







文献信息:兰巨龙,张学帅,胡宇翔,孙鹏浩.基于深度强化学习的软件定义网络QoS优化[J].通信学报,2019,40(12):60-67.
原文链接:http://www.infocomm-journal.com/txxb/CN/10.11959/j.issn.1000-436x.2019227
摘要:
为解决软件定义网络场景中,当前主流的基于启发式算法的QoS优化方案常因参数与网络场景不匹配出现性能下降的问题,提出了基于深度强化学习的软件定义网络QoS优化算法。首先将网络资源和状态信息统一到网络模型中,然后通过长短期记忆网络提升算法的流量感知能力,最后基于深度强化学习生成满足QoS目标的动态流量调度策略。实验结果表明,相对于现有算法,所提算法不但保证了端到端传输时延和分组丢失率,而且提高了22.7%的网络负载均衡程度,增加了8.2%的网络吞吐率。
引言
背景意义
当前,以软件定义网络(SDN, software-defined networking)为代表的新型网络结构正促进互联网领域的重大变革。SDN将原来高度耦合的控制逻辑与转发行为解耦,通过控制平面的开放接口获得全局网络视图,并提供给上层网络服务程序,实现了对全网的集中统一控制。因此,结合 SDN 的优势,充分发挥现有网络潜能,提高网络资源利用率,改善网络传输性能,对保证网络的服务质量有重要意义
本文贡献
文章将长短期记忆(LSTM, long short-term memory)网络与DRL相结合,设计了软件定义网络的QoS优化机制,从而使SDN能够在满足QoS目标的基础上完成数据流调度。
具体而言,文章主要贡献包括以下3个方面。
1) 架构层面,提出了针对网络数据流的自动控制架构,实现了对数据流的自动化控制与调度。
2) 建模层面,通过建立软件定义网络 QoS 优化模型,引入经改进的深度强化学习算法对问题进行求解。
3) 实现层面,搭建了软件定义网络 QoS 优化实验环境,通过测试验证了算法的有效性。
QoS优化架构与建模:
- QoS 优化架构
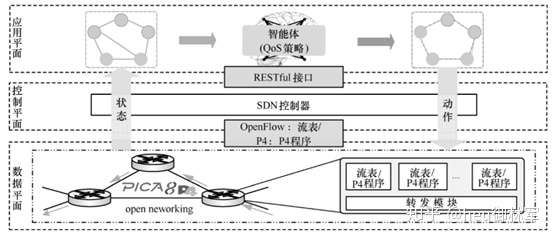
文章提出的软件定义网络 QoS 优化架构的主要结构如图 1 所示,其中,各平面的具体介绍如下:
1) 数据平面。主要由一系列可编程交换机组成,接收控制器经南向接口发送控制策略并完成对数据分组的监测、处理和转发等操作,具体地,控制策略的载体可以是 OpenFlow 流表[15]或P4 程序[16]。
2) 控制平面。负责连接应用平面与数据平面, 维护全网视图,向下传递控制策略,向上将底层网络资源信息通过北向接口提供给应用平面。在北向接口选取上,基于 REST架构的RESTful[17]在响应 时间方面表现出了特有优势,因此架构中采用RESTful 作为控制平面与应用平面的通信接口,以保证两平面间的通信效率。
3) 应用平面。运行负责网络 QoS 优化的强化学习智能体,智能体通过控制平面提供的全网逻辑视图和数据平面网络资源信息生成控制策略,而后将控制策略经北向接口向控制平面下发。
- QoS优化模型
定义1:链路利用率
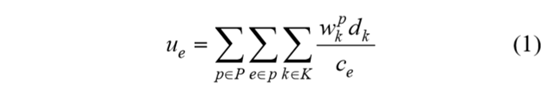
其中
定义2:网络使用率 U。网络使用率定义为各链路利用率的最大值,如式(2)所示
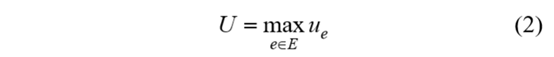
定义3:负载均衡程度
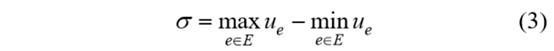
基于以上分析,软件定义网络 QoS 优化问题可以建模为:
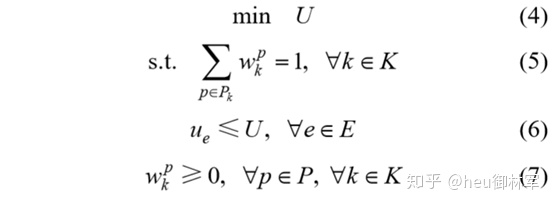
其中,式(4)为优化目标,即最小化网络利用率 U;式(5)表示网络节点对间的所有流请求都分配到节点对间的转发路径上;式(6)确保任意链路的链路利用率不超过网络使用率;式(7)表示分配至各转发路径上的流不能为负值。
算法设计
- 强化学习算法
在一个典型的强化学习模型中,智能体与环境彼此交互状态(state)、动作(action)、奖赏(reward)信息,通过训练逐步取得优化目标。在软件定义网络 QoS 优化问题中,状态、动作、 奖赏的具体含义如下所示:
状态(state)。在此模型中,状态是指某一次网络测量[18]时网络中的流请求信息和所有链路的时延和利用率信息,用向量
动作(action)。动作是指强化学习智能体根据 QoS策略函数和网络状态信息
奖赏(reward)。奖赏是对上一次动作所获收益的 QoS 评价。本模型中,软件定义网络 QoS 优化模型的优化目标是最小化网络使用率U,为最大化奖赏符合优化目标,定义奖赏为U的相反数。
- QoS优化算法
文章采用基于Actor-Critic框架的强化学习算法与神经网络相结合而生成的DDPG(Deep Deterministic Policy Gradient)算法,该算法中共包括四个神经网络,即在线Q网络、在线策略网络、目标Q网络、目标策略网络。注意到,在网络场景中,网络状态常常随时间变化,具有明显的时间相关性,LSTM 在处理和预测表现出明显时间相关性的数据中取得了优良的成果[14]。本文在 DDPG 的基础上,引入LSTM 层提出R-DRL算法,如图 2 所示。
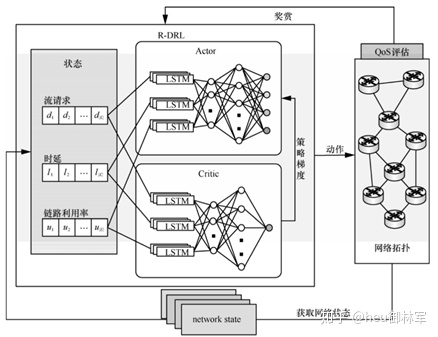
在训练过程中,LSTM网络负责对网络状态信息 s 进行预处理生成隐含状态 h,并将该隐含状态传输给 Actor 和 Critic 架构中的神经网络,提高神经网络的决策的效率和准确性;Actor 和 Critic 架构中的神经网络依据LSTM网络提供的网络状态数据生成动作,并更新内部网络参数。具体来看,目标策略网络将参数传递给目标 Q 网络用于函数评估,在线 Q 网络将参数传递给在线策略网络,用于该网络的梯度计算。R-DRL算法训练过程如算法1所示。


仿真评估:
- 实验方案
本文实验利用 Mininet 网络仿真平台来搭建虚拟 SDN,并采用开源 Ryu 控制器作为整个网络的控制器。采用 Iperf 流生成工具模拟真实网络流量,R-DRL 算法基于Keras+TensorFlow框架实现,算法和Mininet 运行在一台服务器上,服务器具体配置如下图所示:

实验中,SDN 的拓扑为认可度较高的 GEANT网络,该网络中包含22个网络节点和36条链路,每条链路的传输能力各不相同。网络数据采用由UPC大学提供的基于 GEANT 拓扑收集的数据集,取85%作训练集,15%作测试集。任意节点对之间的路由路径由生成树方法[20]生成,每个节点对之间采用4条备选转发路径。
- 对比方案
DDPG:DDPG 方案中不采用 LSTM 层,其余神经网络参数设置与本文所提R-DRL算法一致,用来验证LSTM层对DDPG算法改进效果
OSPF:OSPF 即开路最短路径优先,依据该规则,网络会把数据流转发在长度最短的路径上,由于没有考虑链路的传输能力,个别链路容易陷入拥塞。
MCFCSP:多物网络流流约束最短路径方案将链路的传输能力作为约束条件,在保证网络不出现拥塞的条件下传输数据流。
KSP:k 路最短路径方案会在两节点对间选择前 k 条最短的路径作为路由路径对数据流完成转发操作,本次实验中取 k=4。
- 实验结果
图3给出了展示了训练过程中不同LSTM网络层数对R-DRL算法奖赏值相对变化的影响,通过对比可知,使用LSTM可以明显提高算法的奖赏值,但不同LSTM层数对值的变化无明显影响。。图4是不同 LSTM层数的R-DRL算法的运行时间对比。当LSTM 网络层数增加时,R-DRL算法的所需的运行时间明显增加。结合图3,为保证 R-DRL算法的性能,以下实验取LSTM层数为1。
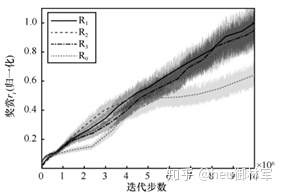
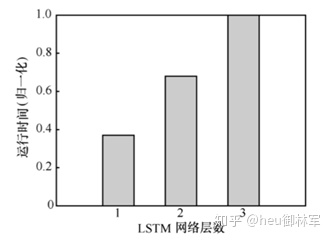
图5展示了在软件定义网络 QoS 优化场景中不同数据流调度算法在时延方面的性能对比,R-DRL 算法可以满足在流请求速率增长时网络的低时延需求,而且在时延方面的优化效果优于其他算法。DDPG 算法缺少LSTM网络层,对网络状态表现出的时间相关性无法有效感知,因此DDPG算法生成的优化策略不能准确反映网络的具体状态,陷入次优解;KSP算法将数据流转发至较短的前k 条路径上,因此这 k 条路径可能共用一条至多条较短的路径,由于传输能力限制,因此出现拥塞导致时延增加;MCFCSP、OSPF 算法和 KSP 情况一致,容易出现链路瓶颈问题。
图6展示了在软件定义网络QoS优化场景中不同数据流调度算法在链路负载均衡方面的性能对比。从图 6中可以看出,OSPF、MCFCSP 和 KSP算法中衡量链路负载均衡程度的参数σ逐渐增大,相对于R-DRL和DDPG链路负载更不均衡,还可以注意到应用R-DRL算法的链路负载均衡程度总体要优于DDPG算法约22.7%。
图7展示了不同数据流调度算法在分组丢失率方面的性能对比。从图7中可以看出,MCFCSP以降低链路传输能力为代价保证各路径上的数据流不出现拥塞,分组丢失率最低,但R-DRL算法取得了接近于MCFCSP的性能。
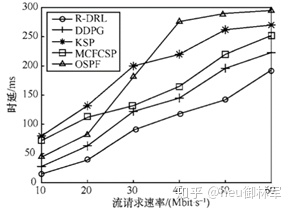
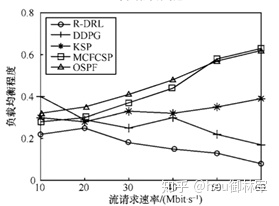
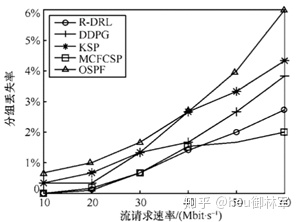
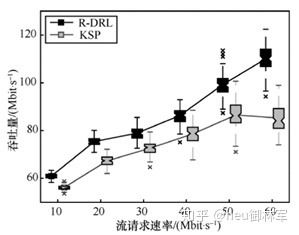
图8联合采用箱线图和折线图展示了路由算法 R-DRL 和 KSP 对网络吞吐率的影响程度。其中折线图的连接点表示不同流请求速率条件下吞吐量数据的平均值,箱线图表示吞吐量数据的分布情况,箱线图的上下短横线表示箱线图上下限,叉号表示异常值。从图中可以看到,相对于KSP算法,R-DRL 将网络吞吐率提高了约8.2%,这是因为生成树算法在生成路由路径时尽量减少各路径共用一条链路的情况出现,避免了瓶颈链路的产生,提高了网络的传输能力。
结论:
软件定义网络的QoS优化问题本质上是NP完全问题,为了实现 QoS 的自动化优化,国内外相关研究人员已经进行了深入研究,然而当前主流的启发式解决方案存在算法参数与场景绑定,应用场景受限问题,而在尝试应用深度强化学习的方案中,仍然采用KSP算法生成路由路径,难免出现链路瓶颈问题。基于此,本文借助长短期记忆网络和 DDPG 提出了用于软件定义网络 QoS 优化的R-DRL算法,通过将网络资源和状态信息统一到网络模型中,借助深层神经网络生成满足QoS 优化的目标的动态流量调度策略。在网络拓扑GEANT 上的仿真实验说明,结合长短期记忆网络设计的R-DRL算法提升了深度强化学习算法的 流量感知能力,表现出比原有算法更好的性能。与其他算法相比,R-DRL 保证了传输时延和分组丢失率,提高了约 22.7%的网络的负载均衡程度和约8.2%网络吞吐率,对解决SDN中的QoS优化问题有一定实用价值
个人总结与思考
- 文章应用LSTM+DDPG算法对软件定义网络的路由问题进行了研究,由于网络中存在多条路径,而不同的节点之间的拥堵情况不同,因此,如何对节点直接流量进行分流来减少延迟、提高链路利用率,是一个值得研究的问题。而对于无线自组网来说,不同通信节点由于位置、环境等因素也会导致信道的传输质量存在差异,那么也可以应用本文的方法,来对信息传输路径进行优化。
- 文章对于所研究的问题的整体解决架构表述非常清楚,分为数据层面、控制层面、应用层面,很好的展现了场景与算法之间的关系。
- 在仿真实验中,对于前面仿真中已经得出的结论,要注意应用在后面的仿真中,比如前面的仿真得到了某一组比较好的参数,那么后续就要使用这组参数继续进行仿真,这样才合理。
参考文献
















 3671
3671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









