





拉勾网爬虫笔记——selenium爬取拉勾网职位信息
- 初步爬虫框架构造
- 第一页职位信息爬取
- 第二页等页面的职位信息爬取
- 爬取数据的保存
- 细节处理
- 爬取过程中出现需要登录的处理
- 爬取过程中网页崩溃的处理
文末有源码以及最新python下载地址

在拉勾网的爬虫过程中,由于反爬虫机制,requests方法爬取尝试失败,故尝试采用selenium爬取职位信息,以python职位信息为例(拉勾网搜索python):
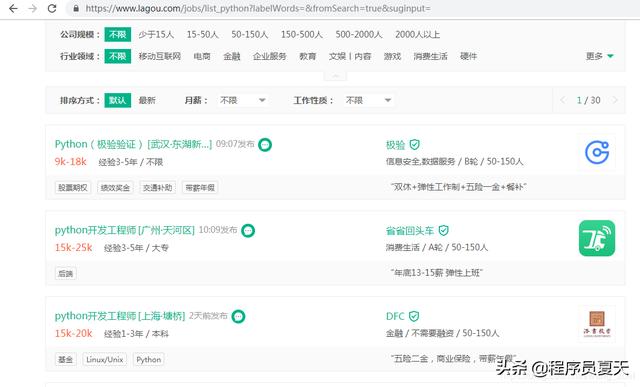
具体职位信息:
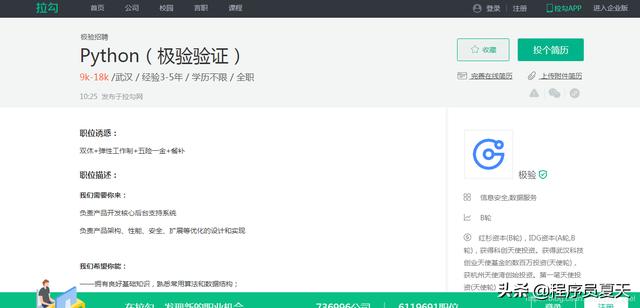
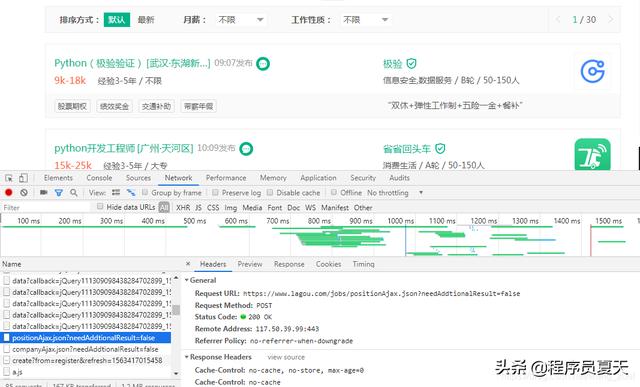
切换页面可以发现网站职位信息为ajax动态加载的,且是post请求,如下:
初步爬虫框架构造
下面采用selenium进行爬虫,首先构造一下爬虫的框架,将整个程序构造为一个类,其中主要包括:获取每个详细职位信息的链接(parse_page_url)、请求/关闭详细职位信息页面(request_detail_page)、获取详细职位信息(parse_detail_page),程序中更加细致的部分则在具体过程中依据具体问题再行添加,即为如下形式:
class lagouspider(): def __init__(self): pass def run(self): pass def parse_page_url(self): pass def request_detail_page(self): pass def parse_detail_page(self): pass def main(): lagou = lagouspider() lagou.run() main()第一页职位信息爬取
首先构造浏览器,然后打开网址(“https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=”),通过parse_page_url获取详细职位信息页面的网址。
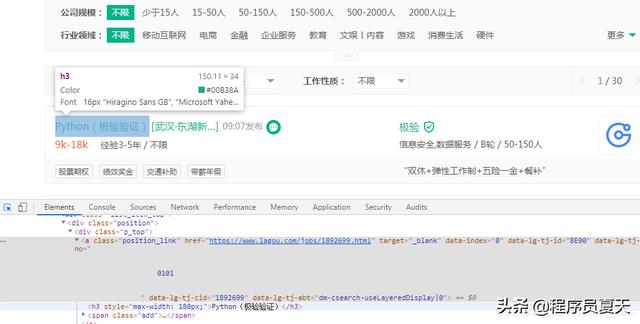
要获取每个详情页面的链接,即parse_page_url部分,f12检查可以看到具体的链接网址在href属性中,这里选择使用xpath解析(//a[@class=“position_link”]/@href):
完成后则打开具体网址进行详细职位信息的爬取(parse_detail_page):
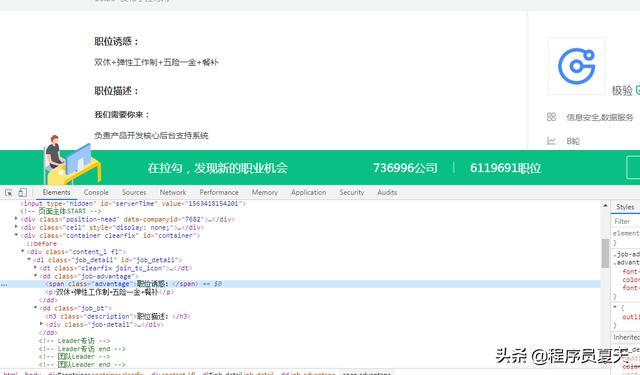
具体的根据想要爬取的内容添加就行,详细页面爬取完成后则需要关闭详细页面且回到上一个网页窗口,这里让程序暂停一秒,以免爬取过快被识别,同样在切换详情页面网址的时候也让其暂停一秒。
那么截至目前为止,可以得到大概如下的框架:
from selenium import webdriverfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.common.by import Byfrom lxml import etreeimport timeimport reclass lagouspider(): def __init__(self): self.driver = webdriver.Chrome() self.url = "https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=" # 定义一个列表存储爬取的职位信息 self.positions = [] def run(self): # 打开网页 self.driver.get(self.url) # 等待网页加载完毕再返回源码(下一页按钮) WebDriverWait(self.driver,timeout=10).until(EC.presence_of_element_located((By.XPATH,'//div[@class="pager_container"]/span[last()]'))) # 获取网页源代码 source = self.driver.page_source # 获取详细职位信息网址 self.parse_page_url(source) def parse_page_url(self,source): html = etree.HTML(source) detail_links = html.xpath('//a[@class="position_link"]/@href') for link in detail_links: # 打开详细职位信息网址 self.request_detail_page(link) # 暂停一秒,以免爬取过快 time.sleep(1) def request_detail_page(self,url): # 新建一个窗口,打开详细页面 self.driver.execute_script("window.open('%s')"%url) # 切换到详情页面窗口 self.driver.switch_to_window(self.driver.window_handles[1]) # 等待页面加载完毕再返回源码 WebDriverWait(self.driver,timeout=10).until(EC.presence_of_element_located((By.XPATH,'//span[@class="name"]'))) page_source = self.driver.page_source self.parse_detail_page(page_source) # 暂停一秒,防止爬取过快 time.sleep(1) # 关闭挡墙详情页面,并回到上一个页面窗口 self.driver.close() self.driver.switch_to_window(self.driver.window_handles[0]) def parse_detail_page(self,source): html = etree.HTML(source) # 根据具体需要添加 company_name = html.xpath("//em[@class='fl-cn']/text()")[0].strip() position_name = html.xpath("//div[@class='job-name']/@title")[0] job_request = html.xpath("//dd[@class='job_request']//span") salary = job_request[0].xpath(".//text()")[0].strip() city = job_request[1].xpath(".//text()")[0].strip() # 去除特殊符号和空格 city = re.sub("[s/]","",city) experience = job_request[2].xpath(".//text()")[0].strip() experience = re.sub("[s/]","",experience) education = job_request[3].xpath(".//text()")[0].strip() education = re.sub("[s/]","",education) full_or_part = job_request[4].xpath(".//text()")[0].strip() full_or_part = re.sub("[s/]","",full_or_part) job_advantage = html.xpath("//dd[@class='job-advantage']/p/text()")[0].strip() job_describe = "".join(html.xpath("//dd[@class='job_bt']//text()")) position = { 'company_name':company_name, 'position_name':position_name, 'salary':salary, 'city':city, 'experience':experience, 'education':education, 'full_or_part':full_or_part, 'job_describe':job_describe, 'job_advantage':job_advantage } # print(position) self.positions.append(position) def main(): lagou = lagouspider() lagou.run() main()第二页等页面的职位信息爬取
这样,第一页的职位信息就可以爬取成功了,下面就要考虑后面页面的职位信息爬取问题,这时候就需要模拟翻页操作,这里采取while True循环来处理翻页爬取,爬取完一页后继续循环翻页爬取。
同时可以观察得知,网页中的翻页最多翻页至30页,那么也就是说可以将此作为循环的结束条件,将run更改为如下:
def run(self): # 打开网页 self.driver.get(self.url) while True: # 等待网页加载完毕再返回源码(下一页按钮) WebDriverWait(self.driver,timeout=10).until(EC.presence_of_element_located((By.XPATH,'//div[@class="pager_container"]/span[last()]'))) # 获取网页源代码 source = self.driver.page_source # 获取详细职位信息网址 self.parse_page_url(source) nextpage_btn = self.driver.find_element_by_xpath('//div[@class="pager_container"]/span[@action="next"]') # 若没有下一页则跳出循环,完成爬取 if 'pager_next pager_next_disabled' in nextpage_btn.get_attribute("class"): print("爬取完成!") break else: nextpage_btn.click() time.sleep(1)爬取数据的保存
完成翻页操作后,则考虑数据的保存问题,由于爬取的数据较多,拉勾网在爬取一段时间后容易崩溃,很难一次性爬取完成,故选择每爬取一页内容就保存一次,这里使用xlwings进行保存,单独使用一个save_positions进行保存操作。
import xlwings as xwimport pandas as pddef save_positions(self): save_positions = pd.DataFrame(self.positions) # 重新开始保存下一页 self.positions = [] row = 1 + 16 * self.save_count self.save_count += 1 print('已保存%d页'%self.save_count) print('*'*30) self.sheet.range('A'+str(row)).value = save_positions self.position_file.save()细节处理
爬取过程中出现需要登录的处理
在爬取过程中,出现了需要登录,那么这里选择在爬取操作前登录账号,则可避免爬取过程中出现需要登录而中断爬取的情况,添加如下函数,这里需要注意的是在登录过程中会出现验证码,这里设置了15秒的时间输入一般是够了的,快一点输入就行(注意代码中账号密码要修改成自己的):
from selenium.webdriver.common.action_chains import ActionChainsdef login(self): loginTag = self.driver.find_element_by_css_selector('.login') usernameTag = self.driver.find_element_by_xpath("//input[@type='text']") passwordTag = self.driver.find_element_by_xpath("//input[@type='password']") login = self.driver.find_element_by_xpath("//div[@class='login-btn login-password sense_login_password btn-green']") actions = ActionChains(self.driver) actions.move_to_element(loginTag) actions.click(loginTag) actions.send_keys_to_element(usernameTag,'账号') actions.send_keys_to_element(passwordTag,'密码') actions.move_to_element(login) actions.click(login) actions.perform() # 15秒内输入验证码 time.sleep(15)爬取过程中网页崩溃的处理
同时在爬取过程中若网页崩溃,重新爬取不现实,那么这里再添加一个爬取前选择从第几页开始爬取的函数,保存后显示保存了几页的数据,方便在网页崩溃后继续爬取,
def continue_spider(self,num): self.count_num = 15*num + 1 self.save_count = num - 1 # 当前页面页码 current_page = 1 # 循环-翻页操作 while True: if current_page == num: break else: # 下一页按钮 next_page_Btn = self.driver.find_element_by_xpath("//div[@class='pager_container']/span[last()]") actions = ActionChains(self.driver) actions.move_to_element(next_page_Btn) actions.click(next_page_Btn) actions.perform() current_page += 1 time.sleep(1)














 6798
6798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









