






作者:浩南
目前原来越多的客户考虑将生产中的小型机替换为X86服务器。通常会进行小型机和X86服务器的性能对比测试,途中可能测出预期以外的性能差异,却无法解释其原因,就像今天这个案例,项目组一直念叨换了台性能太差的主机。
一、问题描述
某大型国有银行的一套业务系统,近期由小型机迁移至X86环境。据项目组反映部分DB_LINK查询比原来小型机慢。这不对啊,相同的存储,CPU也更多,内存也更大。
于是DBA随手挑出一张大表,做个简单的COUNT(*)查询,发现Linux比AIX慢了6倍。重复执行多次,结果也类似。难道委屈项目组了,这套X86就是比小机慢?于是找上中亦,深入分析下问题原因。
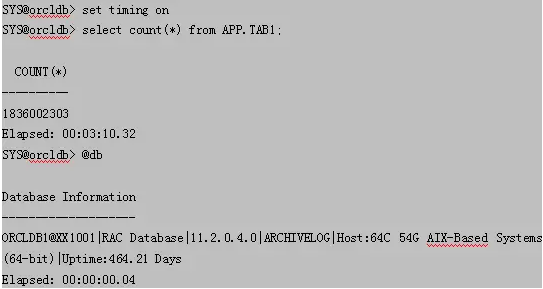
执行时间对比
AIX下执行时间为3分10秒
QQ截图20171214141123.png
Linux下执行时间为19分3秒

QQ截图20171214141236.png
相同SQL语句在,AIX环境下执行时间为Linux下执行时间快6倍。
二、问题排查
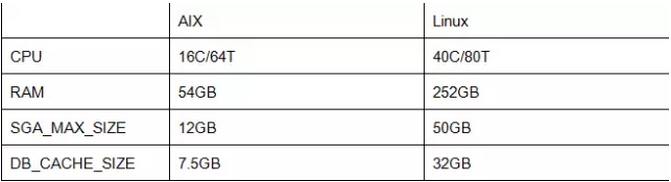
环境有何差异
现场的环境配置如下表:
QQ截图20171214141414.png
看得出,Linux配置确实比AIX来的高。
其他表试试?
既然每次执行TAB1,Linux都会比AIX慢6~7倍,那不如我们换张表试试,这边我随机测试了5张表,结果Linux都会比AIX快20%。那么问题肯定和这张表有关。
是不是Linux环境上该表上碎片太多了?不对,我们先看执行计划和等待事件。
执行计划
检查2个环境的执行计划是否一致,都是走Index Fast Full Scan

QQ截图20171214141521.png
等待事件应该为“db file scattered read”
AWR对比分析
抓取当时的AWR报告进行对比分析:
AIX环境:

QQ截图20171214141559.png
多块读仅仅等待了694次,每次11毫秒。
Linux环境:
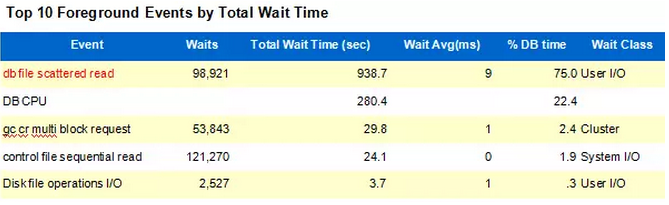
QQ截图20171214141628.png
多块读等待了98921次,单次等待9毫秒。
现场真实执行一次
在AIX和Linux环境,同时对TAB1表执行COUNT(*)查询,观察ASH视图。
Linux环境:
首先查询到此次执行的SQL_EXEC_ID。11g引入该字段真的是太好用了,标记出每个连接在执行相同的SQL语句时候的执行序号

QQ截图20171214141744.png
ASH默认抓取间隔是1秒,该次执行花费了至少943秒

QQ截图20171214141809.png
考虑到db file scattered read 等待事件可能受到参数db_file_multiblock_read_count的影响,当数据存储不够连续时候,可能增加多块读等待次数。
该等待事件P3代表BLOCKS,其含义可以从P3TEXT列看出,为此次等待请求读取的数据块数目。

QQ截图20171214141902.png
该次执行中,P3的平均值为31.96,接近主机参数db_file_multiblock_read_count=32,可以判断出数据存储,基本是连续的。
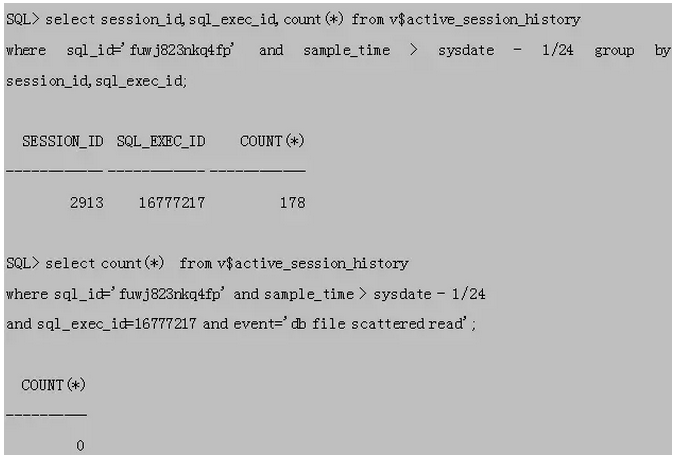
AIX环境:
查询到此次执行的SQL_EXEC_ID,继续查看该次执行等待多块读的次数
QQ截图20171214141931.png
在AIX环境下没有进行一次多块读,让我们看看等待事件是什么?

QQ截图20171214141959.png
不对,AIX和Linux环境好像都开启了EVENT 10949,不应该出现直接路径读。

QQ截图20171214142036.png
三、寻找规律
多块读的执行方式
在Oracle 11.2版本,对表或者索引的大小存在2个界限。

QQ截图20171214142549.png
进行全表扫描(Table Full Scan)或者索引快速全扫描(Index Fast Full Scan)时候,会将对象的大小,和STT和VLOT进行对比。所以当表或者索引的大小超过某个阈值,即使设置了EVENT 10949,仍然会出现直接路径读。
为了验证Oracle数据库如何选择多块读的执行方式,我们开启的NSMTIO跟踪,从Trace文件中可以看到VLOT的计算值。

QQ截图20171214142626.png
生成的Trace文件示例如下,包含了Object Size和VLOT,其单位都是BLOCK。

QQ截图20171214142658.png
验证_small_table_threshold参数
这次需要查询Oracle数据库的隐藏参数,可以建立视图方便查询:

QQ截图20171214142735.png
从H$PARAMETER视图的DESCRIPTION列,我们可以得知参数信息:

QQ截图20171214142804.png
在测试环境,调整SGA大小,计算STT值:

QQ截图20171214142833.png
计算公式如下:

QQ截图20171214142904.png
这里隐藏参数“_db_block_buffers”,是在数据库实例启动时候自动生成的。早期版本ORACLE数据库通过“db_block_buffers”参数用来调整BufferCache大小的参数,单位是BLOCK,在ORACLE 9时代变成隐藏参数,ORACLE数据库内部的一些参数计算仍然可能使用到。
验证_very_large_object_threshold参数
查询H$PARAMETER视图,参数描述如下,默认值为500。

QQ截图20171214143002.png
百度一番,存在下面2种说法:
1.VLOT就是5倍的Buffer Cache大小,那么这参数存在什么意义。
2.单位为MB,在当今单表容量随便过TB的时代,500MB的上限,基本是错误的。
在测试环境,通过调整SGA的大小,开启跟踪测试VLOT计算值:

QQ截图20171214143027.png
通过计算得知,其单位应该为百分比,计算公式如下:

QQ截图20171214143110.png
相关参数_serial_direct_read
查询H$PARAMETER视图,该参数决定是否使用直接路径读,相当于总开关

QQ截图20171214143209.png
参数_direct_read_decision_statistics_driven
查询H$PARAMETER视图,参数描述如下:

QQ截图20171214143245.png
ORACLE采用表上统计信息来决定是否使用DPR,而不是DBA_SEGMENTS里面真实记录数。该参数在ORACLE 11.2.0.2以后版本默认为TRUE。
所以直接修改表的统计信息,可以直接影响的DPR的选择。
测试执行DPR规则
测试环境:ORACLE 11.2.0.4 + Linux
开启跟踪

QQ截图20171214143358.png
建立测试表

QQ截图20171214143511.png
隐藏参数查询视图

QQ截图20171214143535.png
系统参数

QQ截图20171214143604.png
计算各个阈值

QQ截图20171214143629.png
收集统计信息

QQ截图20171214143659.png
修改统计信息

QQ截图20171214143722.png
测试结果汇总:

QQ截图20171214143751.png
可以看到在11.2版本下,小于SST不走DirectRead,大于VLOT一定走DirectRead,介于SST和VLOT的表,需要考虑是否为本地表或者压缩表MTT在11.2版本已经淘汰。
DPR 算法总结
Oracle 11.2版本,全表扫描或者索引快速全扫描,是否走直接路径读,与STT和VLOT值有关

QQ截图20171214143830.png
总结出执行规律:

QQ截图20171214143851.png
参数验证
回到案例中,为什么在AIX环境下选择了直接路径读,而Linux环境选择进入Buffer Cache缓存;
该SQL语句采用对索引PK_TAB1进行Index Fast Full Scan,这边我列举出2套环境各个参数的真实值,并且开启跟踪验证了VLOT计算值;

QQ截图20171214143920.png
IX环境:索引大小94716MB > VLOT大小39920MB
Linux环境:索引大小94632MB < VLOT大小160040MB
这下终于搞清楚真相了,因为Linux环境的Buffer Cache内存配置较大,小于VLOT大小,所以不执行Direct Path Read;而在AIX环境下,Buffer Cache内存配置较小,超过了VLOT大小,所以执行Direct Path Read。
四、问题延伸
分区表如何计算
前面我们已经知道普通表或者索引的VLOT算法和DRP选择机制,那么如果是分区表,ORACLE怎么进行选择呢?
测试环境:ORACLE 11.2.0.4 + Linux
相关系统参数

QQ截图20171214144015.png
计算各个阈值

QQ截图20171214144044.png
收集统计信息

QQ截图20171214144114.png
通过不断的修改表的统计信息,进行测试验证

QQ截图20171214144146.png
测试结果汇总:

QQ截图20171214144212.png
可以看出DPR的评估,不会考虑分区的格式,只是取整个分区表的统计信息
如果将每个分区的BLOCKS修改到最大值,表级别的BLOCK修改为较小值,会出现什么情况?

QQ截图20171214144240.png

QQ截图20171214144254.png
重复刚才的测试,发现其执行规则没有发生改变。分区级别的统计信息不会影响DPR的判断。
索引快速全扫描如何计算
测试环境:ORACLE 11.2.0.4 + Linux;
建立测试表,4个HASH分区,建立普通索引;
修改索引的统计信息

QQ截图20171214144524.png
再次查询索引统计信息

QQ截图20171214144632.png
确认执行计划走上IFFS

QQ截图20171214144700.png
测试结果汇总:

QQ截图20171214144725.png
可以看出DPR在评估IFFS时候不会考虑STT参数。超过VOLT大小,就走直接路径读,也就是说EVENT 10949 与索引快速全扫描无关
新版本改进
思考一个问题,为什么很多客户的ORACLE数据库中,EVENT 10949变成必调参数?
个人见解:理想情况下,OLTP系统中大于2% Buffer Cache的表,应该大部分会走索引扫描,偶尔一两次大表全表查询走直接路径读,这样可以让Buffer Cache中的内容保持稳定,提高Buffer Cache的命中率;
但是很多客户都遇到过,开发商没有建立合适的索引,导致SQL查询走上全表查询,同时该SQL执行较为频繁,没有Buffer Cache做缓冲,大量高并发的直接路径读很容易将一台存储压垮,导致业务系统出现严重的性能问题。
可是设置了10949一定有益吗?经常进行大表全表扫描,可能拉低的Buffer Cache的命中率,也会影响其他SQL语句的执行效率;并且全扫描的问题一直被忽视,不容易被发现。
除了对问题SQL进行优化,还有没有其他方法解决?在ORACLE 12.1.0.2 引入了Automatic Big Table Caching (ABTC)为功能,数据库将Buffer Cache中的一部分划分为大表缓存,并且统计哪些大表或者索引的热度,将其存放到ABTC中,避免了频繁的Direct Path Read。
ABTC测试
在RAC环境中启用ABTC前提条件是参数parallel_degree_policy设置为 AUTO或ADAPTIVE。
在单机环境,不依赖parallel_degree_policy参数;
配置ABTC参数,同时需要确认force_full_db_caching是关闭的

QQ截图20171214144957.png
配置参数db_big_table_cache_percent_target,为ABTC占Buffer Cache的比例,最大值为90

QQ截图20171214145025.png
该特性存在2张相关视图:
视图v$bt_scan_cache统计ABTC的使用情况,里面MEMORY_BUF_ALLOC列显示消耗CACHE的大小

QQ截图20171214145050.png
视图v$bt_scan_obj_temps存放ABTC中对象信息,可以查询到ABTC中缓存表信息,TEMPERATURE列,描述对象的热度。每执行一次全表扫描,TEMPERATURE列值加1000。
POLICY列,显示对象在ABTC中的状态:MEM_ONLY、MEM_PART、DISK、INVALID

QQ截图20171214145123.png
在大内存环境中,配置了ABTC后,当表大小超过STT时,不会执行直接路径读,而是进入ABTC中进行缓存,这样就可以节省很多物理IO。
总结:
小型机迁移至X86平台是行业大趋势。迁移过程评估平台优缺点、性能差异、迁移方案、维护成本等因素;不仅需要全面的知识,更需要参考业内成功案例。















 737
737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









