






前面我们一直操作的是,通过一个文件来读取数据,这个里面不涉及数据相关的只是,今天我们来介绍一下spark操作中存放与读取
1.首先我们先介绍的是把数据存放进入mysql中,今天介绍的这个例子是我们前两篇介绍的统计IP的次数的一篇内容,最后的返回值类型是List((String,Int))类型的,其内容是为:

此时,我们只需要在写一个与数据库相连接,把数据放入里面即可,这个方法为data2Mysql
val data2MySQL = (iterator:Iterator[(String,Int)]) =>{var conn:Connection = null
var ps:PreparedStatement = nullval sql= "INSERT INTO location_info1 (location,counts,accesse_date) VALUES(?,?,?)"
try{
conn= DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?useUnicode=true&characterEncoding=UTF-8", "root", "root")
iterator.foreach(line =>{
ps=conn.prepareStatement(sql)
ps.setString(1,line._1)
ps.setInt(2,line._2)
ps.setDate(3,newDate(System.currentTimeMillis()))
ps.executeUpdate()
})
}catch{case e:Exception => println("Mysql Exception")
}finally{if(ps != null)
ps.close()if(conn != null)
conn.close()
}
}
则此时整体代码为:
package cn.wj.spark.day06
import java.sql.{Connection, Date, DriverManager, PreparedStatement}
import org.apache.spark.{SparkConf, SparkContext}/**
* Created by WJ on 2017/1/4.*/
objectIPLocation {
val data2MySQL= (iterator:Iterator[(String,Int)]) =>{var conn:Connection = null
var ps:PreparedStatement = nullval sql= "INSERT INTO location_info1 (location,counts,accesse_date) VALUES(?,?,?)"
try{
conn= DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?useUnicode=true&characterEncoding=UTF-8", "root", "root")
iterator.foreach(line =>{
ps=conn.prepareStatement(sql)
ps.setString(1,line._1)
ps.setInt(2,line._2)
ps.setDate(3,newDate(System.currentTimeMillis()))
ps.executeUpdate()
})
}catch{case e:Exception => println("Mysql Exception")
}finally{if(ps != null)
ps.close()if(conn != null)
conn.close()
}
}
def ip2Long(ip: String): Long={
val fragments= ip.split("[.]")var ipNum = 0L
for (i
ipNum= fragments(i).toLong | ipNum << 8L}
ipNum
}
def binarySearch(lines:Array[(String,String,String)],ip:Long) :Int={var low = 0
var high = lines.length -1
while(low <=high){
val middle= (low + high) / 2
if((ip >= lines(middle)._1.toLong) && (ip <=lines(middle)._2.toLong))returnmiddleif(ip
high= middle -1
else{
low= middle + 1}
}-1}
def main(args: Array[String]): Unit={
val conf= new SparkConf().setAppName("IPLocation").setMaster("local[2]")
val sc= newSparkContext(conf)
val ipRulesRdd= sc.textFile("e://Test/ip.txt").map(lines =>{
val fields= lines.split("\\|")
val start_num= fields(2)
val end_num= fields(3)
val province= fields(6)
(start_num,end_num,province)
})//全部的IP映射规则
val ipRulesArrary =ipRulesRdd.collect()//广播规则,这个是由Driver向worker中广播规则
val ipRulesBroadcast =sc.broadcast(ipRulesArrary)//加载要处理的数据
val ipsRdd = sc.textFile("e://Test/access_log").map(line =>{
val fields= line.split("\\|")
fields(1)
})
val result= ipsRdd.map(ip =>{
val ipNum=ip2Long(ip)
val index=binarySearch(ipRulesBroadcast.value,ipNum)
val info=ipRulesBroadcast.value(index)
info
}).map(t=> {(t._3,1)}).reduceByKey(_+_)//将数据写入数据库中
result.foreachPartition(data2MySQL)
println(result.collect().toBuffer)
sc.stop()
}
}
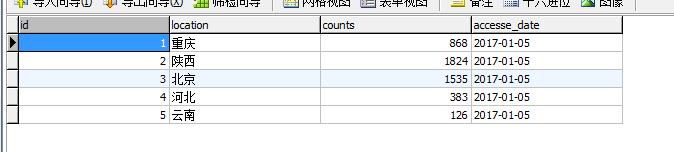
我们查询数据库,我们就可以看见
2.说完了把数据放入到数据库中,但是我跟倾向于从数据库中读取数据,然后在进行操作
例如,我们就把上面存入数据库中数据读取出来吧,主要比较懒,就是想这个样子用现成的数据库
package cn.wj.spark.day07
import java.sql.DriverManager
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by WJ on 2017/1/5.
*/
object JdbcRDDDemo_3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("JdbcRDDDemo_3").setMaster("local[2]")
val sc = new SparkContext(conf)
val connection =() =>{
Class.forName("com.mysql.jdbc.Driver").newInstance()
DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata","root","root")
}
val jdbcRDD = new JdbcRDD(
sc,
connection,
"SELECT * from location_info where id >= ? AND id <= ?",
1,5,2,
r =>{
val id = r.getInt(1)
val location = r.getString(2)
val counts = r.getInt(3)
val access_date = r.getDate(4)
(id,location,counts,access_date)
}
)
val jdbcRDDC = jdbcRDD.collect()
jdbcRDDC.map(line =>{
println("id:"+line._1)
println("location:"+line._2)
println("counts:"+line._3)
println("date:"+line._4)
println("------------------------------")
})
sc.stop
}
}
其中这个里面比较难以就是在于new JdbcRDD(),我们为什么这样写,其实当我们进入这个源码的时候,它就已经规定了这个里面写的是什么
1.sc,
2.connection,
3.sql语句
4.查询出的数据的lowereBound,upperBound,已经线程数(其实可以简单理解为分区数),这个里面我们可能回想,我就想查询出所有,为什么还要传入参数,能不能不传输上下界的参数,其实不行的,这个是代码都已近提前规定好的,就算你想全部查询完成这个整个表,你也应该让id覆盖上着整个的范围,
5.Set,其实就是一个元祖,也可以是返回来的值
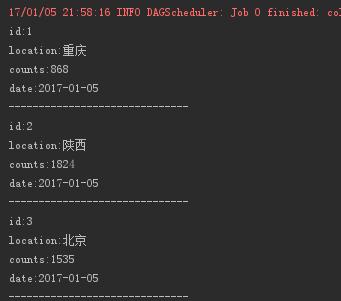
则最后的输出结果为:
最后再说一点,我们可以看到有用到foreachPartition(),这个和foreach()的区别是什么
spark操作mysql的数据库,此时如果对于foreach(),其实我们可以选择foreachPartition(),因为当我们选择foreachPartition(),这个可以拿取一整个分区的数据然后再把他放入到数据库中,如果使用foreach()的话,则是拿取一个数据放入到数据库中,建立连接,在拿取一个数据,建立连接,再放入数据库中















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









