





接着上一篇Python和wind的交互,本文讲解如何用Python和excel进行交互,包括读取excel和输入到excel。
学习一门新知识的时候,有时候觉得很难,很可能是因为讲的不够好,而并非自身学习能力不行。本文是我在初学的时候的总结,希望能帮到初学者。 一、读取和写入excel—基础篇 首先我们先安装好所需要模块,安装方法在前一篇文章Python和wind的交互—在债券中的应用详细介绍了。读写excel,需要安装pandas、xlwt、xlrd、openpyxl模块。 导入pandas模块,代码:import pandas as pd。一般这句话每次使用时都最好写上这句话,用pandas来处理excel非常方便。现在可以开始读入excel了,比如我的excel格式是这样的。 在pycharm的Python console里输入:
data=pd.read_excel(r"C:\bao\估值研究\test.xlsx")
即可将我文件夹C:\bao\估值研究\test.xlsx里的名为test的excel文件读入进去,这句代码非常简单,pd.read_excel后面括弧里加入excel所在的文件路径即可,前面加上r,主要是因为Python识别不了中文,现在暂时不用知道其原理。
在pycharm的Python console里输入:
data=pd.read_excel(r"C:\bao\估值研究\test.xlsx")
即可将我文件夹C:\bao\估值研究\test.xlsx里的名为test的excel文件读入进去,这句代码非常简单,pd.read_excel后面括弧里加入excel所在的文件路径即可,前面加上r,主要是因为Python识别不了中文,现在暂时不用知道其原理。
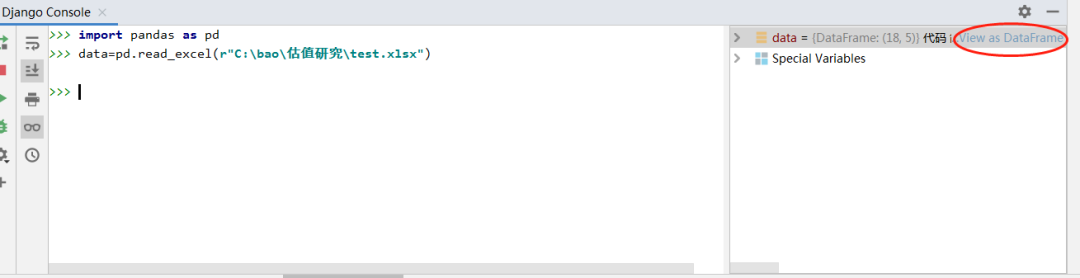 这样excel就被读入到data变量里了,在上图右侧view as dataframe,点击就可以以表格的形式呈现数据,格式也非常好
这样excel就被读入到data变量里了,在上图右侧view as dataframe,点击就可以以表格的形式呈现数据,格式也非常好
 读取完后之后,现在如果我们想把pycharm里的变量data再输出到我文件夹的excel里,也是用一句话就可以实现
data.to_excel(r"C:\bao\估值研究\result.xlsx")
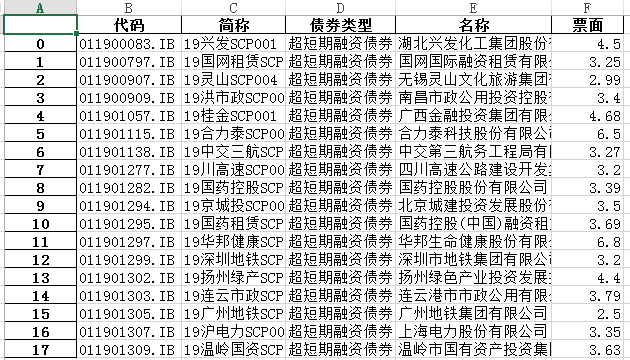
随便给excel起一个名字为result,和读取excel非常相像,输出后便可在我们指定的文件位置看见一个result的excel文件,打开它,发现多了一列索引:
读取完后之后,现在如果我们想把pycharm里的变量data再输出到我文件夹的excel里,也是用一句话就可以实现
data.to_excel(r"C:\bao\估值研究\result.xlsx")
随便给excel起一个名字为result,和读取excel非常相像,输出后便可在我们指定的文件位置看见一个result的excel文件,打开它,发现多了一列索引:
 至此,简单的Python读取excel和输出到excel就实现了,如果想学习更复杂的读取和写入,看第二和第三部分。
二、中阶篇
我们在用excel中可能会存在很多个性化的需求,比如一个excel里有很多sheet,我只想要某个sheet,或者有些sheet太多行和列我只想用某个指定的区域
1、读取指定位置
pd.read_excel里有几十个参数可以选,但是没必要掌握所有的用法,只需要掌握我们日常工作最为常用的几个就可以。
(1)读取指定的sheet:sheet_name参数
增加参数,只需要往括号里加入参数名=XX即可,参数位置也不分前后,pycharm还有自动提示功能,非常智能。比如我想读取sheet名为bao的数据,只需在后面加一句sheet_name='bao',如果sheet没有命名,第一个sheet则输入sheet_name=0,第二个sheet则输入sheet_name=1,依次类推。
data=pd.read_excel(r"C:\bao\估值研究\test.xlsx",sheet_name='bao')
(2)读取指定的列:usecols参数
在我的test文件里,如果我只想要指定的A列和D列,只需usecols='A,D'即可只读取A列和D列,如果需要A、B、C列和E列,usecols='A:C,E'
data=pd.read_excel(r"C:\bao\估值研究\test.xlsx",usecols='A,D')
(3)跳过指定的行:skiprows和nrows参数
由于我们的数据基本上是,列是要素,行是数据,通常行数会很多。因此会有usecols是选择指定列,而到了行则是跳过指定的行。比如我们每天的excel数据是一直往下新增的,我可能只需读取后面新增的数据,这样就可以通过跳过前面若干行来实现。
data=pd.read_excel(r"C:\bao\估值研究\test.xlsx",skiprows = [1, 2, 4])
这句代码就可以跳过第2、3、5行。如果想跳过前10行,skiprows=10即可。
2、输出到excel
(1)去掉索引列
在第一部分可以发现输入到excel里会多一个索引列0、1、2等,这是因为pandas会自动把索引列输出,可以加上index=False。
data.to_excel(r"C:\bao\估值研究\result.xlsx",index=False)
(2)同时输出多个数据到不同的sheet里
比如我们想把data放入第一个sheet(命名为bao),data1放入第二个sheet里(命名为yu),则可以用下面几句代码
writer = pd.ExcelWriter(r"C:\bao\估值研究\aa.xlsx")
至此,简单的Python读取excel和输出到excel就实现了,如果想学习更复杂的读取和写入,看第二和第三部分。
二、中阶篇
我们在用excel中可能会存在很多个性化的需求,比如一个excel里有很多sheet,我只想要某个sheet,或者有些sheet太多行和列我只想用某个指定的区域
1、读取指定位置
pd.read_excel里有几十个参数可以选,但是没必要掌握所有的用法,只需要掌握我们日常工作最为常用的几个就可以。
(1)读取指定的sheet:sheet_name参数
增加参数,只需要往括号里加入参数名=XX即可,参数位置也不分前后,pycharm还有自动提示功能,非常智能。比如我想读取sheet名为bao的数据,只需在后面加一句sheet_name='bao',如果sheet没有命名,第一个sheet则输入sheet_name=0,第二个sheet则输入sheet_name=1,依次类推。
data=pd.read_excel(r"C:\bao\估值研究\test.xlsx",sheet_name='bao')
(2)读取指定的列:usecols参数
在我的test文件里,如果我只想要指定的A列和D列,只需usecols='A,D'即可只读取A列和D列,如果需要A、B、C列和E列,usecols='A:C,E'
data=pd.read_excel(r"C:\bao\估值研究\test.xlsx",usecols='A,D')
(3)跳过指定的行:skiprows和nrows参数
由于我们的数据基本上是,列是要素,行是数据,通常行数会很多。因此会有usecols是选择指定列,而到了行则是跳过指定的行。比如我们每天的excel数据是一直往下新增的,我可能只需读取后面新增的数据,这样就可以通过跳过前面若干行来实现。
data=pd.read_excel(r"C:\bao\估值研究\test.xlsx",skiprows = [1, 2, 4])
这句代码就可以跳过第2、3、5行。如果想跳过前10行,skiprows=10即可。
2、输出到excel
(1)去掉索引列
在第一部分可以发现输入到excel里会多一个索引列0、1、2等,这是因为pandas会自动把索引列输出,可以加上index=False。
data.to_excel(r"C:\bao\估值研究\result.xlsx",index=False)
(2)同时输出多个数据到不同的sheet里
比如我们想把data放入第一个sheet(命名为bao),data1放入第二个sheet里(命名为yu),则可以用下面几句代码
writer = pd.ExcelWriter(r"C:\bao\估值研究\aa.xlsx")
data.to_excel(writer,'bao')
data1.to_excel(writer,'yu')writer.save()第一句里括弧放入的路径可以是新建命名的excel,也可以是原来就存在该路径下文件(有时候我想将数据返回到我的原始文件中)。第二句和第三句是写入不同的sheet,第四句是保存文件。(3)输入到excel指定的位置如果我只想将data输入到excel的指定位置,比如想输入到excel中第三行和第三列为起始位置。import os,glob
file=glob.glob(os.path.join(r"C:\bao\估值研究","a*.xlsx"))
dl=[]for f in file:
dl.append(pd.read_excel(f))
df=pd.concat(dl)














 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









