






所谓网络爬虫,其实是模拟浏览器发送http请求,获得服务器响应数据,进而进行数据的分析和持久化。我们的浏览器主要有四个功能,发生http请求,接收http响应,解析静态文件(html,css,img等)和js动态代码,进行要素的渲染。网络信息数量庞大,仅靠人力、浏览器不能有效的利用信息,爬虫相当于一种自动化获取信息的方法。显然,搜索引擎也是一种爬虫,它可以在复杂的网络链接中根据算法获取适合的url。
一般而言爬虫获得的信息仅限后端接口提供给前端的信息,而非数据库的私密信息,后者其实是黑客。爬虫一般具有收发http响应两种功能,当遇到js动态生成的页面(当下前端在vue,react等框架下核心信息主要是异步加载),爬虫还需要具有js解析的功能。而对图像等资源,爬虫一般忽略。
以爬取豆瓣top250电影为例,scrapy根目录组成:
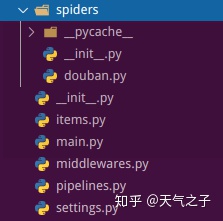
其中,spider目录下为爬虫文件;
items.py定义要获取的字段
middlewares.py是爬虫的中间层,可更改客户端和服务器的交互,例如更换代理IP,更换Cookies,更换User-Agent,自动重试
pipeline.py是爬虫持久层,指定将爬虫获取的数据存储的方法
settings.py指定一些配置,例如BOT_NAME,USER_AGENT ,ITEM_PIPELINES,数据库配置等
代码
items.py 定义字段
import scrapy
class Scrapytest01Item(scrapy.Item):
# 电影名
title = scrapy.Field()
# 作者
author = scrapy.Field()
# 简介
abstract = scrapy.Field()
spider/douban.py
import scrapy
from Scrapy01.items import Scrapy01Item
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['douban.com/']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
# 存放电影的集合
movie_items = []
for each in response.xpath("//div[@class='info']"):
item = Scrapy01Item()
title = each.xpath("div[@class='hd']/a/span/text()").extract()[0].strip()
author = each.xpath("div[@class='bd']/p/text()").extract()[0].strip()
abstract = each.xpath("div[@class='bd']/p/span/text()").extract()[0].strip()
item['title'] = title
item['author'] = author
item['abstract'] = abstract
movie_items.append(item)
return movie_items执行步骤,继承于scrapy.Spider,将从 start_urls(列表)一次获取url,执行Request方法收发请求,response返回到parse方法进行处理,利用response.xpath获取html相应位置信息,并用item进行维护。
注意到,请求的发送和接收是框架维护的,不用我们写,我们只需要注意力于分析即可。
pipelines.py
import json
class Scrapytest01Pipeline(object):
def __init__(self):
self.file = open('movie.json', 'w')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "n"
self.file.write(content)
return item
def close_spider(self, spider):
self.file.close()如上,在process_item中处理item对象,将数据保存到.json文件中。
在setting.py中需要配置pipelines,如
ITEM_PIPELINES = {
'Scrapy01.pipelines.Scrapytest01Pipeline': 300,
}数字表示优先级,值越小,优先级越高。
spider目录文件是爬虫核心文件,
import scrapy
from Scrapy02.items import Scrapy02Item
from lxml import etree
import re
from fontTools.ttLib import TTFont
from io import BytesIO
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
# class QidianFontSpider(scrapy.Spider):
class QidianFontSpider(CrawlSpider):
name = 'douban'
allowed_domains = ['douban.com']
# start_urls = ['https://book.qidian.com/info/1010191960']
start_urls = []
for i in range(0, 4):
start_urls.append('https://movie.douban.com/top250?start=' + str(25*i))
rules = (
Rule(LinkExtractor(allow=r'subject/d+'), callback='parse_item'),
)
def parse_item(self, response):
item = Scrapy02Item()
item['rank'] = response.xpath('//div[@id="content"]/div[@class="top250"]/span/text()').extract()[0]
item['title'] = response.xpath('//div[@id="content"]/h1/span/text()').extract()[0]
item['date'] = response.xpath('//div[@id="content"]/h1/span/text()').extract()[1].replace('(','').replace(')','')
item['director'] = response.xpath('//div[@id="info"]/span/span[@class="attrs"]/a/text()').extract()[0]
item['score'] = response.xpath('//div[@id="interest_sectl"]/div/div/strong[@class="ll rating_num"]/text()').extract()[0]
text = response.xpath('//div[@id="info"]/span/text()').extract() # 包含片长, 类型
item['category'] = ','.join(text[text.index('类型:')+1: text.index('制片国家/地区:')])
item['duration'] = text[text.index('片长:')+1]
text_2 = response.xpath('//div[@id="info"]/text()').extract()
pat = re.compile('[u4e00-u9fa5]+')
match_num = 0
for text_ in text_2:
res = pat.findall(text_)
if len(res) > 0:
if match_num == 0:
item['area'] = text_.strip()
else:
item['language'] = text_.strip()
match_num = match_num+1
if match_num >= 2:
break
yield item
其中Rule(LinkExtractor(allow=r'subject/d+'), callback='parseitem')表示重定向(即点击列表元素到另一个url,展示细节),parse_item方法表示分析response并保存到item中。















 490
490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









