






【基础知识】
求导
链式求导法则
导数表:https://baike.baidu.com/item/%E5%AF%BC%E6%95%B0%E8%A1%A8/10889755
激活函数
常用的非线性激活函数: sigmoid, tanh, ReLU Leaky ReLU, PReLU, ELU, Swish, Maxout
参考:
https://my.oschina.net/u/876354/blog/1624376
https://www.jiqizhixin.com/articles/2017-11-02-26
https://www.jiqizhixin.com/articles/2017-10-10-3
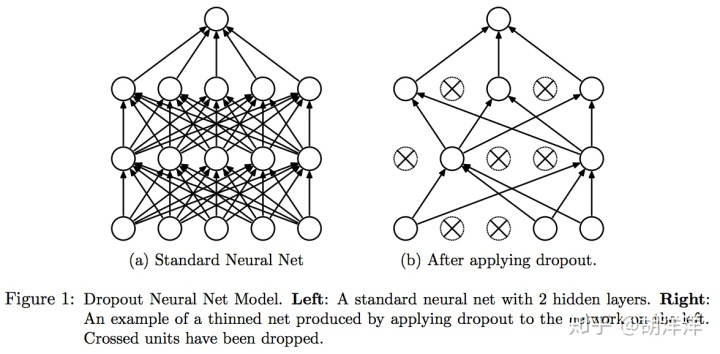
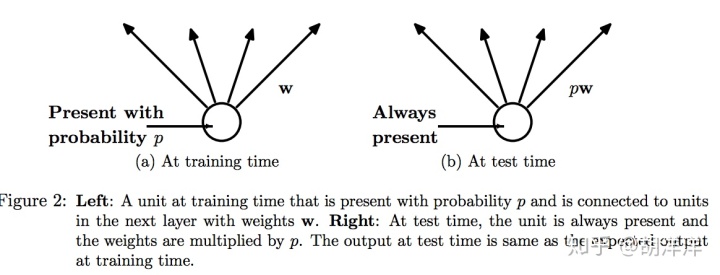
Dropout
Dropout:A Simple Way to Prevent Neural Networks from Overfitting. 2014 PDF
防止过拟合,有种bagging思想
参考:https://zhuanlan.zhihu.com/p/38200980
数据增强 Data Augmentation
防止过拟合,增强数据集,提高准确率,正则化作用。数据增强的本质是为了增强模型的泛化能力。
参考:
https://zhuanlan.zhihu.com/p/38345420
https://mp.weixin.qq.com/s/g4022Rc1RNvr3IOC_bWuaQ
优化算法
- 非自适应学习率的优化算法
SGD, SGD with Momentum, SGD with Nesterov Acceleration,给定初始学习率和学习率衰减策略
常用SGD with Momentum
- 自适应学习率的优化算法
AdaGrad, AdaDelta, RMSProp, Adam,给定初始学习率,自适应学习率衰减优化
常用Adam
参考:
https://zhuanlan.zhihu.com/p/32230623?utm_source=wechat_session&utm_medium=social&utm_oi=618937713718595584
https://zhuanlan.zhihu.com/p/55150256
https://zh.d2l.ai/chapter_optimization/index.html
https://zhuanlan.zhihu.com/p/36327151?utm_source=wechat_session&utm_medium=social&utm_oi=618937713718595584
学习率衰减策略
适用于非自适应学习率的优化算法
- exponential_decay 指数型lr衰减法
- piecewise_constant 分段常数下降法/阶梯式下降法
- polynomial_decay 多项式的方式衰减学习率
- natural_exp_decay 和exponential_decay形式差不多,只不过自然指数下降的底数1/e
- inverse_time_decay为倒数衰减
- cosine_decay 余弦衰减
- cosine_decay_restarts 是cosine_decay的cycle版本
- linear_cosine_decay 主要应用领域是增强学习领域
- noisy_linear_cosine_decay 在衰减过程中加入了噪声
- auto_learning_rate_decay
参考
https://zhuanlan.zhihu.com/p/32923584
损失函数loss

- 回归
参考:
https://zhuanlan.zhihu.com/p/38529433
https://zhuanlan.zhihu.com/p/44216830
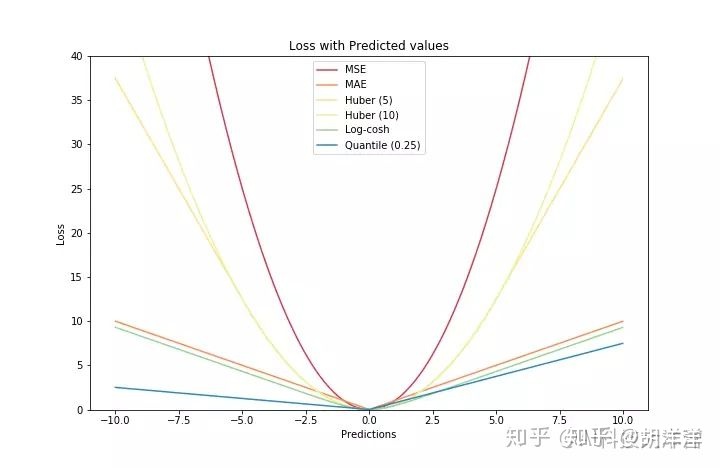
1. 均方根误差 mean squared error MSE:
优点是便于梯度下降,误差大时下降快,误差小时下降慢,有利于函数收敛。
缺点是受明显偏离正常范围的离群样本的影响较大


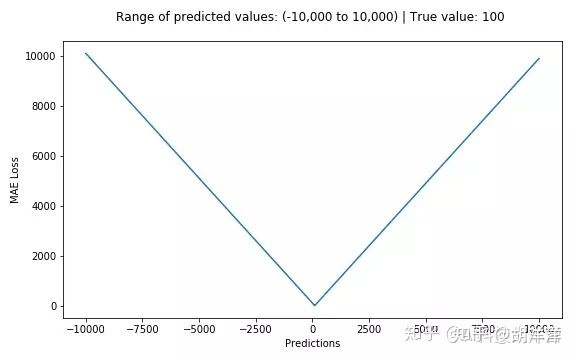
2. 平均绝对误差mean absolute error MAE:
优点是其克服了 MSE 的缺点,受偏离正常范围的离群样本影响较小。
缺点是收敛速度比 MSE 慢,因为当误差大或小时其都保持同等速度下降,而且在某一点处还不可导,计算机求导比较困难。
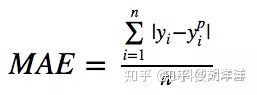
3. Huber Loss
核心思想是,检测真实值(y_true)和预测值(y_pred)之差的绝对值在超参数 δ 内时,使用 MSE 来计算 loss, 在 δ 外时使用类 MAE 计算 loss。
集成 MSE 和 MAE 的优点,但是需要手动调超参数
delta的选择非常重要,因为它决定了你认为什么数据是离群点。大于delta的残差用L1最小化(对较大的离群点较不敏感),而小于delta的残差则可以“很合适地”用L2最小化。
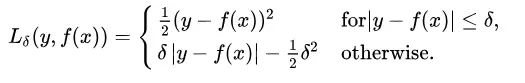
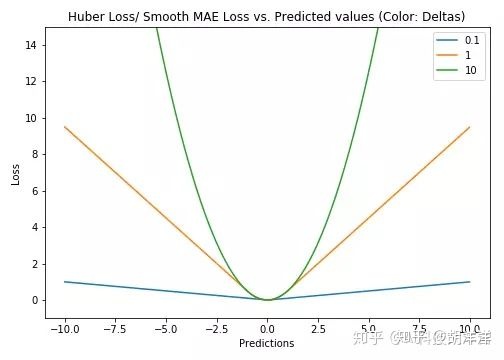
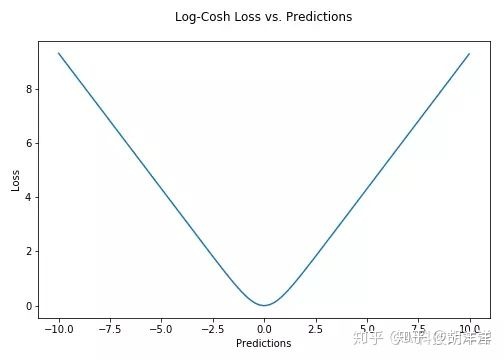
4. Log-Cosh Loss
Log-cosh是用于回归任务的另一种损失函数,它比L2更加平滑。Log-cosh是预测误差的双曲余弦的对数。
优点: log(cosh(x))对于小的x来说,其大约等于 (x ** 2) / 2,而对于大的x来说,其大约等于 abs(x) - log(2)。这意味着'logcosh'的作用大部分与均方误差一样,但不会受到偶尔出现的极端不正确预测的强烈影响。它具有Huber Loss的所有优点,和Huber Loss不同之处在于,其处处二次可导。

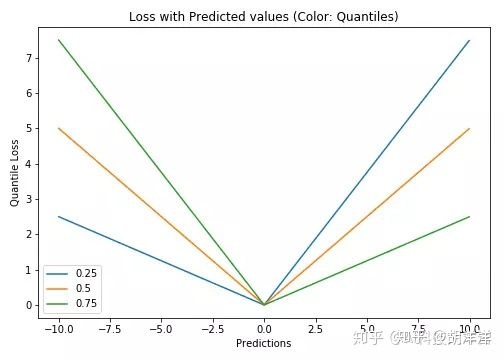
5. Quantile Loss(分位数损失)
Quantile Loss的思想是根据我们是打算给正误差还是负误差更多的值来选择分位数数值。损失函数根据所选quantile (γ)的值对高估和低估的预测值给予不同的惩罚值。举个例子,γ= 0.25的Quantile Loss函数给高估的预测值更多的惩罚,并试图使预测值略低于中位数。
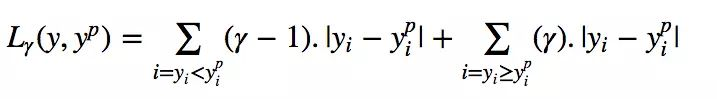
- 分类
1. log loss
参考:
https://ml-cheatsheet.readthedocs.io/en/latest/logistic_regression.html
https://blog.csdn.net/wfei101/article/details/80633825
http://www.hongliangjie.com/wp-content/uploads/2011/10/logistic.pdf
sigmoid 函数:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









