





接着数据分析之Pandas操作(1)的介绍,本次介绍在实际应用场景中几个常用的函数。还是以titanic生存数据为例,本次需要导入pandas 、numpy 、scipy三个工具包。
import pandas as pdimport numpy as npfrom scipy.stats import zscoretrain_data = pd.read_csv("titanic/train.csv")
(1)查找及统计缺失值
使用函数:count,功能:统计非空个数#统计非空个数train_data.count()#统计空值个数train_data.shape[0]-train_data.count()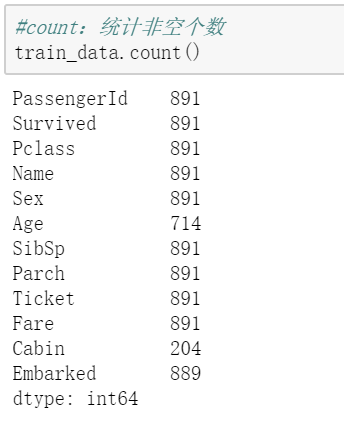 使用函数:isnull, 功能:统计空值个数
使用函数:isnull, 功能:统计空值个数
#计算全部数据中空值的总数,与train_data.shape[0]-train_data.count() 一致np.count_nonzero(train_data.isnull())
#计算某一列中空值的个数np.count_nonzero(train_data['Age'].isnull())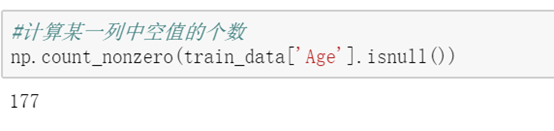
(2)通过apply统计缺失值
首先自定义函数,返回某个维度的空值个数#通过定义函数 统计缺失值def missing_counts(vector): null_vector=pd.isnull(vector) null_counts=np.sum(null_vector) return null_countscount_missing_row=train_data.apply(missing_counts,axis=1) count_missing_row.head(10)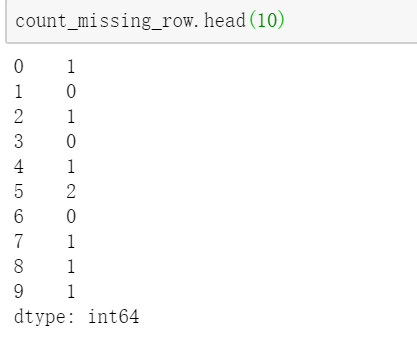 将函数作用于每一列
将函数作用于每一列
count_missing_col=train_data.apply(missing_counts)train_data.fillna(0)train_data['Age'].fillna(0)train_data.dropna().head(10)#计算不同仓位的乘客平均年龄avg_age_by_pclass=train_data.groupby('Pclass').Age.mean()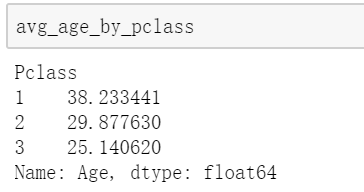
#单独计算1等仓位的平均年龄avg_age_by_pclass=train_data.loc[train_data.Pclass==1]['Age'].mean()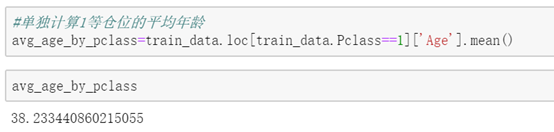 情景2:单个字段,多个数字特征,使用agg函数
情景2:单个字段,多个数字特征,使用agg函数
avg_age_by_pclass=train_data.groupby('Pclass')['Age'].agg([np.count_nonzero,np.mean,np.std])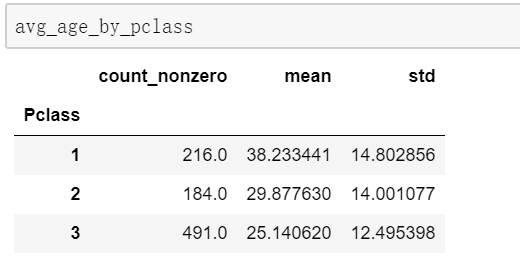 情景3:统计统计多个字段,多个数字特征
情景3:统计统计多个字段,多个数字特征
avg_age_by_pclass=train_data.groupby('Pclass').agg( {'Age':'mean','Fare':'median' })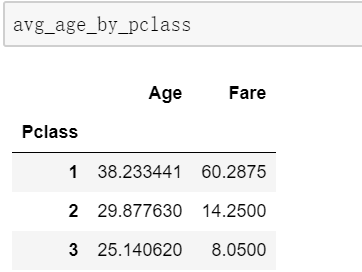 情景4:重命名数字特征列,重新设置索引
情景4:重命名数字特征列,重新设置索引
avg_age_by_pclass=train_data.groupby('Pclass')['Age'].agg([ np.count_nonzero, np.mean, np.std]).rename(columns={'count_nonzero':'count','mean':'avg','std':'std_dev'}).reset_index()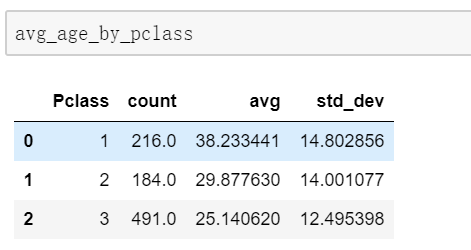 (6)过滤,类似SQL的having
(6)过滤,类似SQL的having
#按照仓位分组,筛选仓位人数大于200的数据,过滤仓位等级为2的数据train_data.groupby('Pclass').filter(lambda x:x['Pclass'].count()>=200)['Pclass'].value_counts() 
#按照仓位分组,筛选年龄均值大于29的数据,过滤仓位等级为2的数据train_data.groupby('Pclass').filter(lambda x:x['Age'].mean()>=29)['Pclass'].value_counts() (7)转换:transform
定义一个正态标准化函数
(7)转换:transform
定义一个正态标准化函数
#标准化函数def zscore_count(x): return ((x-x.mean())/x.std())#按照仓位分组后对年龄字段标准化z_transf=train_data.groupby('Pclass').Age.transform(zscore_count)z_transf.shape,train_data.shape 不分组,对全量数据标准化
不分组,对全量数据标准化
all_z_score=zscore(train_data.Age) 总结:通过两次对pandas常用操作的介绍,希望能帮助大家起到一个入门的作用,但是,pandas功能强大,还有很多细节需要在实际应用中去查阅官方文档,不要拒绝阅读英文官方文档,查字典,慢慢读。
总结:通过两次对pandas常用操作的介绍,希望能帮助大家起到一个入门的作用,但是,pandas功能强大,还有很多细节需要在实际应用中去查阅官方文档,不要拒绝阅读英文官方文档,查字典,慢慢读。















 6283
6283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









