








版权声明:小博主水平有限,希望大家多多指导。本文仅代表作者本人观点。
目录:
BG大龍:【机器学习项目实战01】异常检测——信用卡交易数据检测(上篇)zhuanlan.zhihu.com
1. 【项目背景】
2. 【数据简介】
3.【导入必备的工具包】
4.【数据读取】
5.【数据标签分布】——‘0’类+‘1’类
6.【数据标准化处理】——sklearn处理Amount和Time数据,得到数据集样本分布情况
BG大龍:【机器学习项目实战01】异常检测——信用卡交易数据检测(中篇)zhuanlan.zhihu.com
7. 【下采样方案】根据数据集样本分布情况,提出下采样方案。解决原始数据集样本不均衡,得到一个下采样数据集
8. 【数据集切分】——将‘原始数据集’和‘下采样数据集’切分成训练集+验证集+测试集
9.【交叉验证】调用逻辑回归模型,采用交叉验证方法来评估(本方案使用KFlod)——在下采样的训练集+验证集中找到最好的模型参数
10. 上述‘最好的模型’,观察在‘下采样的测试集’中的表现——混淆矩阵
11.上述‘最好的模型’,观察在‘原始数据的测试集’中的表现——混淆矩阵
BG大龍:【机器学习项目实战01】异常检测——信用卡交易数据检测(下篇)zhuanlan.zhihu.com
12.【原始数据方案】——基于下采样方案的结果,如果直接使用原始数据方案会怎么样?
13.【阈值对结果的影响】
14.【过采样方案】——基于SMOTE算法对异常样本集(正例)进行样本生成,解决原始数据集样本不均衡,得到一个下采样数据集
15.【项目总结】
我们知道在这个数据集中,正负样本的比例极不平衡,现在我们有3个思路。
下采样(数据抽取)、过采样(数据扩充)、直接用原始数据
7. 【下采样方案】——将正常样本(负例)进行样本抽取,解决原始数据集样本不均衡,得到一个下采样数据集
所谓下采样,就是从样本量大的类别中,随机选出与小样本的类别数量相同的样本。
下采样方案=从标签为0的样本(约28万)中,随机选择492个0样本,与已经有的492个标签为1的样本,重新组成数据集。
(0样本——正常样本;1样本——异常样本)
1 分步骤理解代码:
【步骤1】得到Class列的数据集
【步骤2】分别得到492个样本量的‘异常样本索引’+‘随机正常样本索引’
【步骤3】形成下采样数据集,并且分成 X特征数据集、y标签数据集

【步骤1】得到Class列的数据集
##【1】将数据集分类
X = data.iloc[:, data.columns != 'Class']
#iloc[]选取特定的列。
#“:”是指,选取整列。
#data.columns != 是指,将数据集中【列名称】不是‘Class’的选取出来送到X
y = data.iloc[:, data.columns == 'Class']
#同理,data.columns == 是指,将数据集中【列名称】是‘Class’的选取出来送到y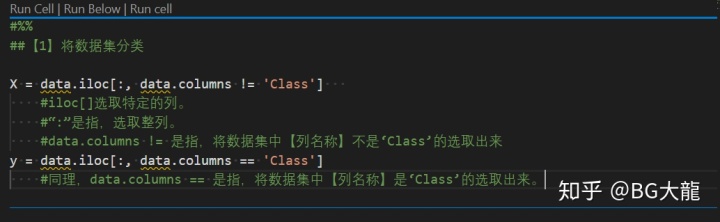
【注解】切片——在Pandas中,有loc()和iloc()用来选取特定的列。
在一个DataFrame数据中,loc根据设置的index来选取对应的列。iloc并不是根据index来索引,而是根据列号来索引,从0开始,逐次加1。 详细内容,我写在答疑博客:BG大龍:【Python答疑】Python怎么选取特定列?—Pandas的iloc、loc使用zhuanlan.zhihu.com

【步骤2】分别得到492个样本量的‘异常样本索引’+‘随机正常样本索引’
##【2】得到异常样本的索引
number_records_fraud = len(data[data.Class == 1])
#len()是计算data[]的个数,再将结果送给“异常样本个数”存放
fraud_indices = np.array(data[data.Class == 1].index)
#.index是取data[]的索引地址,np.array将输入转为矩阵格式,再送到“异常样本索引集”存放
##【3】得到正常样本的索引,由于正常样本很多,涉及到随机抽取
normal_indices = data[data.Class == 0].index
#index是取data[]的索引地址,再送到“正常样本索引集”存放
##【4】在正常样本中,随机采样出指定个数的样本(492个),并得到索引
random_normal_indices = np.random.choice(normal_indices, number_records_fraud, replace = False)
#np.random.choice()是指,在正常样本中用随机模块挑选出与异常样本量相同的个数。false指只挑选不替换
random_normal_indices = np.array(random_normal_indices)
#np.array()是指,将输入转换成矩阵形式,然后再送到“随机正常样本索引集”存放
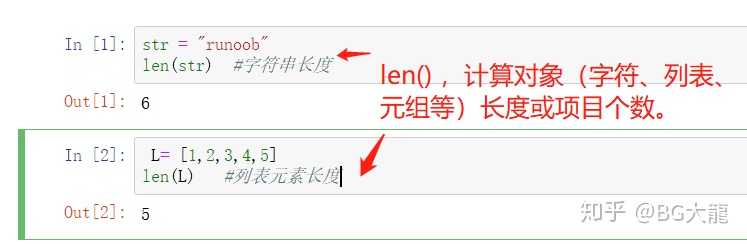
【注解】Python内置函数len()
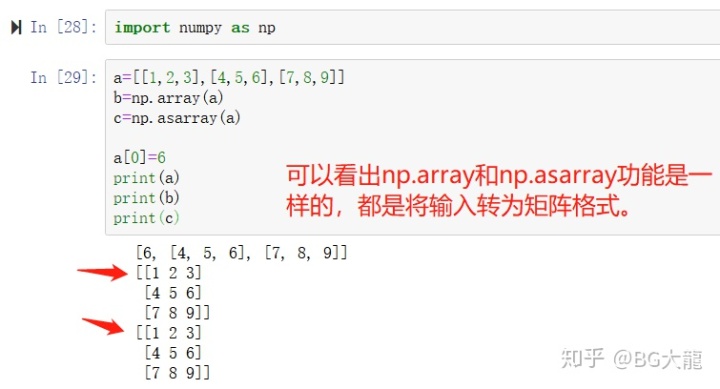
【注解】np.array()的用处
输入为列表时
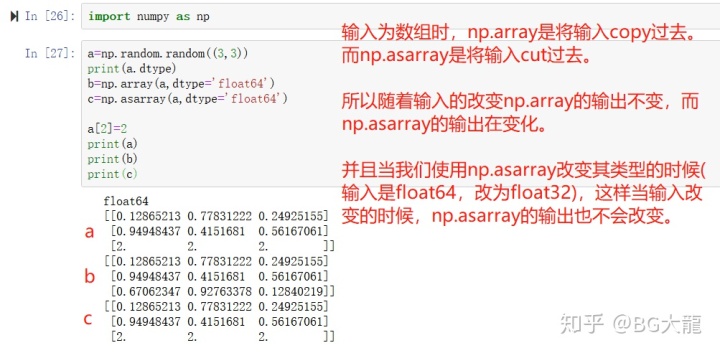
输入为数组时
【步骤3】形成下采样数据集,并且分成 X特征数据集、y标签数据集
##【5】有了正常样本和异常样本后,把它们的索引都拿到手
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices])
#np.concatenate()是数据拼接函数,将“异常样本索引集”和“随机正常样本索引集”拼在一起得到“下采样索引集”
##【6】根据索引得到下采样所有样本点
under_sample_data = data.iloc[under_sample_indices,:]
#data.iloc[]是指,对“下采样索引集”进行切片,选under_sample_indices的所有列
##【7】将下采样数据集分成X、y两类
X_undersample = under_sample_data.iloc[:, under_sample_data.columns != 'Cla 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3221
3221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









