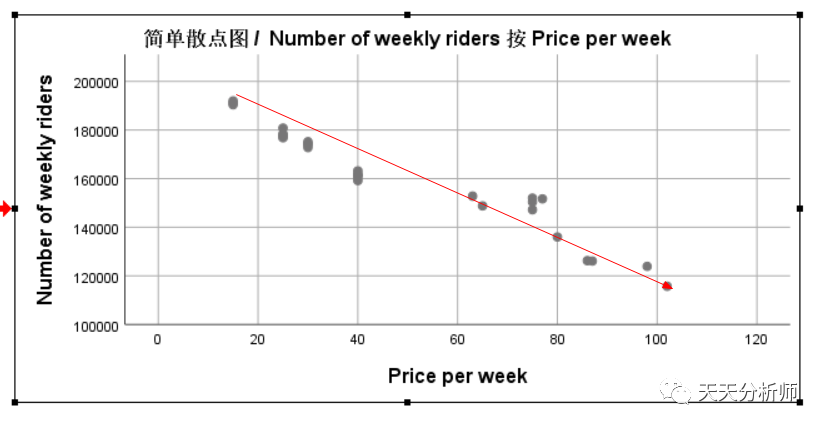
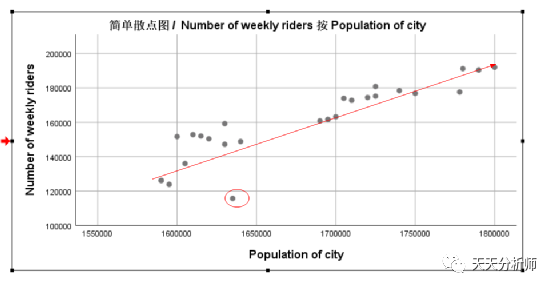
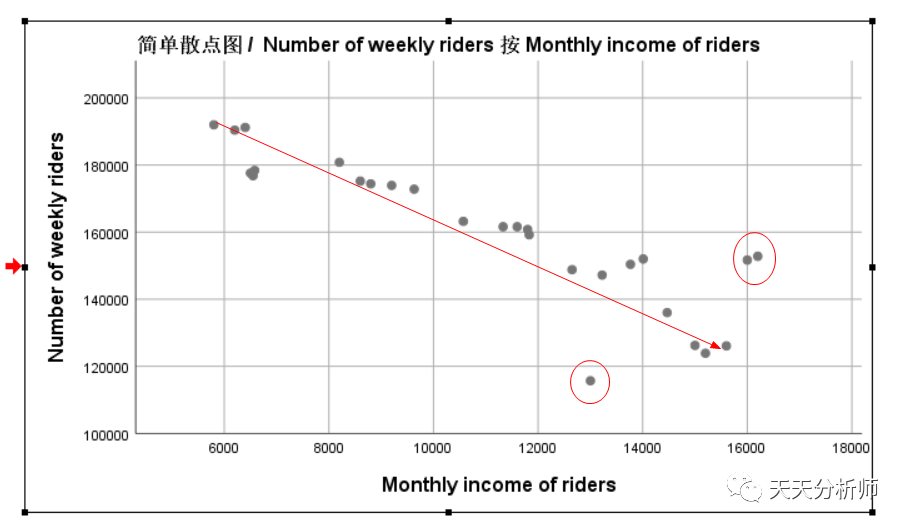
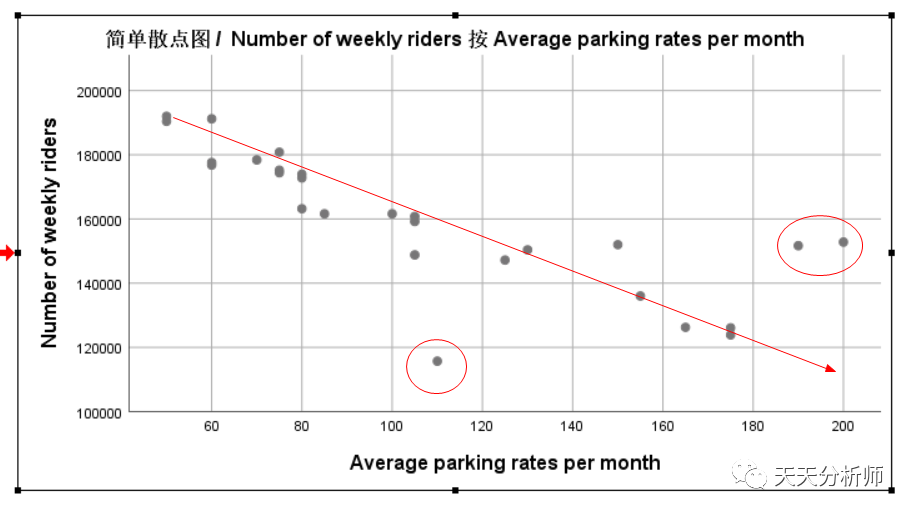
案例数据里有四个自变量X1-X4,与因变量的关系基本都满足线性关系,存在的问题主要是个别数据离拟合曲线有点远,可能是强影响点,建模时会进一步考察。
X1
X2
X3
X4
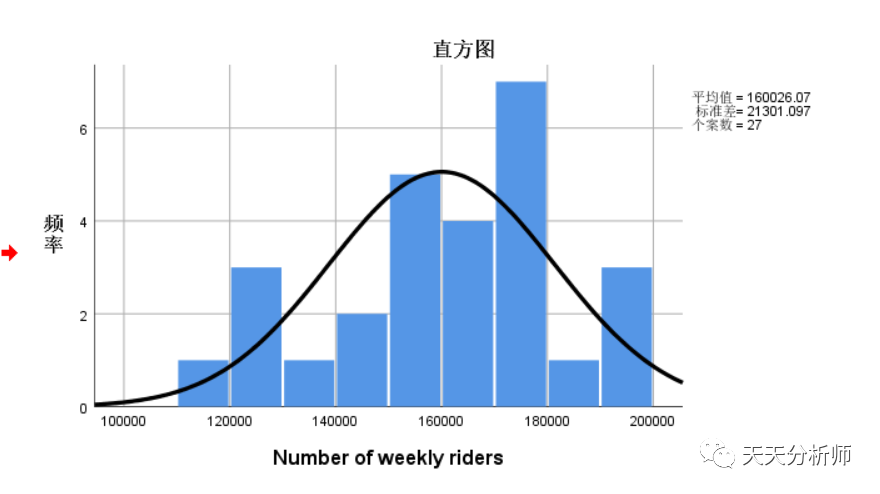
3.2因变量的分布观察
前面提到的适用条件里,有一条是因变量残差的正态性,在建模前,也应该先看一下因变量的分布,经验告诉我们,非常偏态的数据,残差的正态性也不会太好。
3.3自变量的筛选
下面就进入建模流程了,把哪些自变量放到模型里呢?
在问卷调研中,数据的采集都是有“预谋”的,也就是说从在设计问卷时,就需要考虑要做哪种分析,哪些问题会作为自变量放进模型里。
“预谋”的根据首先是已有模型,模型就是分析问题的方法,很多国外的调研公司之所以牛,模型的积累和应用是重要原因。年轻人,有机会还是要进大公司,多见识些模型。
其次,可以根据理论的操作化探索新模型,比如社会学里讲财富、权力和声望是社会分层的三个关键维度,在问卷调研里,就可以转换为收入、职业、教育程度、社会影响力等指标建模。所以,数据分析人员也要加强理论学习,并参考一些学术模型。
最后,才是根据自变量的重要性,做筛选和调整。
SPSS里有自动筛选的功能,即“步进”的方法(或者称逐步回归法),把变量放入模型,但有30%+概率不是最优方程,而且也面临如何解释模型的问题,所以教程上还是建议手工选择自变量。
没有找到这个案例的背景说明,我个人理解,应该是预测公共交通的乘客数量(如果不对,欢迎指教)
案例数据集里放了4个自变量,来探索和因变量 Number of weekly riders的关系。
X1→Price per week
X2→Population of city
X3→Monthly income of riders
X4→Average parking rates per month
04 建模后的解读、诊断和调整
根据残差分析、强影响点、多重共线性的诊断和调整,才是建模的核心。下面就进入重头戏的学习。
4.1模型的解读
红框里的方法先用输入法,将自变量和因变量都选进来即可
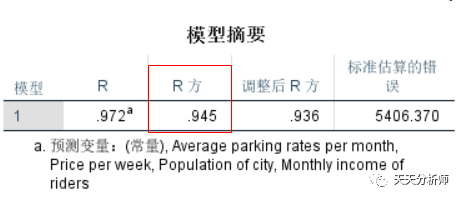
第一步,看决定系数。
R平方的意思是因变量的变异能够通过回归关系被自变量解释的比例。
决定系数的大小决定了模型的好坏。如何判断R平方的大小呢?很不幸,没有统一的标准,而且各行业的差距很大,医学上,99%都不够,做股市分析20-30%就很牛了。
案例数据集的结果,R方达到94.5%,是个不错的结果。
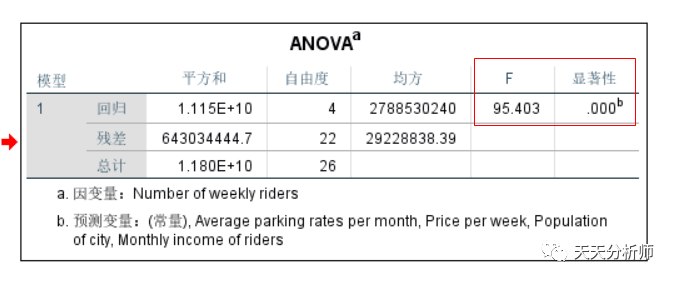
第二步,看模型的假设检验结果。
方差分析的H0假设是,所有X的偏相关系数都是0,这里的结果是拒绝零假设,即至少一个系数不为0。
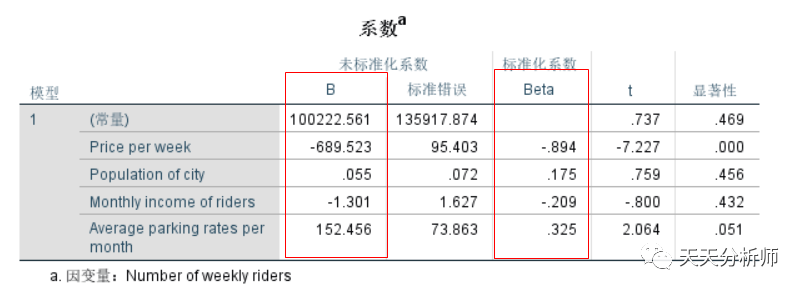
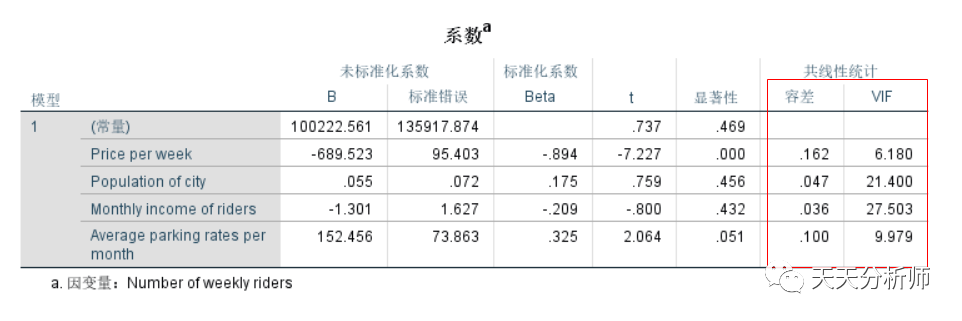
第三步,做自变量重要性的比较。
看下图B值那一列,是方程里各自变量的系数,称为偏相关系数,即控制了其他自变量,与因变量的相关关系。因为有量纲的影响,接下来会用标准化后的偏相关系数beta,来衡量自变量的重要性。
在这个案例中,X1(Price per week)的Beta值最高,其次是X4(Average parking rates per month),最后是X3和X2。
看每一行后面的假设检验,X2和X3的显著性值分别为0.456和0.432,>0.05,即接受H0,系数=0,不相关。所以,调整模型的时候可以考虑排除这两个自变量。
结合实际场景的解读,影响乘客数量最重要的因素是票价,负相关,票价越高,乘车人数越低。然后是替代方案的成本,即停车费,正相关,停车费越高,乘车人数越高。听起来也比较合理。
4.2残差分析
如果只是做相关关系的探索,不做预测,残差检验可以放宽。反之,则需要严格的残差检验。
第一步,独立性。
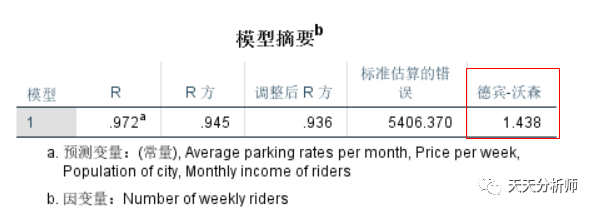
在定义自变量、因变量的界面,统计选项,勾选Durbin-Watson检验。
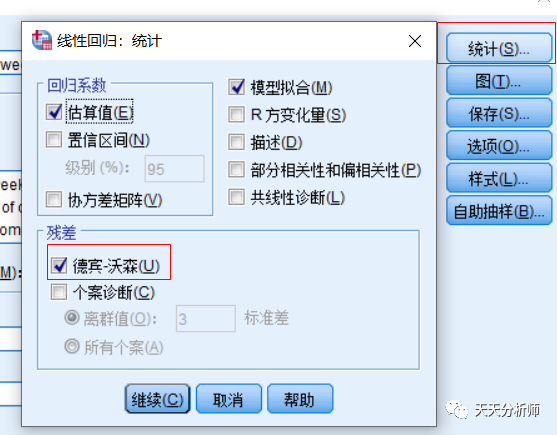
Durbin-Watson检验值在0-4之间,经验值在1-3之间满足独立性,超过这个区间就不太靠谱了。案例结果显示,数值为1.438,满足独立性,符合建模需求。
第二步,正态性。
根据图形来考察。图形选项-勾选标准化的直方图和P-P图。
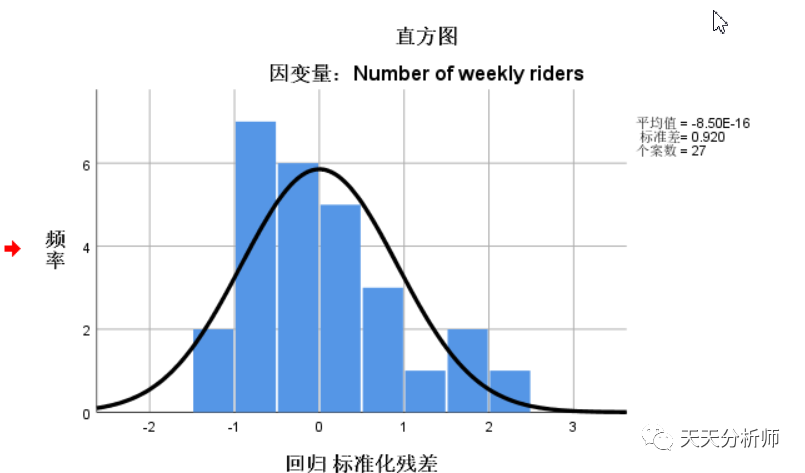
先看直方图,形态比较符合,数值分布在3和-3之间。
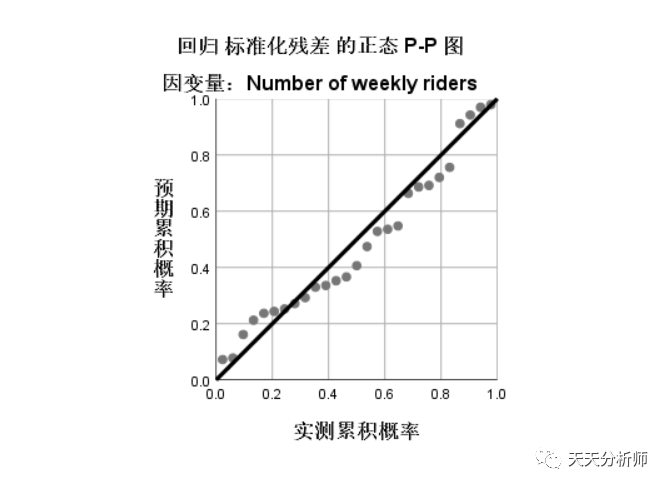
再看P-P图 ,如果满足正态性,实测累计概率与预期累计概率应该一致,即散点应该分布在主对角线上。考虑到样本量比较小,案例结果在可接受范围,理想情况应该是贴合一些。
第三步,方差齐性
还在图选项里,画一张X为标准化预测值,Y为标准化残差的散点图。
双击图表,添加一条坐标为0的参考线。
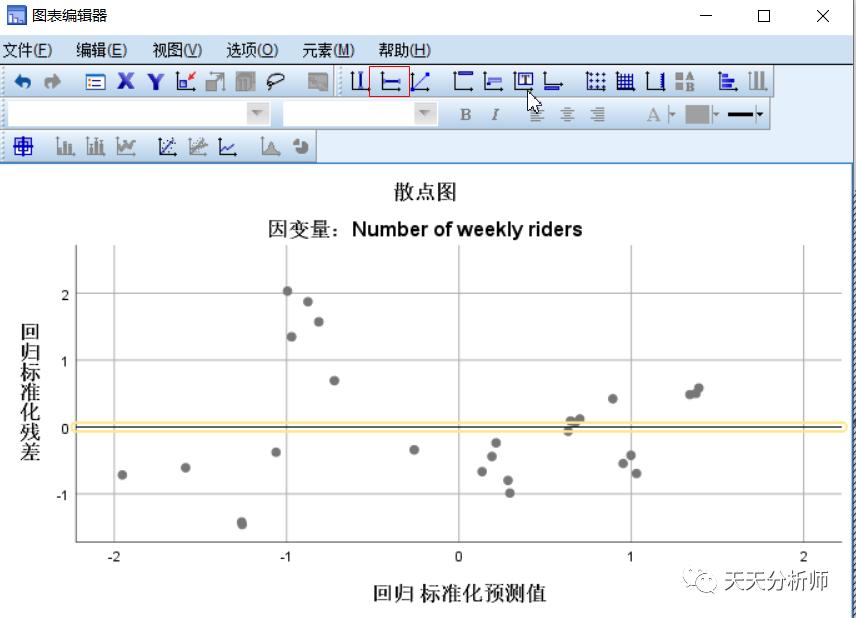
教科书上给出了三张残差散点图的常见情况。
案例的数据基本符合标准图,散点在0附近上下均匀分布,不超过正负3,也没有明显的分布规律。其中不超过正负3就是强影响点的考察。
书中的第二张图属于方差不齐,即随着预测值越来越大,方差越来越大,需要做变量变换(超纲啦,以后慢慢学啊)
第三张图,说明回归方程里缺少高次项,比如平方项。即本来是曲线方程,但现在做成了线性方程,所以隐藏的曲线关系就体现在残差里了(因为残差是预测值和真实值之间的差)
4.3强影响点
在前面的残差散点图观察中,提到超过正负3的点,就是非常可疑强影响点。可以在统计选项-个案诊断中设置,然后输出案例号。
对强影响点的一般处理方法有几种:
1、先检查数据是否录入错误;
2、如果有合理的理由,证明样本没有代表性,可以直接剔除不放入模型。样本越大,删除的影响越小。
3、把这个样本的数据放入和拿出模型,看一下对模型的影响大不大,如果不大也就无所谓了。
4、用更稳健的回归分析方法,降低强影响点的影响。(这条超纲啦,以后慢慢学啊)
4.4多重共线性
还是在统计选项里,为了让大家一步步理解,所以把残差、强影响点和多重共线性分开讲了,实战中可同时在统计选项里设置,然后一起看结果。
容差的含义,用案例的情况举例,假设X1为因变量,X2-X4为自变量的回归方程的决定系数为R1平方。容差=1-R12。那么,容差越小,说明多重共线性越严重,所以经验值要大于0.1。
VIF是容差的倒数,经验值是<< span="">10。
接着看共线性诊断的表
特征根(翻译成了特征值):原理是对模型的自变量和常数项提取主成分,如果前面的特征根比较高,后面趋于0,则提示多重共线性比较严重。
条件指数(翻译成了条件指标):如果多个指数值>30,提示有问题。
后面的方差比例,如果某个主成分解释其他各项的比例较高,提示有问题。
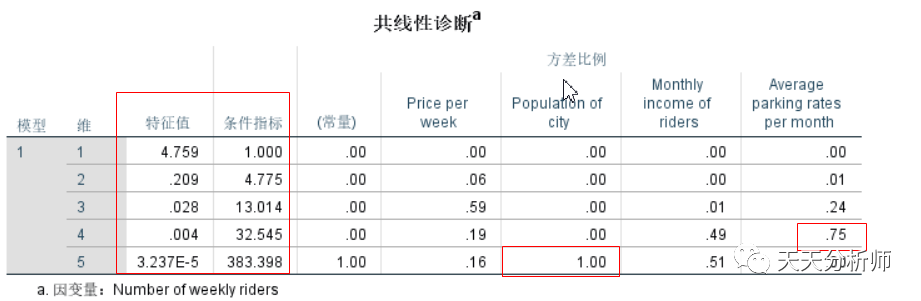
综合以上标准,本案例数据的多重共线性是比较严重的。
可以用逐步回归(stepwisse,翻译成步进)的方法自动筛选自变量,将解释力较小的自变量排除在外。在这个案例中,会自动把X2-X4都排除了,只保留了X1。即只有票价的高低对乘客数量的多少有很大影响。
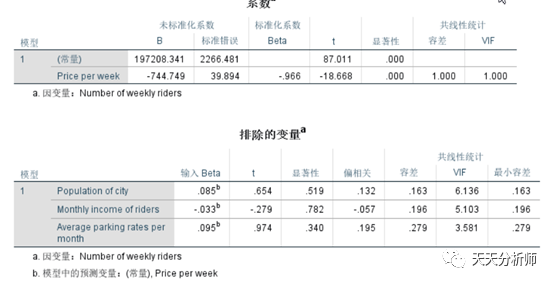
多重共线性的问题很普遍,在实际数据的诊断和和理论框架之间,应该更听从理论的召唤,毕竟模型要可解释。

最后,来回答沈逸老师的问题,新冠疫情下越民主死越多吗?
根据UP好好玩量化的回归模型,R平方太小了,只有0.182(虽然做成这样已经很牛了),所以我觉得这个结论不能成立。
不过这位UP主找数据,做分析的思路还是很赞的,大家可以找来康康~
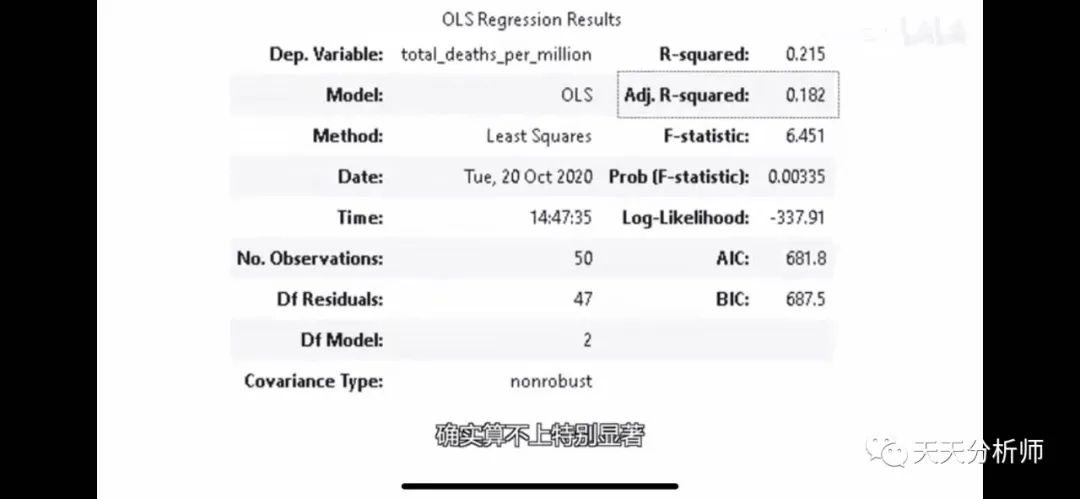
图片来源:B站视频截图
参考书
张文彤《SPSS20.0统计分析高级教程第2版》
李沛良 《社会研究的统计应用》
软件版本 | SPSS 25.0
题图 | Pexels
















 6720
6720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









