






在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的时候全部要求输入数组或矩阵,也不能够导入文字型数据(其实手写决策树和普斯贝叶斯可以处理文字,但是sklearn中规定必须导入数值型)。
然而在现实中,许多标签和特征在数据收集完毕的时候,都不是以数字来表现的。比如说,学历的取值可以是["小学",“初中”,“高中”,"大学"],付费方式可能包含["支付宝",“现金”,“微信”]等等。在这种情况下,为了让数据适应算法和库,我们必须将数据进行编码,即是说,将文字型数据转换为数值型。
preprocessing.LabelEncoder
preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
from sklearn.preprocessing import LabelEncoder
y = data.iloc[:,-1] #要输入的是标签,不是特征矩阵,所以允许一维
le = LabelEncoder() #实例化
le = le.fit(y) #导入数据
label = le.transform(y) #transform接口调取结果
le.classes_ #属性.classes_查看标签中究竟有多少类别
label #查看获取的结果label
le.fit_transform(y) #也可以直接fit_transform一步到位
le.inverse_transform(label) #使用inverse_transform可以逆转
data.iloc[:,-1] = label #让标签等于我们运行出来的结果
data.head()
#如果不需要教学展示的话我会这么写:
from sklearn.preprocessing import LabelEncoder
data.iloc[:,-1] = LabelEncoder().fit_transform(data.iloc[:,-1])
preprocessing.OrdinalEncoder
preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值from sklearn.preprocessing import OrdinalEncoder
#接口categories_对应LabelEncoder的接口classes_,一模一样的功能
data_ = data.copy()
data_.head()
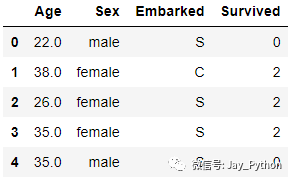
OrdinalEncoder().fit(data_.iloc[:,1:-1]).categories_
>>[array(['female', 'male'], dtype=object), array(['C', 'Q', 'S'], dtype=object)]data_.iloc[:,1:-1] = OrdinalEncoder().fit_transform(data_.iloc[:,1:-1])
data_.head()

preprocessing.OneHotEncoder
preprocessing.OneHotEncoder:独热编码,创建哑变量
我们刚才已经用OrdinalEncoder把分类变量Sex和Embarked都转换成数字对应的类别了。在舱门Embarked这一列中,我们使用[0,1,2]代表了三个不同的舱门,然而这种转换是正确的吗?
我们来思考三种不同性质的分类数据:
1) 舱门(S,C,Q)三种取值S,C,Q是相互独立的,彼此之间完全没有联系,表达的是S≠C≠Q的概念。这是名义变量。2) 学历(小学,初中,高中)三种取值不是完全独立的,我们可以明显看出,在性质上可以有高中>初中>小学这样的联系,学历有高低,但是学 历取值之间却不是可以计算的,我们不能说小学 + 某个取值 = 初中。 这是有序变量。3) 体重(>45kg,>90kg,>135kg)各个取值之间有联系,且是可以互相计算的,比如120kg - 45kg = 90kg,分类之间可以通过数学计算互相转换。这 是有距变量。然而在对特征进行编码的时候,这三种分类数据都会被我们转换为[0,1,2],这三个数字在算法看来,是连续且可以计算的,这三个数字相互不等,有大小,并且有着可以相加相乘的联系。所以算法会把舱门,学历这样的分类特征,都误会成是体重这样的分类特征。这是说,我们把分类转换成数字的时候,忽略了数字中自带的数学性质,所以给算法传达了一些不准确的信息,而这会影响我们的建模。
类别OrdinalEncoder可以用来处理有序变量,但对于名义变量,我们只有使用哑变量的方式来处理,才能够尽量向算法传达最准确的信息:
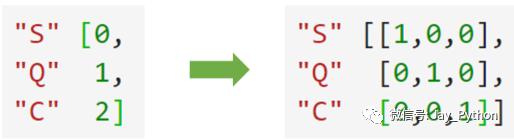
这样的变化,让算法能够彻底领悟,原来三个取值是没有可计算性质的,是“有你就没有我”的不等概念。在我们的数据中,性别和舱门,都是这样的名义变量。因此我们需要使用独热编码,将两个特征都转换为哑变量。
data.head()
from sklearn.preprocessing import OneHotEncoder
X = data.iloc[:,1:-1]
enc = OneHotEncoder(categories='auto').fit(X)
result = enc.transform(X).toarray()
result
#依然可以直接一步到位,但为了给大家展示模型属性,所以还是写成了三步
OneHotEncoder(categories='auto').fit_transform(X).toarray()
#依然可以还原
pd.DataFrame(enc.inverse_transform(result))
enc.get_feature_names()#返回每一个经过哑变量后生成稀疏矩阵列的名字
result
result.shape
#axis=1,表示跨行进行合并,也就是将两表左右相连,如果是axis=0,就是将量表上下相连
newdata = pd.concat([data,pd.DataFrame(result)],axis=1)
newdata.head()
newdata.drop(["Sex","Embarked"],axis=1,inplace=True)
newdata.columns = ["Age","Survived","Female","Male","Embarked_C","Embarked_Q","Embarked_S"]
newdata.head()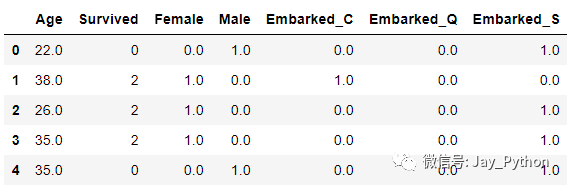
特征可以做哑变量,标签也可以吗?可以,使用类sklearn.preprocessing.LabelBinarizer可以对做哑变量,许多算法都可以处理多标签问题(比如说决策树),但是这样的做法在现实中不常见,因此我们在这里就不赘述了。

欢迎转发分享、点赞评论














 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









