






前文分析了Workload repository report for (负载信息库报告)、Report Summary(报告摘要),接下来一项重要的事情是关于等待事件统计。
等待事件统计主要包括以下信息:
时间模式统计
操作系统统计
操作系统统计详细信息
前台等待类
前台等待事件
后台等待事件
等待事件直方图
等待事件直方图详细信息(64毫秒到2秒)
等待事件直方图详细信息(4秒到2分钟)
等待事件直方图详细信息(4分钟到1小时)
服务统计
服务等待类统计
首先看一下Time Model Statistics,此处已经按时间做了排序了
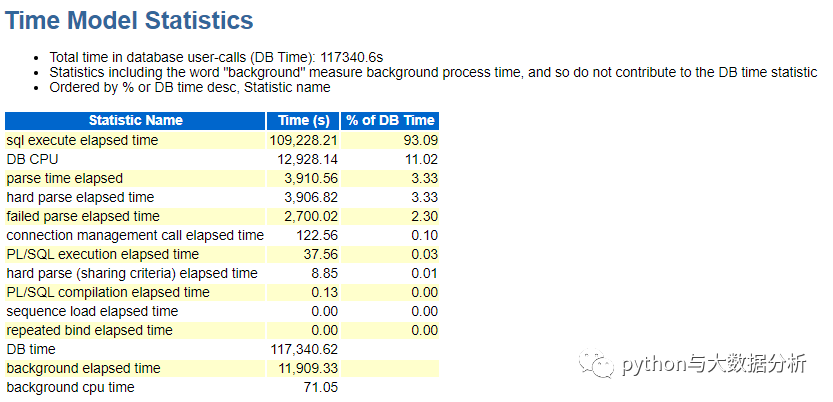
DB time=117340.62秒,24核CPU,所以DB time %=117340.62/24/60/2/60=67.91%,和负载信息库报告的数据库CPU负载率68.08%非常接近了。
sql execute elapsed time 数据库执行SQL总时间
DB CPU 用户占用CPU的总时间
parse time elapsed 解释SQL总时间
hard parse elapsed time 硬解释SQL的总时间
failed parse elapsed time 解释SQL失败的总时间
说实在的单纯看总时间和比例,是无法准确定位的。
再来看一下Operating System Statistics
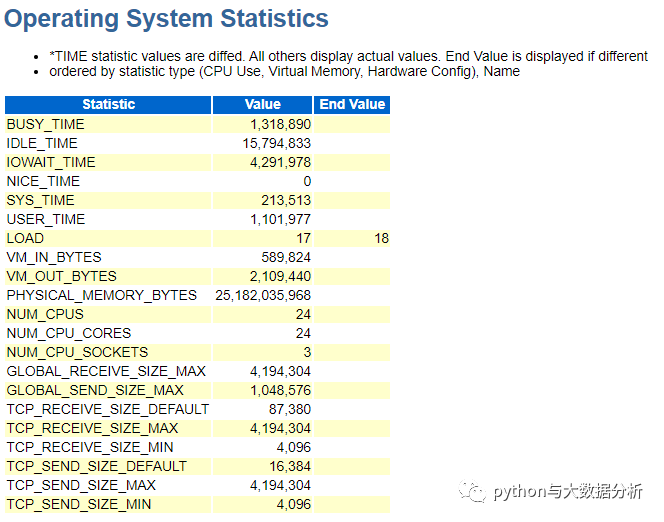
%User = USER_TIME/(BUSY_TIME+IDLE_TIME)*100
%Sys = SYS_TIME/(BUSY_TIME+IDLE_TIME)*100
%Idle = IDLE_TIME/(BUSY_TIME+IDLE_TIME)*100
关于Operating System Statistics-Detail
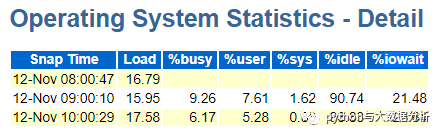
这里需要注意%iowait,他代表CPU在等待io操作完成,这个可能是io过慢或者io操作过多导致。
关于前台进程等待事件类型(用户触发)
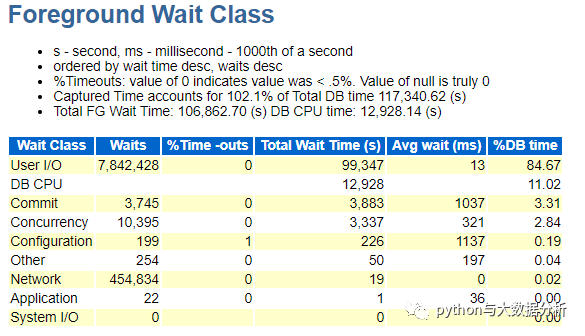
值得关注的是User I/O,无论从次数还是时间上占比都很高,但Commit和Configuration的平均等待时长在1秒左右,值得关注,commit主要包括log file sync(日志文件同步),Configuration包括free buffer waits,undo,temp,锁等相关事件,总的来说IO有些瓶颈。

关于前台进程等待事件(用户触发)
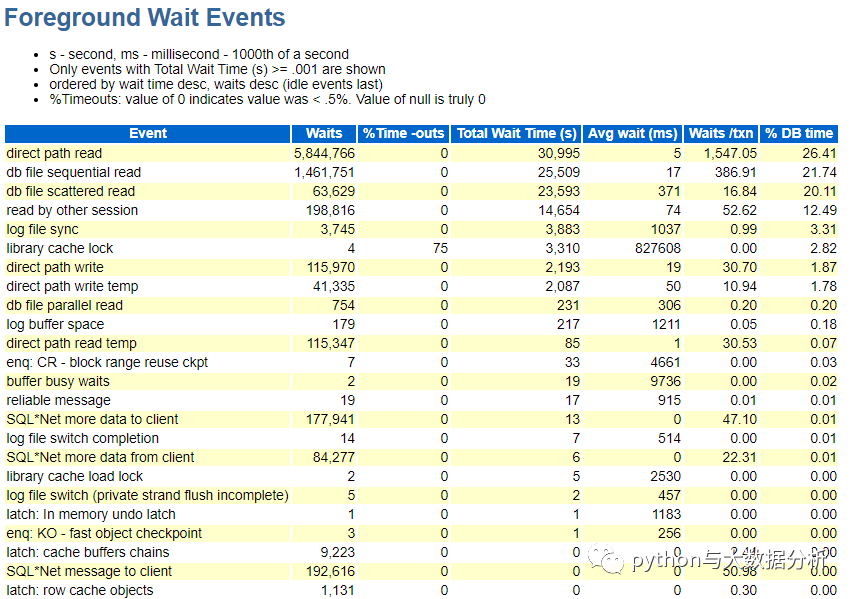
按常规先排序,再定位问题。

主要问题集中在direct path read,db file sequential red的总等待次数,但是这两个指标的等待时长不算长;
direct path read这个等待事件发生在会话将数据块直接读取到PGA当中而不是SGA中的情况,这些被读取的数据通常是这个会话私有的数据,所以不需要放到SGA作为共享数据,因为这样做没有意义。这些数据通常是来自与临时段上的数据,比如一个会话中SQL的排序数据,并行执行过程中间产生的数据,以及Hash Join,merge join产生的排序数据,因为这些数据只对当前的会话的SQL操作有意义,所以不需要放到SGA当中。当发生direct path read等待事件时,意味着磁盘上有大量的临时数据产生,比如排序、并行执行等操作,或者意味着PGA中空闲空间不足。
SQL*Net message from client 空闲等待 如果网络没有问题,一般不需要关注;db file scatterd read 的总等待时长和DB时间占比比较高,离散读是物理读的一种方式,这里的离散指的是读取数据块到一块离散(不连续)的内存区域,而且一般读取多个数据块( multi-block read),可能为单个数据库。多数据块读(multi-block read)是由SQL语句引起的(用户发出或者递归调用)
一般发生在以下情况:
全表扫描( full table scans )
索引快速全扫描( index fast full scans)
具体可以参见《关于Oracle 数据块、B树索引和5种索引扫描》一文。
另一个严重的问题是library cache lock,次数很少,但等待时间却很长,library cache lock是在访问或修改库高速缓冲期的对象时,对库高速缓冲区具柄获得的锁,在获取library cache lock的过程中,如果发生争用,则等待library cache lock事件。可能发生library cache pin和library cache lock的情况:
1、在存储过程或者函数正在运行时被编译。
2、在存储过程或者函数正在运行时被对它们进行授权、或者移除权限等操作。
3、对某个表执行DDL期间,有另外的会话对该表执行DML或者DDL。
4、PL/SQL对象之间存在复杂的依赖性
5、长时间执行不出来的SQL
6、OS僵死进程
关于处理library cache lock的步骤
--获得持有该library cache lock的session,SQL如下:
SELECT a.SID,a.SERIAL#,a.username,a.osuser,a.program,
b.addr,b.kglpnadr,b.kglpnuse,b.kglpnses,b.kglpnhdl,
b.kglpnlck,b.kglpnmod,b.kglpnreq
FROM v$session a, x$kglpn b
WHERE a.saddr = b.kglpnuse
AND b.kglpnmod <> 0
AND b.kglpnhdl IN
(SELECT p1raw FROM v$session_wait WHERE event = 'library cache lock');
--查询session的等待事件,SQL如下:
SELECT sql_id,sid,serial#,username,osuser,program,machine,event
FROM v$session v
WHERE v.sid=&sid AND v.SERIAL#=&serial;
--查询具体的SQL信息
select SQL_TEXT from V$SQL where SQL_ID='gsmd1w6vybas2';
--也可以合起来查询,根据得到的sid,查询当前该sid进行的操作
SELECT sql_text,sql_id
FROM v$sqltext a
WHERE a.hash_value = (SELECT sql_hash_value
FROM v$session b
WHERE b.SID = &sid)
ORDER BY piece ASC
--查询ORACLE session对应的OS进程spid的SQL如下:
SELECT p.spid, s.sid, s.SERIAL#
FROM v$process p, v$session s
WHERE p.ADDR = s.PADDR
AND s.SID = &sid
AND s.SERIAL# = &serial;
--kill -9 p.spid
关于后台等待事件,这部分是以后台进程的等待事件来进行排序的,让我们知道后台等待事件哪些占用的比例高
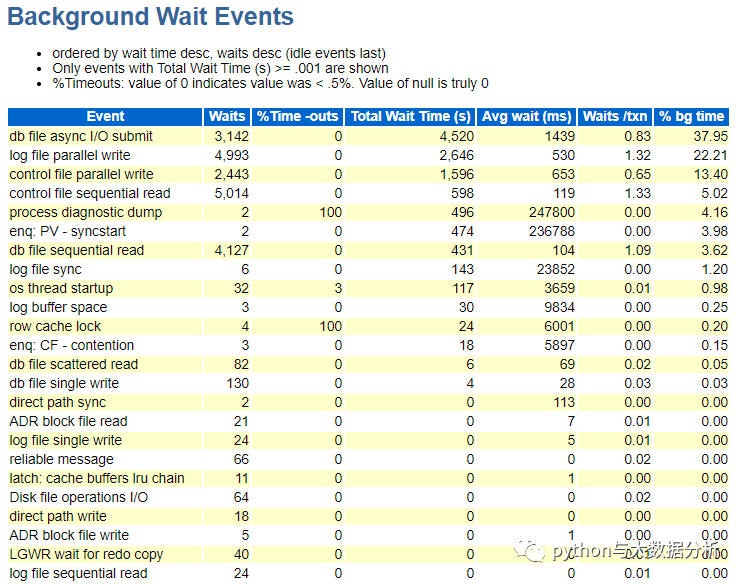
老规矩,先排序,再分析;
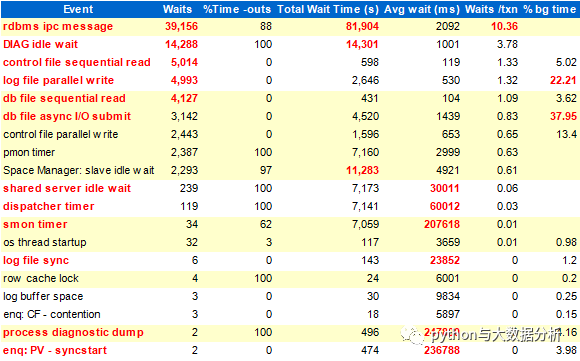
rdbms ipc message等待事件表示LGWR空闲,他等待这个事件3秒超时后,开始写一次redo,一般也属正常。其他指标,smon timer,process diagnostic dump和enq:PV - syntstart















 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









