







使用python也有一段时间了,最近比较关注自住房信息,虽说它更新的比较缓慢,但是平时也不怎么会特意的去它的网站上去看,于是就想用python抓它的信息,如果有新的信息就给自己发个邮件,这样手机上得到通知以后就可以再去它的网站上看看。
功能比较简单,但是用到的点还是挺多的,这里记录一下。
主要有以下几个步骤
- python beautifulsoup 与requests的使用
- ubuntu 中安装 mysql 与mysql-python
- beautifulsoup与requests编码的问题
- 使用gmail发送邮件,其中gmail采用两步认证要单独申请一个密码
- 在ubuntu中使用crontab定时来触发脚本
网站分析
自住房信息的网址为 http://www.bjjs.gov.cn/bjjs/fwgl/zzxspzf/tzgg/index.shtml
主要就是抓取上面的通知,使用数据库或者本地文件记录一下url和标题
主要就是以下这块html
- 富兴鹏城自住型商品住房递补选房公告2017-07-06
- 朝阳区锦都家园自住型商品住房项目申购登记公告2017-06-12
- 住总万科·TBD万科天地自住型商品住房递补选房公告2017-06-09 .... ... .. .
我这里使用的是beautifulsoup来进行解析。
beautifulsoup的使用参考 beautifulsoup使用
我一开始使用requests库的get方法来抓取网页,后来我被它的编码逼疯了,在网上查了下,requests与beautifulsoup都会对网页的编码进行优化,

但是它们同时优化就会出现很多头疼的问题,所以最后我使用python的urllib来抓取网页

解析出url 与title信息
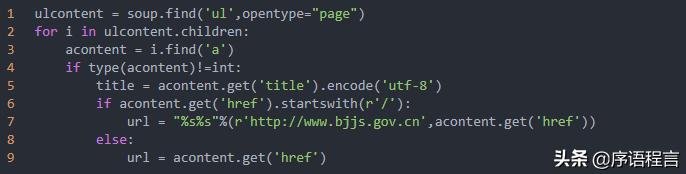
使用 soup.find('ul',opentype="page") 来定位到通知的ul dom结构,然后再寻找下面的a结构,美汤的用法还是很牛逼的。
使用mysql来记录
得到url与title信息后,就去数据库中查寻一下,我一开始想用mongo,但是由于我的VPS是OpenVZ的,所以安装mongodb以后发现有很多问题,最后索性放弃,改用mysql。
ubuntu 上安装mysql还是挺简单的
sudo apt-get install mysql-server mysql-client
安装过程中会设置root密码,安装结束后,我创建了一个库和表
mysql> CREATE DATABASE houseinfo;mysql> use houseinfo;mysql> create table house ( id int NOT NULL AUTO_INCREMENT PRIMARY KEY, url text NOT NULL, title text NOT NULL) DEFAULT CHARSET=utf8;在表中查询url字段是否存在,不存在的话就插入
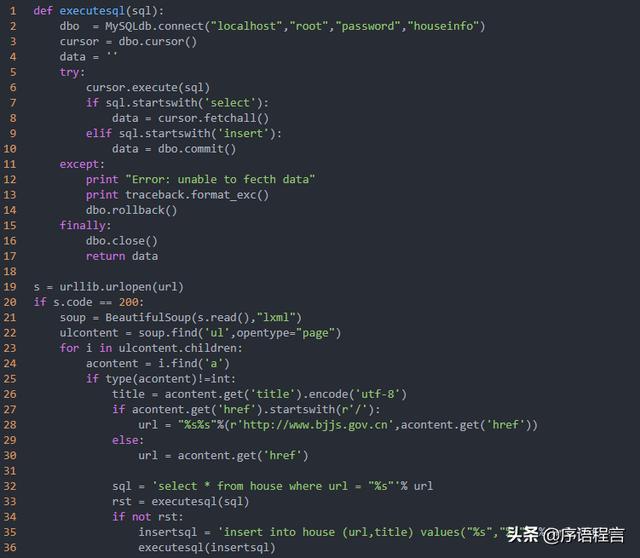
发送新通知邮件
当有一个新的通知发出来以后需要发送一封邮件
因为VPS是在国外,所在我这里使用的是gmail的smtp服务,因为我的google账户采用了两步认证,所以这里还得重新申请一个临时密码,这里不得不提一下google的服务,太人性化了!具体使用请参考 https://support.google.com/accounts/answer/185833
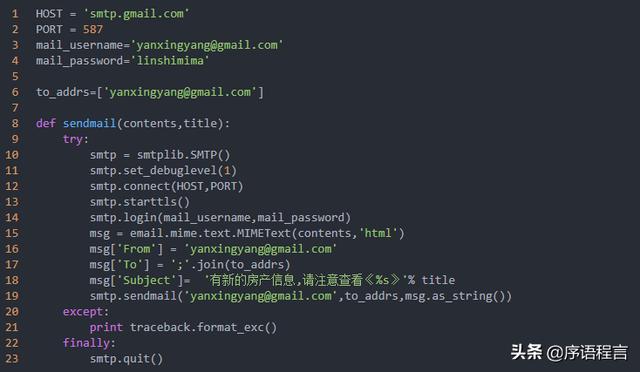
设置crontab任务
在linux的世界里crontab绝对是神一样的存在
使用参考 crontab使用
我这里设置的是每隔一个小时执行一次
1* */1 * * * python /root/gethouseinfo.py最终的效果是我收到了好多邮件。。。
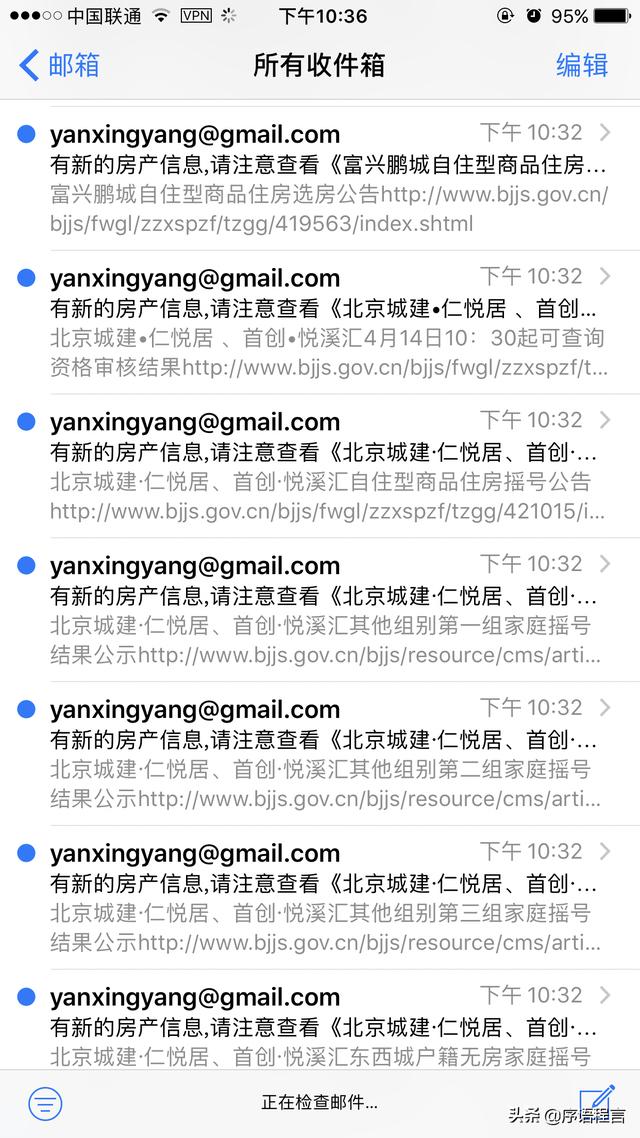
mac上也可以实时的收到
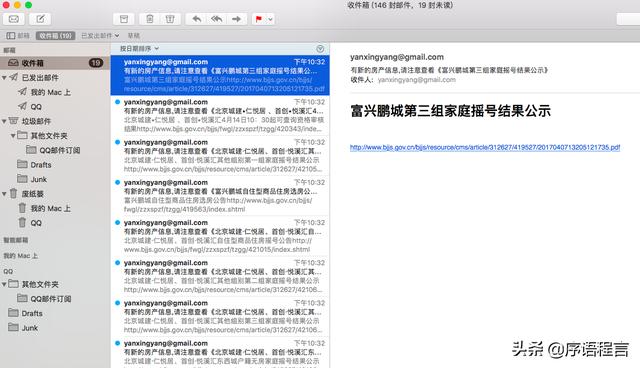
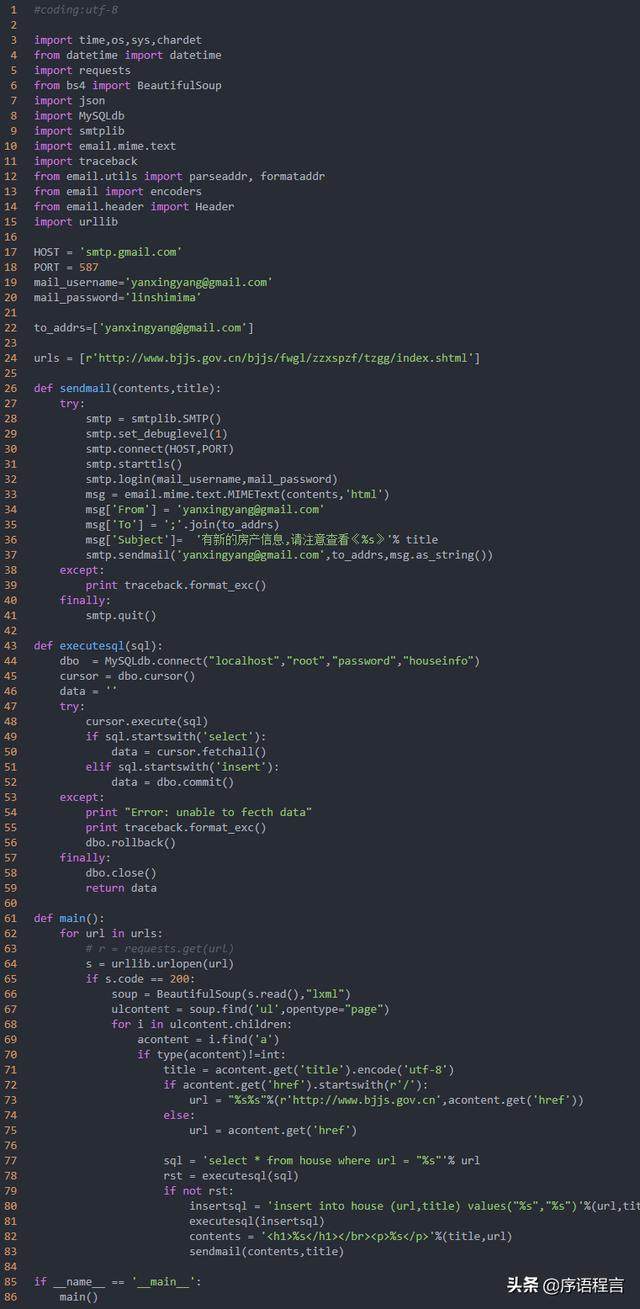
最张的全代码
遗留的问题
如果长时间的使用某个IP去抓该网站的信息它如果给封了IP就不行了,而且我也没有设置访问的header,以后可以设置一下代理或者header信息。
代码写的比较low,主要是为了尝试一种新的方式来获取信息。
由于今日头条上发的文章对于代码排版不太方便,所以我将代码片段都使用了截图的方式,想要复制代码请点击 "了解更多"来查看原文或者微信搜索公众号"序语程言"















 6650
6650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









