






近日,计算机视觉顶会 CVPR 2020 接收论文结果公布,从 6656 篇有效投稿中录取了 1470 篇论文,录取率约为 22%。本文介绍了上海交通大学被此顶会接收的一篇论文《Learning from Web Data with Memory Module》。
机器之心发布,作者:涂逸。
在这篇论文中,研究者利用网络数据研究图像分类任务 (image classification)。他们发现网络图片 (web image) 通常包含两种噪声,即标签噪声 (label noise) 和背景噪声 (background noise)。前者是因为当使用类别名 (category name) 作为关键字来爬取网络图像时,在搜索结果中可能会出现不属于该类别的图片。后者则是因为网络图片的内容与来源非常多样,导致抓取的图片往往包含比标准的图像分类数据集更多的无关背景信息。在下图中的两张图片均用关键字「狗」抓取。左边图片的内容是狗粮而不是狗,属于标签噪声;右边的图像中,草原占据了整个图像的大部分,同时小孩子也占据了比狗更为显著的位置,属于背景噪声。

这两种噪声给利用网络数据学习图像分类器带来了很多额外的困难,而现有的方法要么非常依赖于额外的监督信息,要么无法应对背景噪声。论文中提出了一种不需要额外监督信息的方法来同时处理这两种类型的噪声,并在四个基准数据集上的实验证明了方法的有效性。本文已被 CVPR2020 接收。
论文地址:https://arxiv.org/abs/1906.12028
方法概述
论文的方法方法建立在多实例学习 (Multi-Instance Learning) 的框架下的。在训练分类器前,首先使用一种无监督的 proposal 提取方法 EdgeBox 来从每张网络图片中提取大量的 proposal,并使用 ROI(Region Of Interest) 来同时指代图片和其 proposal。按照多实例学习的理念,研究者将每个 ROI 当做一个实例 (instance),并将若干相同类别图片的所有 ROI 组成一个具有 multi-Instance 的 bag。在训练时,使用 bag-leve 表征,即 ROI-level 表征的加权和,来训练图像分类器。由于每个 bag 都有较大概率拥有干净的 ROI,可以通过对 ROI 赋予不同的权值,来使得其 bag-level 表征具有更少的标签噪声和背景噪声,从而得到一个更好的图像分类器。
为了给 ROI 赋予合适的权重,研究者设计了一种新颖的自组织记忆模块(Self-organizing Memory Module)。通过自组织记忆模块聚类得到每个图像类别中最具有区分性 (discriminativeness) 和代表性 (representativeness) 的表征,并通过每个 ROI 与这些表征的关系来调整其权重。方法整个框架如下图所示:
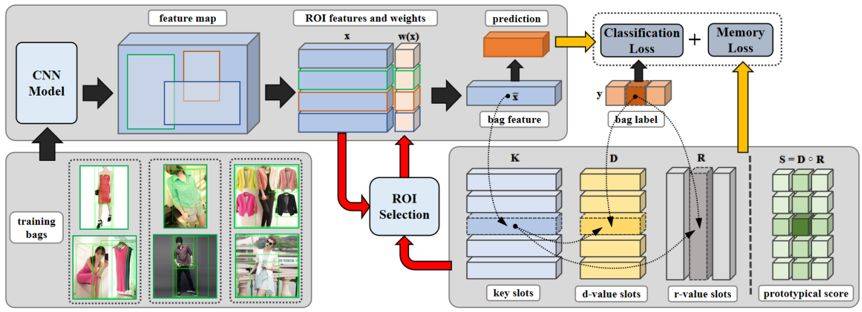
Self-Organizing Memory Module
自组织记忆模块的主要功能是为每个 bag 内的 ROI 赋予合适权重,从而让 bag-level 表征更接近于不含噪声的图片。它的原理是通过对所有 bag-level 表征进行聚类,从而找到每个类别的若干聚类中心(clustering center),再利用这些聚类中心调整其最接近的 ROI 的权重。虽然一些传统的聚类方法,比如 K-means,也可以实现类似的功能,但是我们设计的自组织记忆模块更加灵活和强大。它不仅可以集成带端到端的训练系统中,同时还能存储和更新一些有用的信息作为辅助。
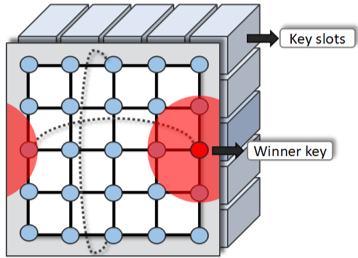
具体来说,自组织记忆模块由 key slot 和 value slot 组成。其中,key slot 用于储存聚类中心的表征,而 value slot 则储存了 key slot 对于每个类别的 discriminative score(d-score)和 representative score(r-score)。在某个类别上的 d-score 和 r-score 越高,则表明该 key slot 对这个类别具有较大的区分性和代表性。
使用自组织记忆模块时,我们首先找到一个 bag 中每个 ROI 最接近的 key slot(winner slot),再用 winner slot 对 bag 所在类别的 d-score 和 r-score 来调整其中 ROI 的权重,从而改善 bag-level 表征,使其更接近于干净的图片表征。接着,改善后的 bag-level 表征又能够重新帮助学习得到更好的 key slot 和 value slot。
受到 self-organizing map (SOM) 的启发, 研究者还在 key slot 上设计了一个邻域约束来让自组织记忆模块对初始化不敏感,并能产生比较平衡的聚类结果,因此把使用的记忆模块命名为 self-organizing memory module (自组织记忆模块)。
实验与可视化结果
这一模型在四个基准数据集上做了大量的实验,实验结果表明,模型具有显著的优越性。除了定量结果,团队也提供了深入的定性分析。

以 Clothing1M 数据集为例,对西装(Suit)这个类别可视化了其中三个 key slot。每个饼图显示对应 key slot 在 14 个类别上的 d-scores,和其在西装类别上的 r-score。同时论文也展示了与每个 key slot 余弦相似度(cosine similarity)最高的 5 个 ROI。
如饼状图所示,第一个 key slot 的 d-score 最低,因为它同时包含了很多西装和风衣(Windbreaker)的 bag,所以对西装的区分性不是很大。与此同时,其属于西装的 bag 也比其他两个 key slot 的少,不具有代表性,所以 r-score 也是最低的。也就是说,第一个 key slot 对西装这个类别即不具有区分性,也不具有代表性。相较之下,后两个 key slot 有比较高的 d-score,因为它们分别代表了不同的颜色的西装,即彩色西装和深色西装。另外,因为该数据集中彩色西装比深色西装要少,所以第三个 key slot 比第二个更能代表西装这个类别,因此其对应的 r-score 也更高。
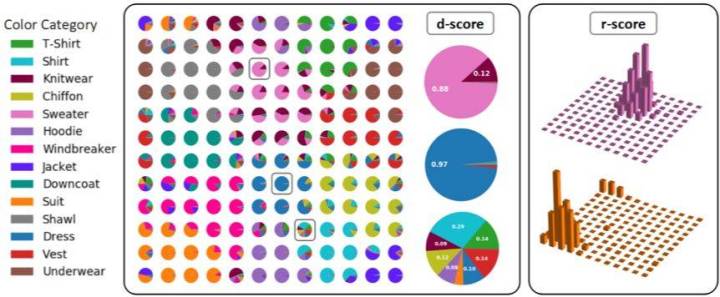
为了进一步展示自组织记忆模块的特性,研究者还在 Clothing1M 上用可视化了所有 key slot 的 d-scores。通过饼状图可以看到,同一个类别的 bag 在 key slot 的空间中是聚集在一起的。此外,他们还用柱状图分别展示了所有 key slot 在毛衣(Sweater)和西装两类上的 r-score。可以看到,这两类别的 bag 也占据了不同区域的 key slot,表明了我们方法的聚类结果具有非常合理的结构。
总结
在本文中,在多实例学习的框架下,研究者设计了一种自组织记忆模块来同时解决网络图片中的标签噪声和背景噪声问题,并在图像分类实验中取得了优异的结果。通过丰富的可视化结果表明了方法的有效性,并帮助了解了聚类结果的内部结构。














 1112
1112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









