





本文使用 Zhihu On VSCode 创作并发布
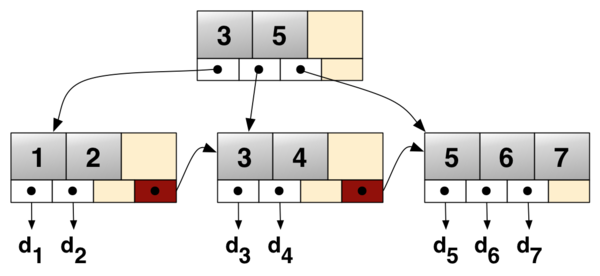
B+-树是有序的,平衡的多叉树型结构,是数据库系统中最为通用的索引数据结构。在传统的关系型磁盘数据库中,索引结构存储在磁盘上,磁盘按页(page)访问,且随机访问时有较高的寻道延时(Disk seek latency)。B+树的结点块结构适应了磁盘按块I/O的模式,从而能减少每次数据访问的I/O代价;针对纯内存数据库,B+树的结点块结构同样能适应内存和CPU高速缓存按Cacheline交互的模式,从而能相比二叉树等结构更能充分利用内存带宽,减少Cache缺失数量,易于维护。综合而言,B+树的多叉结点结构能够充分适应上世纪磁盘特性,也能一定程度适应现代硬件结构。
那么,最优的B+树结点大小,在磁盘上就是一个磁盘页吗,在内存中就是一个Cacheline吗?本文将从针对磁盘,内存中的B+树结构,分析两种场景下的结点最优大小。
磁盘B+树结点大小
其实磁盘B+树的结点大小选择上世纪就有人研究过,可参考论文[1,2], 本文这里的分析希望能做到简洁明了,并且避免无关代价增加分析难度。
分析采用了以下假设:
- 每层的结点大小相同,包括Root结点,叶子结点和中间结点。
- 每次访问结点时,读取整个结点到内存后,进行二分查找。(因为磁盘顺序读取有一定的性能优势)
- 结点读入内存后的二分查找代价基本忽略不计。(因为I/O的时间代价数量级是内存访问代价的几个数量级 [3])
分析使用到的符号:

分析过程:
(1)如果每个结点大小为B个页,那么每个结点会有
(2)当在
由(1),(2)可得从B+树根节点搜索到叶子结点,如果不考虑缓冲区命中,每次结点路径遍历的耗时为:
从函数关系可知
令上述导数为0,得到当
实际场景中,假设页大小为4096B,单个键值大小为16B,一般B+树满载程度为0.69,参考[4],此时
内存B+树结点大小
内存中虽然也可将Cacheline对等到磁盘页,但是相比磁盘有以下两点不同之处:
- 内存中Cacheline访问不存在寻道时间,顺序读和随机读无明显速度差异。
- 内存主要代价由Cacheline访问次数主导,单个Cacheline内部的搜索CPU代价可忽略不计。
- 结点搜索时不再一次读取整个结点,结点内Cacheline按需访问。
分析用到以下符号:

由于内存B+树存在两种结点扫描策略:二分查找和线性查找策略。前人工作表明,使用小结点时 (结点大小 < 256B ),线性查找策略能达到更高的性能[5]。但是出于完备性,此处我们都进行分析。
采用二分查找策略:
(1)二分查找单个结点时,二分搜索共需要访问
(2)同样,当再N个数据上建立B+树索引时,树高为
综合(1),(2)可以得出单次操作的结点遍历代价:
一般而言,
采用线性查找策略:
线性搜索一个结点时,搜索平均需要访问
经过函数单调性分析,同样发现该函数在[1,
综合以上两者,可以得出如下结论:如果忽略CPU代价,内存B+树采用单个Cacheline大小能够达到最优的时间性能,但是内存B+树的时间代价和结点大小关系不大。
在实际场景中,我们发现大部分内存B+树均采用256B或者512B作为常用结点大小,我认为主要有以下三点原因:
(1)每个结点需要额外的空间维护代价以及访问时的固定CPU代价。
(2)现代处理器存在一定Cache预取机制,它能够隐藏访问临近Cacheline的时间代价。
(3)单Cacheline结点尽管访问代价稍低,但是在插入负载容易频繁触发分裂,容易造成额外代价。
本人能力有限,如有任何问题,请您指正,谢谢!
参考文献
[1]. R. Bayer and E. M. McCreight, “Organization and maintenance of large ordered indexes,” SIGFIDET Workshop, pp. 107–141, 1970.
[2]. J. Gray and G. Graefe, “The five-minute rule ten years later, and other computer storage rules of thumb,” Special Interest Group on Management of Data Record, vol. 26, no. 4, pp. 63–68, 1997.
[3]. Latency Numbers Every Programmer Should Know, https://colin-scott.github.io/personal_website/research/interactive_latency.html
[4]. Y. Theodoridis, E. Stefanakis, T. Sellis, Efficient Cost Models for Spatial Queries Using R-trees. IEEE TKDE, 12(1), pp. 19-32, 2000
[5]. STX B+ Tree Revisiting Binary Search - panthema.net, https://panthema.net/2013/0504-STX-B+Tree-Binary-vs-Linear-Search/)














 1260
1260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









