





01ElasticSearch架构
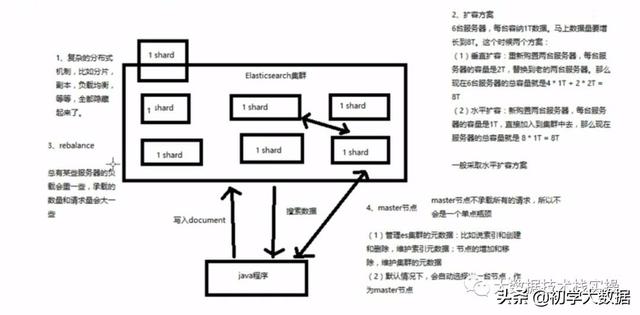
ElasticSearch是分布式的对等架构,而且具有透明隐藏的特性。
ES内部的数据如何分片、shard如何达到负载均衡、shard的副本、document的请求路由、集群扩容、shard重分配等多种特性无需用户关心
ES的扩容分为垂直扩容和水平扩容,通常方案采取水平扩容;当增减节点时,数据会自动重分配从而达到负载均衡
ES其实也是master-slave架构。
master的职责主要是管理es集群的元数据,例如索引的创建和删除,维护索引元数据
默认情况下,会自动选择出一台节点,作为master节点
master节点不会承载所有的请求,不会是一个单点瓶颈
在ES中,所有的节点都能接收所有的请求,收到客户端请求的节点会作为一个协调节点,然后将其请求路由转发到包含请求结果数据的shard所在的节点上,最后将结果通过协调节点发送给客户端。
02 shard&replica机制
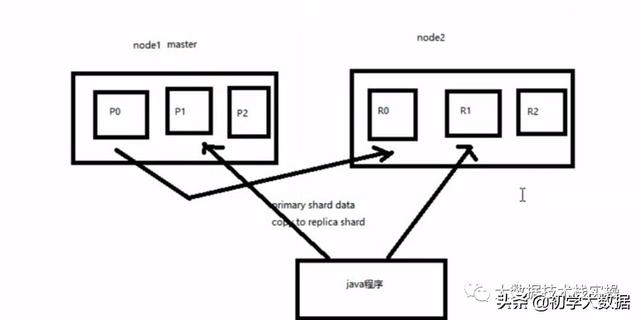
ES中,一个Index包含多个shard,每个shard都是一个最小的工作单元,承载部分数据,是一个lucense实例,具有完整建立索引和处理请求的能力
每一个shard又分为primary shard(主shard)和replica shard(副本shard),每个document肯定只存在与某一个primary shard以及对应的replica shard中,不可能存在多个primary shard;其中replica shard负责容错,以及承载读请求负载
es在创建索引的时候就指定了primary shard的数量,且不可随意改变了,但是replica shard可以随意修改.es5.x版本中primary shard的默认数量是5个。但是在es6.x之后就变成了1,replica默认也是1,而且一个index只能有一个type
primary shard不能和replica shard在同一个节点上,但是可以和其他primary shard的replica shard放在同一个节点上
单node环境下创建一个index,有3个primary shard,3个replica shard
PUT /test_index{ "settings": { "number_of_shards": 3, "number_of_replicas": 1 }}这个时候3个primary shard分配到仅有一个Node上,另外3个replica shard是无法分配的
集群可以正常工作,但是一旦出现宕机,数据将全部丢失,而且集群不可用,无法承载任何请求

2个node环境下replica shard分配流程
1.replica shard分配
2.primary --->replica 同步
3.读请求: primary/replica
03 容错机制
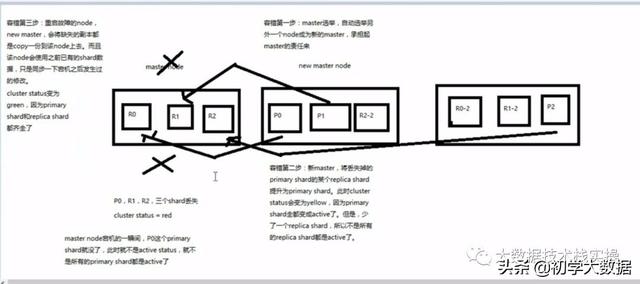
1.当es集群中的master节点down掉之后,会自动选举另外一个node成为新的master,承担起master的责任来。当然会出现master假死的情况,以及shard如何分配等情况,这些高级特性待后续章节详解
2.master选举完成之后,会将旧master节点上的primary shard的某个replica shard提升为primary shard,此时cluster的状态会变为yellow,因为这个时候虽然primary shard都是处于active状态,但是shard的副本没有达到足够的数量
3.当将故障的node节点重启之后,新的master节点会将缺失的副本都复制一份到这个node上,而且这个node会使用之前已有的shard数据,只是同步一下宕机之后发生后的更改,此时cluster的状态变为了green
04 document数据路由
一个index的数据会被分为多片,每片都在一个shard中,所以说一个document只能存在于一个shard中
当客户端创建document的时候,该document应该存储在这个Index的哪个shard上,这个过程称之为document routing,即数据路由,默认按照doc id进行路由
05 路由算法
路由公式:shard = hash(routing)%numberofprimary_shards
举例来讲,一个index有3个primary shard,每次增删改查一个document的时候,都会带来一个routing number,默认就是document的id,即routing=id,会将这个routing值传入hash函数中,产出一个routing值的Hash值;然后产出的值对这个index的primary shard的数量取余数,例如21%3=0,就决定了该document放在primary shard0上
根据路由算法可知,primary shard的数量在创建后便不可变了,这就是不可变的原因
06 document增删改实现原理
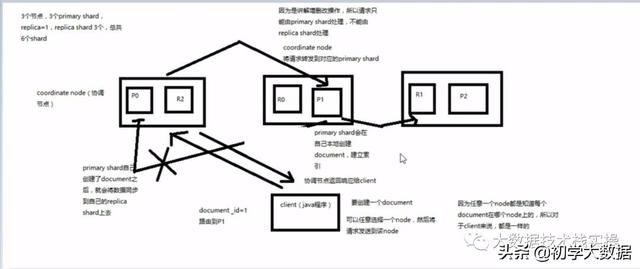
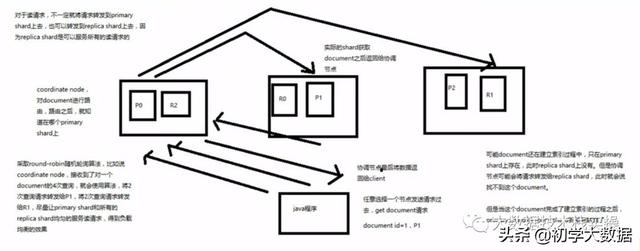
1.客户端选择一个node发送请求,这个node就是coordinating node(协调节点)
2.coordinating node,对document进行路由,将请求转发到对应的node(有primary shard)
3.实际的node上的primary shard处理请求,然后将数据同步到replica node
4.coordinating node如果发现primary node和所有的replica node都搞定之后,就返回响应结果给客户端
07 document查询内部原理
1.客户端发送一个document请求给一个Node,此时该Node为coordinate node
2.coordinate node通过路由算法,将该请求转发给primary shard所在的Node,这里并不一定会转发到primary shard的节点上,采用round-robin随机轮询算法
例如coordinate node接收到了对一个document的4次查询请求,这时会使用round-robin算法,将2次查询请求转发给primary shard,将2次查询请求转发给replica shard,,尽量让primary shard和所有的replica shard均匀的服务器读请求,得到负载均衡的效果
3.document所在的primary shard或replica shard节点将document返回给coordinate node
4.coordinate node 将收到的结果返回给客户端















 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









