






图像分类(Image Classification)是使用计算机视觉和机器学习算法从图像中抽取意义的任务。这个操作可以为一张图像分配一个标签,或者也可以解释图像的内容并且返回一个人类可读的句子。图像分类是一个非常大的研究领域,随着深度学习的普及,它还在继续发展。目前此任务较为基础的模型主要为ResNet和DenseNet,《SFFAI69—图像分类专题》讲者杨传广设计了一个全新的图像分类模型,解决了两者的缺陷并结合了两者的优势,十分具有启发性。
关注微信公众号:人工智能前沿讲习
对话框回复"SFFAI69"
入交流群/推荐论文下载/录播视频观看/讲者PPT下载
作者介绍
杨传广,中科院计算所硕士研究生,主要研究方向为基于图像分类的模型设计与优化,以第一作者在 AAAI-2020会议上发表论文。

杨传广
论文下载地址:
https://aaai.org/Papers/AAAI/2020GB/AAAI-YangC.5011.pdf
源代码地址:
https://github.com/winycg/HCGNet
详细的中文翻译:
https://blog.csdn.net/winycg/article/details/106644890
一、引言
图像分类是计算机视觉中的基础任务,基于图像分类的深度卷积神经网络模型也在不断地被设计和优化,来达到更好的准确率和更低的复杂度。在图像分类的基础模型中,有两大经典高效的模型,分别是ResNet和DenseNet,两者在图像分类任务上具有优秀的表现同时具有较小的复杂度,但是两者都各具有缺陷。为了解决两者的缺陷并同时结合两者的优势,本文提出了一个高效的混合特征连通性模式用于图像分类,此外,本文还结合了现有的注意力机制操作构造了遗忘门和更新门来实现旧特征和新特征的有效混合。基于上述的结构,本文提出了一个全新的图像分类模型,名为HCGNet。在CIFAR和ImageNet数据集上的实验结果表明我们的模型以更低的复杂度超过了现有的人工设计的图像分类模型,同时在MS-COCO数据集上的实验结果验证了本模型具有优秀的特征迁移能力。
主要的贡献:
1.本文提出了一种混合性的特征连通模式来促进特征重用;
2.本文结合注意力机制引入遗忘门和更新门实现特征的有效混合;
3.本文提出的模型不仅在图像分类任务取得卓越的表现,而且在目标检测和分割任务上具有优秀的迁移能力。
二、方法
2.1混合连通性
重访ResNet和DenseNet
(1)参数共享:ResNet中的residual连接伴随着参数共享机制,DenseNet中的dense连接没有伴随着参数共享机制。
(2)特征学习:ResNet高效的特征重用,低参数冗余性,太多的相加特征聚合会造成特征表示的坍塌和组织信息流动;DenseNet保护了先前的所有信息,并且具有共同学习机制。
(3)整体效率:在CIFAR-10数据集,DenseNet-100利用0.8M的参数量超过了10.2M的ResNet-1001。明显的参数差距在于DenseNet-100比ResNet-1001深度更浅,由于DenseNet-100更有效的特征探索和利用模式,ResNet主要依靠增加的深度来提升特征表示能力。实验上,DenseNet每层卷积可以具有非常少的filter数量由于共同学习机制。但是一个潜在的缺点是dense connectivity对于相同特征进行重复提取造成冗余性。residual connectivity具有相对低的冗余性,由于参数共享机制。
为了结合residual connectivity和dense connectivity的优势同时避免两者的缺点,作者创建了Hybrid connectivity,采用了全局的dense connectivity和局部的residual connectivity进行嵌套的结合,即模块内部采用residual连接,模块外部采用dense connectivity,如下图所示。
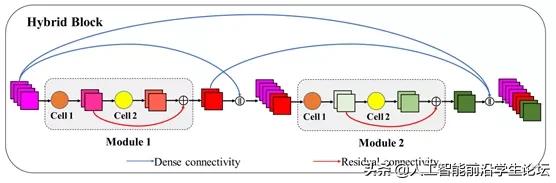
作者主要的动机
在于减少dense connectivity的冗余性。随着网络深度的线性增加,skip连接的数量和需求的参数量以〖O(n〗^2)的速率进行增长,其中n^2代表在dense connectivity下堆叠的模块数量。同时,早期冗余的特征具有低贡献但是还是平方级地传到后面的模块。所以一个简单的方法是减少冗余性的方法是直接减少模块的数量,但是这样会降低特征的表示能力。因此作者在局部的模块中嵌入残差连通性来协助特征学习,构建了新的SMG模块。通过实验表明,在dense connectivity下SMG模块比经典的bottleneck模块堆叠的数量要小很多,但是却没有牺牲性能。
2.2 SMG模块
为了配合hybrid connectivity,作者设计了SMG模块,包含了Squeeze cell (cell 1),Multi-scale excitation cell (cell 2)和Gated mechanisms(包括遗忘门和更新门),如下图所示:
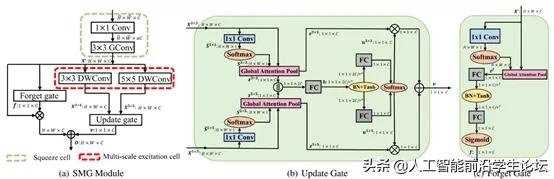
压缩单元(Squeeze cell)
这个cell坐落在SMG模块的初始位置,负责压缩进入的冗余feature map来降低后续处理的复杂度,包括一个1x1卷积和3x3组卷积对输入进行逐渐压缩。
多尺度激活单元(Multi-excitation cell)
压缩后的feature map进入来进行多尺度的激活通过多分支的卷积,不同分支的卷积具有不同kernel sizes。为了进一步提升效率,作者采用3×3和5×5深度卷积(depthwise convolution,DWConv)。这个cell的输出是2个分支产生的feature maps。
更新门
为了捕捉长期的依赖,作者利用更新门来从多尺度的信息中建模全局上下文特征,并产生权重来加权融合两个分支产生的feature map。
遗忘门
为了使用channel权重来衰减重用的特征图, 作者在残差连接上放置了一个遗忘门。
2.3全局结构

如图展示了一个HCGNet的全局结构,图中包含3个混合块(hybrid block),每个混合块之间是一个Transition层用来降采样和连通性截断,每一个绿色的方块表示SMG模块。
三、实验结果
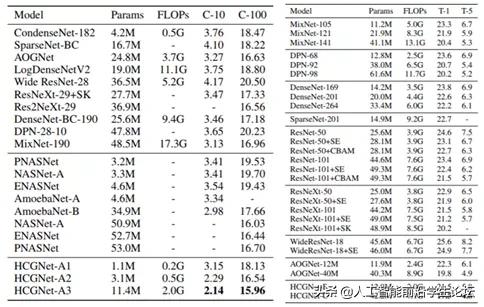
CIFAR数据集(左图)
HCGNets使用更少的复杂度超过了人工设计和自动搜索的网络结构;HCGNets超过DenseNet变体:LogDenseNet,SparseNet,CondenseNet,表明我们的冗余度优化方法是最好的;HCGNet超过自动搜索的NASNet仅仅使用了22%的参数量,证明了HCGNet结构的高效性。
ImageNet数据集(右图)
HCGNets以更低的复杂度超过广泛流行的ResNet家族及其Attention-based变体;HCGNet-B以3倍更少的参数量和计算量在性能上超过了DenseNet 0.6%;HCGNets超过了先前人工设计的SOTA网络:AOGNets
目标检测和分割
将HCGNet-B作为backbone在Mask-RCNN上进行目标检测与语义分割任务,并与流行的ResNet和先前的SOTA AOGNet进行比较:

四、参考文献
[1] He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.
[2] Huang, G.; Liu, Z.; Van Der Maaten, L.; and Weinberger, K. Q. 2017. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and
pattern recognition, 4700–4708
[3] Hu, J.; Shen, L.; and Sun, G. 2018. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 7132–7141
[4] Li, X.; Wang, W.; Hu, X.; and Yang, J. 2019. Selective kernel networks. In Proceedings of the IEEE conference on computer vision and pattern recognition.
[5] He, K.; Gkioxari, G.; Dollar, P.; and Girshick, R. 2017. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, 2961–2969















 1959
1959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









