







【国外】
1. 谷歌开源了自动化寻找最优机器学习模型的平台 Model Search
【时间】2021-2-19
【来源】Google AI 研究院
【链接】https://ai.googleblog.com/2021/02/introducing-model-search-open-source.html
【内容摘要】
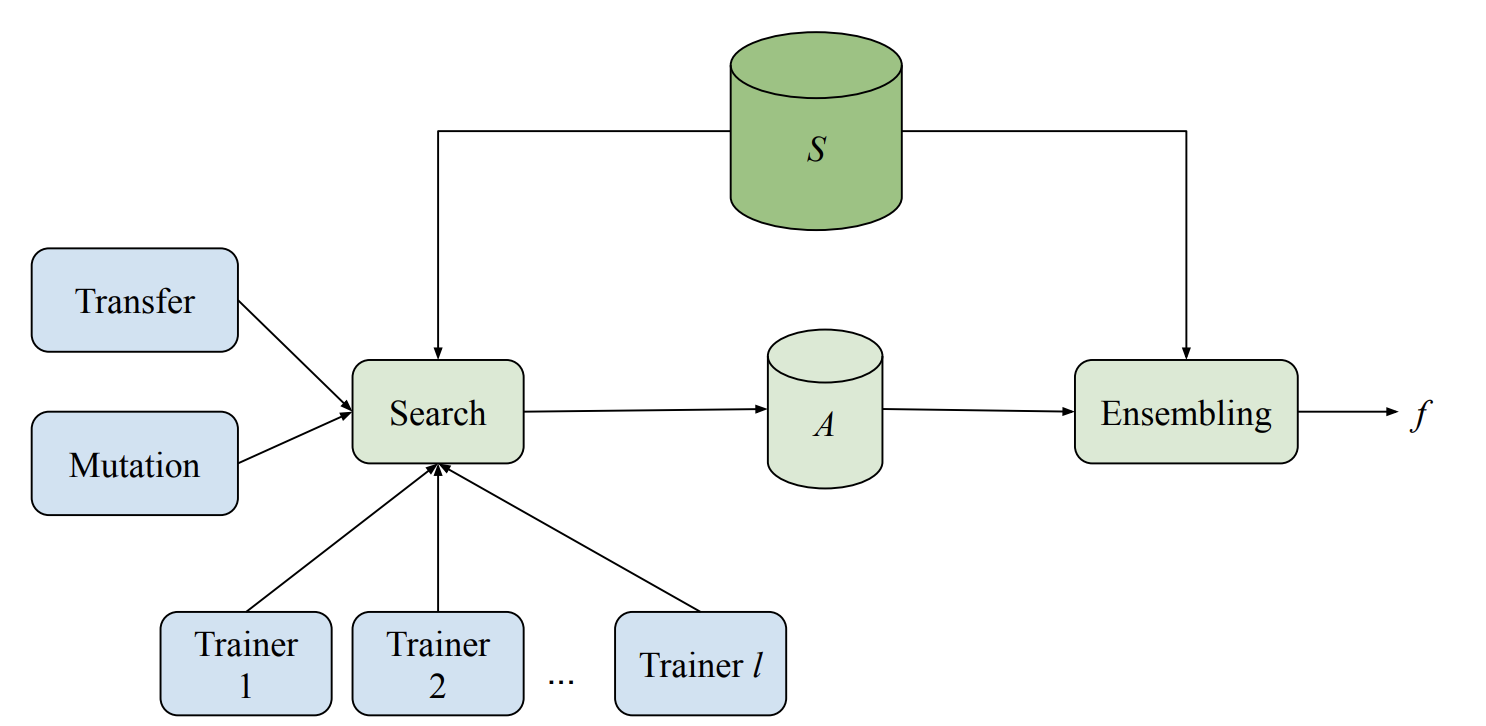
日前,Google 基于 TensorFlow 开源了一个自动寻找最优机器学习模型的平台,旨在通过 AutoML 方法帮助研究人员自动寻找合适的神经网络,而无需手动试验。例如强化学习(RL),进化算法,和组合搜索,以便在给定的搜索空间内构建神经网络。解决了这些算法计算量大以及需要数千模型训练的缺点。
Model Search 的开源版本可帮助研究人员高效,自动地开发最佳机器学习模型。模型搜索不关注特定领域,而是领域无关的,灵活的,并且能够找到最适合给定数据集和问题的适当体系结构,同时最大程度地减少编码时间,工作量和计算资源,可以在单台机器上或分布式环境中运行。
2. 图灵奖得主发布论文,介绍因果表示学习
【标题】Towards Causal Representation Learning
【时间】2021-2-22
【来源】Bernhard Schölkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, Yoshua Bengio
【链接】https://arxiv.org/abs/2102.11107
【内容摘要】
机器学习和图形因果关系这两个领域分别出现和发展。 但是,现在存在交叉,并且对这两个领域的兴趣正在增加,这两个领域都将从彼此的进步中受益。
文章回顾了因果推理的基本概念,并将它们与机器学习的关键开放问题(包括传递和泛化)相关联,从而分析了因果关系如何有助于现代机器学习研究。这也适用于相反的方向:我们注意到大多数因果关系的工作都始于给出因果变量的前提。因此,人工智能和因果关系的中心问题是因果表示学习,即从低层观察中发现高层因果变量。 最后描述了因果关系对机器学习的一些影响,并提出了两个社区相交处的关键研究领域。
基于讨论列出了极大值得研究的问题:
1.大规模学习非线性因果关系;
2.学习因果变量;
3.了解现有深度学习方法的弊端;
4.学习因果关系正确的世界和策略模型
3.DALL-E 公开论文和代码
【时间】2021-2
【来源】OpenAI
【链接】https://github.com/openai/DALL-E, http://arxiv.org/abs/2102.12092
【内容摘要】
Dall-E 公开了部分代码和论文。文章介绍了从图像到文本的机制和模型假设,这些假设可能涉及复杂的体系结构,辅助损耗或辅助信息,例如训练过程中提供的目标部件标签或分段蒙版。 研究基于一个转换器将一种简单的方法描述为一种简单的方法,该转换器将文本和图像标记自动回归为单个数据流。有了足够的数据和规模,当以零样本进行评估时,该方法就可以与以前的领域特定模型进行竞争。研究结果表明,将综合性作为规模的函数来改善可能是完成此任务的有用推动力。
4.多模态表征学习
【标题】Transformer is All You Need: Multimodal Multitask Learning with a Unified Transformer
【时间】2021-2
【来源】Ronghang Hu, Amanpreet Singh
【链接】https://arxiv.org/abs/2102.10772
【内容摘要】
文章提出使用统一 Transformer 模型 UniT,以同时学习跨领域最重要的任务,从目标检测到语言理解和多模式推理。基于Transformer编码器-解码器体系结构,UniT模型使用编码器对每个输入形式进行编码,并使用共享的解码器对编码后的输入表示形式的每个任务进行预测,然后对特定任务的输出头进行预测。整个模型经过端到端的联合培训,每项任务都会造成损失。与以前使用Transformer进行多任务学习的方法相比,UniT对所有任务共享相同的模型参数,而不是分别微调特定于任务的模型,并处理不同领域中更多种类的任务。
5.OpenAI、Uber AI Labs 提出全新算法 Go-Explore ,在 Atari 游戏超过所有玩家。
【时间】2021-2-24
【来源】Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O. Stanley & Jeff Clune
【链接】https://www.nature.com/articles/s41586-020-03157-9
【内容摘要】
通常情况下,简单直观的奖励提供稀疏的和欺骗性的反馈时,强化学习算法会遇到困难。 避免这些陷阱需要对环境进行彻底的探索,但是创建可以做到这一点的算法仍然是该领域的主要挑战之一。
文章提出了一类全新的增强学习算法,该算法在雅达利(Atari 2600)经典游戏中的得分超过了人类顶级玩家和以往的 AI 系统,在《蒙特祖马的复仇》(Montezuma’s Revenge)和《陷阱》(Pitfall!)等一系列探索类游戏中达到了目前最先进的水平。结果证明,添加目标条件策略可以进一步提高Go-Explore的探索效率,并使其能够在整个培训过程中处理随机性。 Go-Explore带来的实质性性能提升表明,记住状态,返回状态并从状态中进行探索的简单原理是一种强大而通用的探索方法-这种见识可能对创建真正的智能学习代理至关重要。
6. 研究人员合作开发了 Vx2Text 可以从视频得到文字
【标题】VX2TEXT: End-to-End Learning of Video-Based Text Generation From Multimodal Inputs
【时间】2021-1-28
【来源】Xudong Lin, Gedas Bertasius, Jue Wang, Shih-Fu Chang, Devi Parikh, Lorenzo Torresani
【链接】https://arxiv.org/abs/2101.12059
【内容摘要】
文章介绍了 VX2TEXT,这是一个用于从多模式输入生成文本的框架,该输入由视频加上文本,语音或音频组成。 为了利用已经证明在建模语言方面有效的转换器网络,每个模态首先由可学习的标记器转换为一组语言嵌入。 这使该的方法可以在语言空间中执行多模态融合,从而消除了对临时跨模态融合模块的需求。 为了解决连续输入(例如视频或音频)上令牌化的不可区分性,利用松弛方案可进行端到端训练。
此外,与以前的仅编码器模型不同,网络包括自回归解码器,可从语言编码器融合的多模式嵌入中生成开放式文本。这使此方法完全具有生成性,并使其可直接应用于不同的 视频+ x = 文本 问题,而无需为每个任务设计专门的网络负责人。
【国内】
1.北京大学、阿尔伯特大学联合 发布微标记图神经网络动态标注 文章
【标题】Dynamic Labeling for Unlabeled Graph Neural Networks
【时间】2021-2-23
【来源】Zeyu Sun, Wenjie Zhang, Lili Mou, Qihao Zhu, Yingfei Xiong, Lu Zhang
【链接】https://arxiv.org/abs/2102.11485
【内容摘要】
现有的图神经网络(GNN)很大程度上依赖于节点嵌入,该嵌入通过其身份,类型或内容将节点表示为向量。 但是,在现实世界的应用程序(例如匿名社交网络)中,广泛存在带有未标记节点的图。 先前的 GNN 要么为节点分配随机标签(这会向GNN引入伪影),要么向所有节点分配一个嵌入(无法将一个节点与另一个节点区分开)。文章对现有方法在两类分类任务中的局限性进行分析:图分类和节点分类,并提出了两种技术,即动态标记和优先动态标记,它们可以针对每种任务在统计上或渐近上满足所需的属性。 实验结果表明,我们在各种图形相关任务中均实现了高性能。
2. 中山大学发布无偏视觉问答数据集 KRVQA
【标题】Knowledge-Routed Visual Question Reasoning: Challenges for Deep Representation Embedding
【时间】2021-2-23
【来源】Qingxing Cao, Bailin Li, Xiaodan Liang, Keze Wang, Liang Lin
【链接】https://arxiv.org/abs/2012.07192
【内容摘要】
尽管通过鼓励超越图像和文本上下文的输入输出关联性来鼓励视觉问题回答(VQA)模型来发现基础知识,但现有知识VQA数据集大多以众包方式进行注释,例如,收集问题和外部原因,用户网络等等。除了对知识推理的挑战外,如何处理注释者的偏见也仍然悬而未决,这常常导致问题和答案之间的表面过度拟合。
为了解决这个问题,文章提出了一个名为“知识路由视觉问题推理”的新颖数据集,用于 VQA 模型评估。 考虑到理想的VQA模型应正确地感知图像上下文,理解问题并整合其学习的知识,我们提出的数据集旨在切断当前深度嵌入模型所利用的快捷学习,并推动基于知识的视觉研究的边界 问题推理。 具体来说,我们基于可视基因组场景图和具有受控程序的外部知识库来生成问题-答案对,以使知识与其他偏见脱节。
这些程序可以从场景图或知识库中选择一个或两个三元组,以推动多步推理,避免答案含糊不清,并平衡答案分布。 与现有的 VQA 数据集相比,我们进一步暗示了以下程序对合并知识推理的程序的两个主要限制:i)多个知识三元组可以与问题相关,但是只有一个知识与图像对象相关。 这可以使VQA模型正确地感知图像,而不必仅仅根据给定的问题猜测知识。 ii)所有问题都基于不同的知识,但是对于培训和测试集而言,答案都是相同的。
3.哈工大、天大合作 发布本地化蒸馏项目文章
【标题】Localization Distillation for Object Detection
【时间】2021-2-24
【来源】Zhaohui Zheng, Rongguang Ye, Ping Wang, Jun Wang, Dongwei Ren, Wangmeng Zuo
【链接】https://arxiv.org/abs/2102.12252
【内容摘要】
知识蒸馏(KD)见证了其在深度学习领域学习紧凑模型的强大能力,但在提取用于对象检测的本地化信息方面仍然受到限制。现有的用于对象检测的KD方法主要侧重于模仿教师模型和学生模型之间的深层特征,这不仅受特定模型体系结构的限制,而且不能提炼出本地化的歧义。在本文中,我们首先提出用于对象检测的局部蒸馏(LD)。
该 LD 可以通过采用边界框的一般本地化表示形式来表示为标准 KD。 LD非常灵活,适用于针对教师模型和学生模型的任意体系结构提炼本地化歧义。
逻辑模型非常灵活,适用于教师模型和学生模型的任意体系结构的提炼本地化歧义。此外,很有趣的是,发现Self-LD,即提炼教师模型本身,可以进一步提高技术水平。其次,我们建议使用助教(TA)策略来填补教师模型和学生模型之间的可能差距,通过这种策略,即使所选的教师模型不是最优的,也可以保证提炼效率。 在基准数据集PASCAL VOC和MSCOCO上,我们的LD可以不断提高学生探测器的性能,并显着提高最先进的探测器的性能。
4.中国人工智能学会2021年拟推选院士候选人公示
【时间】2021-02-22
【来源】中国人工智能学会
【链接】https://mp.weixin.qq.com/s/YXzOFEKClQOdA1kQZZDNxQ
【内容摘要】
根据《中国科协办公厅关于组织推选2021年中国科学院和中国工程院院士候选人的通知》(科协办发组字〔2021〕2号)和《中国人工智能学会推选院士候选人工作实施细则》文件要求,经推选专家委员会投票表决,北京大学王龙教授、清华大学施路平教授、中国科学院自动化研究所胡卫明研究员、中国人民解放军陆军刘增良教授为我会向中国科协推荐的中国科学院院士候选人。
王龙,北京大学教授,先后获得国家自然科学奖二等奖、三等奖。在国内外学术期刊发表论文100余篇。王龙长期致力于控制理论与应用研究,在参数摄动系统控制、多智能体协作与控制、复杂网络化系统控制等方面作出了一系列系统性的创新工作。
施路平,现任清华大学类脑计算研究中心主任、清华大学光盘国家工程研究中心主任。过去十五年,潜心研究类脑计算。研制了世界首款异构融合类脑芯片和系统,提出类脑计算完备性基础理论和层次系统架构,为我国在类脑计算这个新兴领域的研究跻身国际先进行列做出了突出贡献。
胡卫明,中国科学院自动化研究所研究员,国家杰出青年基金获得者、万人计划科技创新领军人才、百千万人才工程 国家级人才入选者。主要研究计算机视觉、视频信息处理与安全等方向。
刘增良,中国人民解放军陆军三级教授,智能系统工程专家,国家百千万人才工程一、二层次人员,中央直接管理的高级专家,国务院特贴获得者。建立了智能系统工程模型方法体系,提出了关系确定型、语义不定型、关系不定型等人工智能模糊系统模型和针对性关键技术方法,为解决重大装备智能工程基础性难题发挥了重大作用和影响。
5.大连理工大学和香港城市大学的研究人员 发布自动生成漫画书的系统
【标题】Automatic Comic Generation with Stylistic Multi-page Layouts and Emotion-driven Text Balloon Generation
【时间】2021-2-26
【来源】Xin Yang, Zongliang Ma, Letian Yu, Ying Cao, Baocai Yin, Xiaopeng Wei, Qiang Zhang, Rynson W.H. Lau
【链接】https://arxiv.org/abs/2101.11111
【内容摘要】
文章提出了一种无需任何人工干预即可从视频生成漫画书的全自动系统。给定输入视频及其字幕,首先通过分析字幕提取信息丰富的关键帧,然后将关键帧样式化为喜剧风格的图像。利用一种新颖的自动多页面布局框架,跨多个页面分配图像并基于图像的丰富语义(例如重要性和图像间关系)合成视觉上有趣的布局。最后,与使用先前作品中相同类型的气球相反,利用情绪感知气球生成方法,通过分析字幕和音频的情感来创建不同类型的单词气球。
该方法能够根据不同的情感改变气球形状和单词大小,从而带来更丰富的阅读体验。 一旦生成气球,便通过扬声器检测将它们放置在与其相应扬声器相邻的位置。 从结果来看,无需任何用户输入,就可以生成具有视觉上丰富的布局和提示框的高质量漫画页面。同时也受到了读者的广泛好评。















 3366
3366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









