1. Softmax Loss
图1.标准CNN可以被视为由softmax损失监督的卷积特征学习机
softmax函数由于其简单性和概率解释而被许多CNN广泛采用。加上交叉熵损失,它们可以说是CNN架构中最常用的组件之一。我们将softmax loss定义为交叉熵损失。图1,描述了基于softmax loss对问题进行分类的过程。输入训练样本,倒数第二层的特征提取层输出特征
![]()
,与最后一层的分类层的类权重矩阵相乘,得到各类别的分数,也就是
Fully Connected Layer。再与
softmax function组合,得到类别概率,最后得到
cross-entropy loss。
2. L-softmax
尽管Softmax Loss很受欢迎,但目前的softmax损失并没有明确地鼓励类内紧凑性和类间可分性。作者的主要直觉是,样本和参数之间的可分性可以分解为具有余弦相似性的幅值和角值:
![]()
,其中
![]()
是类索引,最后一个全连接层的相应参数
![]()
可以被视为类
![]()
的线性分类器。在softmax loss下,标签预测决策规则很大程度上取决于每个类的角度相似性,因为
softmax loss 使用余弦距离作为分类得分。因此,作者在角度相似性方面,将softmax损失推广到更一般的
large-margin softmax(L-Softmax) 损失,使得学习特征之间可能具有更大的角度可分离性。这是通过将预设常数
![]()
乘以
sample 与
ground truth class之间的角度
![]()
来完成。
![]()
确定了接近
ground truth类别的强度,产生
angular margin(角度间隔)。
L-softmax明确地鼓励了学习特征之间的类内紧凑性和类间可分离性。此外,L-Softmax不仅可以调整所需的margin(间隔),还可以避免过度拟合。
图2. MNIST数据集中的CNN精益特征可视化(Softmax Loss(m = 1) 与 L-Softmax损失 (m = 2,3,4)) 具体而言,将特征(L-Softmax损失的输入)维度设置为2,然后按类绘制它们。我们省略了完全连接层中的常数项,因为它只会使我们的分析复杂化并且几乎不会影响性能。注意,测试精度不如表中的原因。
从图中可以看出,传统的softmax损失成为L-Softmax损失的一个特例。其中L-Softmax的学习特征变得更加紧凑并且分离得很好。L-Softmax损失是灵活的学习目标,具有可调节的类间角度边界约束。它提出了一个可调节困难的学习任务,随着要求的边缘变大,困难逐渐增加。它通过定义一个更困难的学习目标,为过度拟合问题提供了一个不同的视角,在一定程度上避免了过度拟合。L-Softmax不仅有利于分类问题,而且还有利于验证问题,在理想的情况下,所学习的特性的类间最小距离应该大于类内最大距离。在这种情况下,学习分离良好的功能可以显着提高性能。L-Softmax损失不仅继承了softmax损失的所有优点,而且学习了不同类之间具有 large angular margin(大角度间隔)的特性。
3. softmax损失的改进
original Softmax Loss公式:
以下使用标签
![]()
定义第
![]()
个输入功能
![]()
。其中
![]()
表示类别得分
![]()
的向量的第
![]()
个元素(
![]()
,K是类的数量),N是训练数据的数量。
![]()
通常是完全连接层
![]()
的激活,因此
![]()
可以写为
![]()
,其中
![]()
是W的
![]()
列。这里省略了
![]()
中的常数b以简化分析,但L-Softmax损失仍然可以很容易地修改为与b一起使用。 (事实上,性能几乎没有差别,所以我们不要在这里复杂化)因为
![]()
是
![]()
和
![]()
之间的内积,所以它也可以表示为
![]()
,其中
![]()
是矢量
![]()
和
![]()
之间的角度。那么Loss就变成
内积形式的softmax loss
举一个简单的例子,考虑二进制分类,我们有一个来自1类的样本
![]()
。
original Softmax强制使得
![]()
,即
![]()
,以便正确分类
![]()
。为了使分类更加严格,L-softmax提出了一种新的
decision margin(判定间隔),要求
![]()
,其中m是一个大于1的正整数。余弦函数在
![]()
区间上单调递减,那么以下不等式成立:
有了式子(3),
![]()
效果更显著。
新的分类准则对正确分类
提出了更强的要求,为第1类生成了更严格的decision boundary(决策边界
)。
L-Softmax损失定义为:
其中
![]()
是一个与分类边界密切相关的整数。随着
![]()
越大,分类界限越大,学习目标也越来越难。
![]()
需要是单调递减函数,
![]()
要等于
![]()
。
图3
为了简化前向和后向传播,构建一个特定的
:
其中
![]()
,并且
![]()
是一个整数。
对于前向和后向传播,我们需要将
![]()
替换为
![]()
,并且将
![]()
替换为
其中
![]()
是整数,并且
![]()
。消去
![]()
后,可以对
![]()
和
![]()
进行推导。
那么公式(7)是怎么来的呢?
棣莫弗定理
利用二项式定理展开
联立上面两式
再对上面的二项式取实部,在m为奇数的情况下是纯虚数,因此只需要考虑偶数情况,得到
用余弦替换正弦,
最后将上面
![]() 式子中的
式子中的
![]() 和
和
![]() 对换过来,将
对换过来,将
![]() 替换
替换
![]() ,展开后得到式子(7)。
,展开后得到式子(7)。
4.从几何角度分析
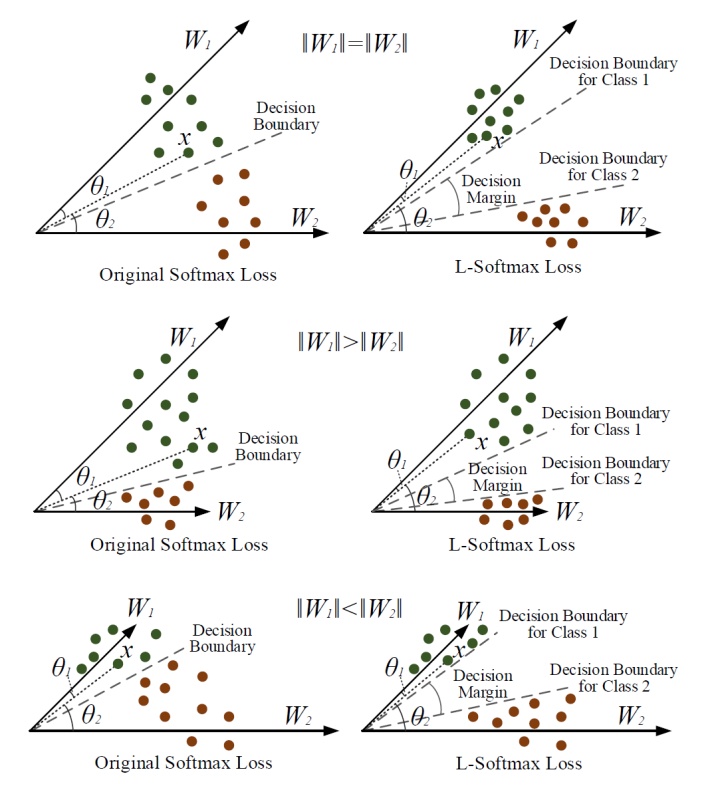
图4. 几何解释的例子
为简化几何解释,分析二元分类情况,其中只有
![]()
和
![]()
.
首先,我们考虑
![]() 场景
场景
,如图4所示。对于
![]()
,分类结果完全取决于
![]()
和
![]()
之间的角度。在训练阶段,
original softmax loss要求
![]()
将样本x分类为1类,而L-Softmax损失要求
![]()
来做出相同的判定。可以看到L-Softmax损失更严格的分类标准,增强了
class1和class2的分类界限。
从几何角度看,如果假设softmax损失和L-Softmax损失都被优化到相同的值并且所有训练特征都可以完美分类,那么class1和class2之间的angle margin(角度间隔)由
![]()
得出,其中
![]()
为
![]()
和
![]()
之间的夹角。从图中可以看到,最初的
decision boundaries是相同的,
L-Softmax损失使得
class1和class2的
decision boundaries(决策边界)不同,变为2个边界
decision boundaries for Class1和
decision boundaries for Class2。
从另一个角度来看,令
![]()
,假设
original softmax loss和
L-Softmax损失都可以优化到相同的值。然后我们可以知道
original softmax loss中的
![]()
比
L-Softmax损失中的
![]()
大
![]()
倍。结果,
learned feature和
![]()
之间的角度将变小。对于每个类别,同样的结论成立。本质上,
L-Softmax损失使每个类的可行
角度1变窄,并在这些类之间生成
decision margin(判定间隔)。
对于
![]()
和
![]()
的场景,几何解释有点复杂。由于
![]()
和
![]()
的长度不同,class1和class2的可行角度也不同(参见图4中
original softmax loss的
decision boundaries)。通常,较大的
![]()
,其对应类的可行角度越大。结果
L-Softmax损失也为不同类别生成不同的可行角度。与
![]()
情景的分析类似,
L-Softmax损失也将在
class1和class2之间生成
decision margin(判定间隔)。
5. Optimization
计算L-Softmax损失的前向和后向传播,使用典型的随机梯度下降来优化L-Softmax损失也是比较简单的。对于
![]()
,
original softmax loss和
L-Softmax损失之间的唯一区别在于
![]()
。因此,只需要在前向和后向传播中计算
![]()
,而
![]()
与
original softmax loss相同
。
结合式子(6)和式子(7),
![]() 写成:
写成:
其中
![]()
,
对于向后传播,我们使用链式法则来计算偏导数:
由于
![]()
和
![]()
,
![]()
,
![]()
对于
original softmax loss和
L-Softmax损失是相同的
,为简单起见,我们将其排除在外。
![]()
和
![]()
可以通过计算
可以通过构造
![]()
(即
![]()
)的查找表来有效地计算k。具体来说,我们举一个
![]()
时候前向和后向传播的例子。因此,
![]()
可以写成
在反向传播中,计算
![]()
和
当
![]()
时,我们仍然可以使用
式子(8),
式子(9) 和
式子(10)计算正向和反向传播。
6. 总结
L-Softmax损失在original softmax loss的基础上简单修改,在各类之间的增加一个角度边缘来分类。通过给
![]()
赋不同的值,可以为CNN定义一个具有可调节难度的灵活学习任务。
L-Softmax损失具有清晰的几何解释(图4)。
![]()
控制
class之间的
margin。随着
![]()
值的增大(在相同的训练损失下),
class之间的
ideal margin变得更大,学习难度也随之增大。当
![]()
时,
L-Softmax损失在
original softmax loss相同。
L-Softmax损失定义了一个相对困难的学习目标,可调节margin的难度。一个困难的学习目标可以有效地避免过度拟合,并充分利用来自深度和广度架构的强大学习能力
L-Softmax损失可以很容易地用作标准损失的替代品,也可与其他性能提升方法和模块配合使用,包括学习激活功能,数据增强,池化功能或其他修改的网络架构。
要好好理解decision margin(判定间隔)和 decision boundaries(决策边界)这2个概念,借助图4理解记忆。










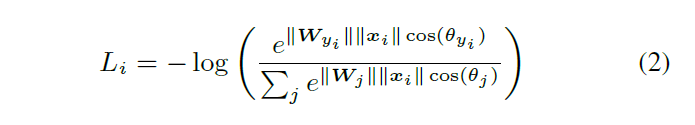
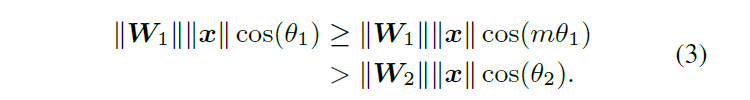

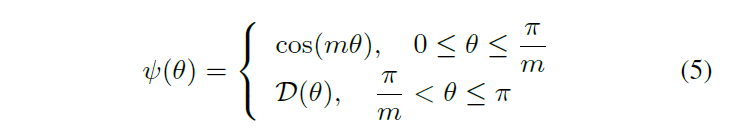


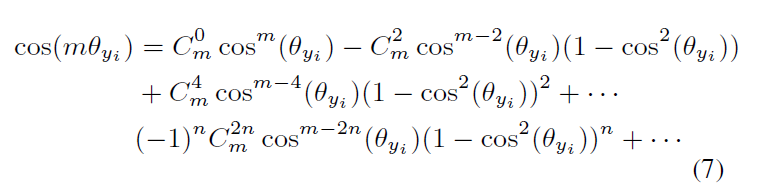




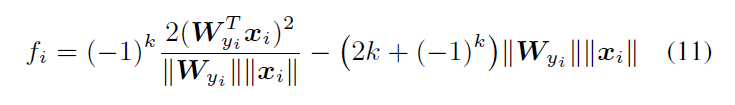

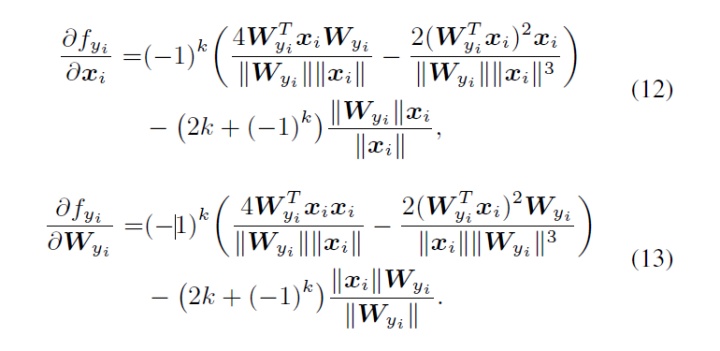















 1650
1650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









