





本次内容我们有两个目标:
第一个初探Producer发送消息的流程
第二个我们学习一下Kafka是如何构造异常体系的
一、代码分析
Producer核心流程初探
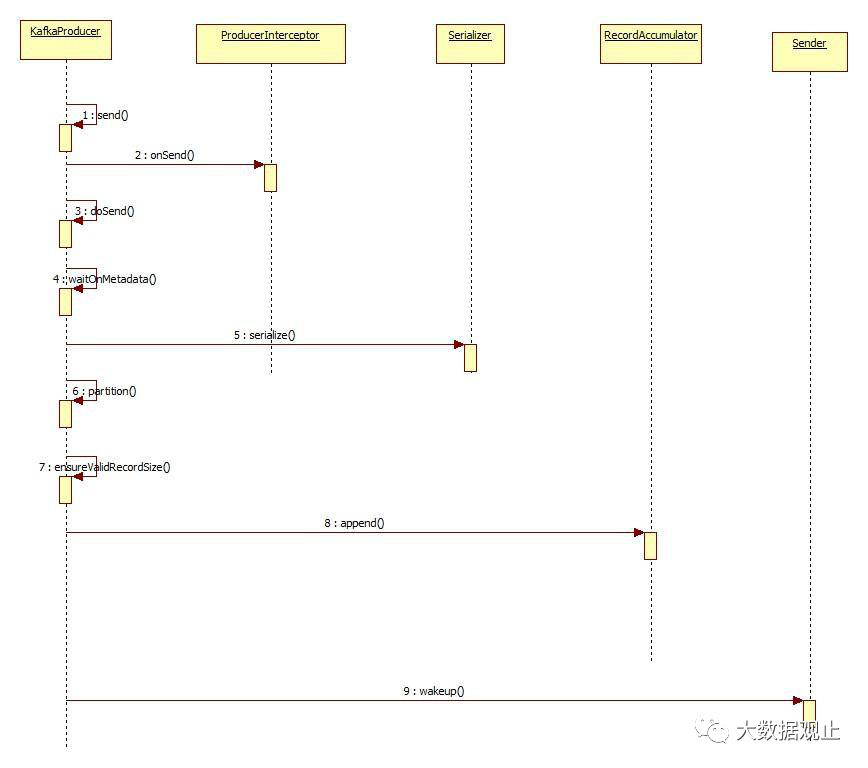 Producer发送数据流程分析
二、Kafka异常体系
一直跟着分析源码的同学能感觉得到上面的代码就是KafkaProducer的核心流程。这也是我们为什么在挑这个时候讲Kafka是如何构造异常体系的原因,一般在项目的核心流程里面去观察这个项目的异常体系会看得比较清晰,大家发现这个流程里面捕获了很多异常:
Producer发送数据流程分析
二、Kafka异常体系
一直跟着分析源码的同学能感觉得到上面的代码就是KafkaProducer的核心流程。这也是我们为什么在挑这个时候讲Kafka是如何构造异常体系的原因,一般在项目的核心流程里面去观察这个项目的异常体系会看得比较清晰,大家发现这个流程里面捕获了很多异常:

 - 关注“大数据观止” -
- 关注“大数据观止” -

//因为生产中开发使用的是异步的方式发送的消息,所以我这儿直接贴的代码//就是异步发送的代码,大家注意这个代码里面传进去了两个参数//一个是消息//一个是回调函数,这个回调函数很重要,每个消息发送完成以后这个回调函数都会被//执行,我们可以根据这个回调函数返回来的信息知道消息是否发送成功,//做相对应的应对处理。这种传递回调函数的代码设计方式也值得我们积累,这样可以增加用户开发代码时候的灵活性。
producer.send(new ProducerRecord<>(topic,
messageNo,
messageStr), new DemoCallBack(startTime, messageNo, messageStr));private Future doSend(ProducerRecord record, Callback callback) {
TopicPartition tp = null;try {// first make sure the metadata for the topic is available//第一步:阻塞等待获取集群元数据//maxBlockTimeMs 获取元数据最多等待的时间
ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);//最多等待的时间减去等待元数据花的时间等于还可以在等待的时间
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);//集群元数据信息
Cluster cluster = clusterAndWaitTime.cluster;//第二步:对key和value进行序列化
byte[] serializedKey;try {
serializedKey = keySerializer.serialize(record.topic(), record.key());
} catch (ClassCastException cce) {throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +" specified in key.serializer");
}
byte[] serializedValue;try {
serializedValue = valueSerializer.serialize(record.topic(), record.value());
} catch (ClassCastException cce) {throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +" specified in value.serializer");
}//第三步:根据分区器选择合适的分区
int partition = partition(record, serializedKey, serializedValue, cluster);//第四步:计算消息的大小
int serializedSize = Records.LOG_OVERHEAD + Record.recordSize(serializedKey, serializedValue);//确认消息是否超出限制
ensureValidRecordSize(serializedSize);//第五步:根据元数据获取到topic信息,封装分区对象
tp = new TopicPartition(record.topic(), partition);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);// producer callback will make sure to call both 'callback' and interceptor callback//第六步:设置回调对象
Callback interceptCallback = this.interceptors == null ? callback : new InterceptorCallback<>(callback, this.interceptors, tp);//第七步:把消息追加到accumulator对象中
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);//消息存入accumulator中,如果一个批次满了,或者是创建了一个新的批次//那么唤醒sender线程,让sender线程开始干活,至于干什么活,我们后面//再去分析if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);//第八步:唤醒sender线程this.sender.wakeup();
}return result.future;// handling exceptions and record the errors;// for API exceptions return them in the future,// for other exceptions throw directly
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);if (callback != null)
callback.onCompletion(null, e);this.errors.record();if (this.interceptors != null)this.interceptors.onSendError(record, tp, e);return new FutureFailure(e);
} catch (InterruptedException e) {this.errors.record();if (this.interceptors != null)this.interceptors.onSendError(record, tp, e);throw new InterruptException(e);
} catch (BufferExhaustedException e) {this.errors.record();this.metrics.sensor("buffer-exhausted-records").record();if (this.interceptors != null)this.interceptors.onSendError(record, tp, e);throw e;
} catch (KafkaException e) {this.errors.record();if (this.interceptors != null)this.interceptors.onSendError(record, tp, e);throw e;
} catch (Exception e) {// we notify interceptor about all exceptions, since onSend is called before anything else in this methodif (this.interceptors != null)this.interceptors.onSendError(record, tp, e);throw e;
}
} } catch (ApiException e) {
log.debug("Exception occurred during message send:", e);if (callback != null)
callback.onCompletion(null, e);this.errors.record();if (this.interceptors != null)this.interceptors.onSendError(record, tp, e);return new FutureFailure(e);
} catch (InterruptedException e) {this.errors.record();if (this.interceptors != null)this.interceptors.onSendError(record, tp, e);throw new InterruptException(e);
} catch (BufferExhaustedException e) {this.errors.record();this.metrics.sensor("buffer-exhausted-records").record();if (this.interceptors != null)this.interceptors.onSendError(record, tp, e);throw e;
} catch (KafkaException e) {this.errors.record();if (this.interceptors != null)this.interceptors.onSendError(record, tp, e);throw e;
} catch (Exception e) {// we notify interceptor about all exceptions, since onSend is called before anything else in this methodif (this.interceptors != null)this.interceptors.onSendError(record, tp, e);throw e;
}//检查要发送的这个消息大小, 检查是否超过了请求大小和内存缓冲大小。
ensureValidRecordSize(serializedSize);private void ensureValidRecordSize(int size) {//默认值1M,如果超过1M抛异常if (size > this.maxRequestSize)throw new RecordTooLargeException("The message is " + size +" bytes when serialized which is larger than the maximum request size you have configured with the " +
ProducerConfig.MAX_REQUEST_SIZE_CONFIG +" configuration.");//不能超过内存缓冲的大小,如果超过内存大小抛异常if (size > this.totalMemorySize)throw new RecordTooLargeException("The message is " + size +" bytes when serialized which is larger than the total memory buffer you have configured with the " +
ProducerConfig.BUFFER_MEMORY_CONFIG +" configuration.");
}














 2600
2600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









