







上篇主要介绍了概率图模型,首先从生成式模型与判别式模型的定义出发,引出了概率图模型的基本概念,即利用图结构来表达变量之间的依赖关系;接着分别介绍了隐马尔可夫模型、马尔可夫随机场、条件随机场、精确推断方法以及LDA话题模型:HMM主要围绕着评估/解码/学习这三个实际问题展开论述;MRF基于团和势函数的概念来定义联合概率分布;CRF引入两种特征函数对状态序列进行评价打分;变量消去与信念传播在给定联合概率分布后计算特定变量的边际分布;LDA话题模型则试图去推断给定文档所蕴含的话题分布。本篇将介绍最后一种学习算法–强化学习。
16、强化学习
强化学习(Reinforcement Learning,简称RL)是机器学习的一个重要分支,前段时间人机大战的主角AlphaGo正是以强化学习为核心技术。在强化学习中,包含两种基本的元素:状态与动作,在某个状态下执行某种动作,这便是一种策略,学习器要做的就是通过不断地探索学习,从而获得一个好的策略。例如:在围棋中,一种落棋的局面就是一种状态,若能知道每种局面下的最优落子动作,那就攻无不克/百战不殆了~
若将状态看作为属性,动作看作为标记,易知:监督学习和强化学习都是在试图寻找一个映射,从已知属性/状态推断出标记/动作,这样强化学习中的策略相当于监督学习中的分类/回归器。但在实际问题中,强化学习并没有监督学习那样的标记信息,通常都是在尝试动作后才能获得结果,因此强化学习是通过反馈的结果信息不断调整之前的策略,从而算法能够学习到:在什么样的状态下选择什么样的动作可以获得最好的结果。
16.1 基本要素
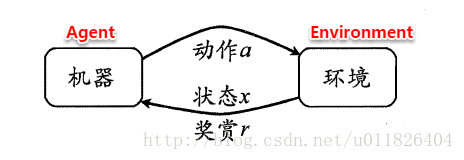
强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体而言:机器处在一个环境中,每个状态为机器对当前环境的感知;机器只能通过动作来影响环境,当机器执行一个动作后,会使得环境按某种概率转移到另一个状态;同时,环境会根据潜在的奖赏函数反馈给机器一个奖赏。综合而言,强化学习主要包含四个要素:状态、动作、转移概率以及奖赏函数。
状态(X):机器对环境的感知,所有可能的状态称为状态空间;
动作(A):机器所采取的动作,所有能采取的动作构成动作空间;
转移概率(P):当执行某个动作后,当前状态会以某种概率转移到另一个状态;
奖赏函数(R):在状态转移的同时,环境给反馈给机器一个奖赏。
因此,强化学习的主要任务就是通过在环境中不断地尝试,根据尝试获得的反馈信息调整策略,最终生成一个较好的策略π,机器根据这个策略便能知道在什么状态下应该执行什么动作。常见的策略表示方法有以下两种:
确定性策略:π(x)=a,即在状态x下执行a动作;
随机性策略:P=π(x,a),即在状态x下执行a动作的概率。
一个策略的优劣取决于长期执行这一策略后的累积奖赏,换句话说:可以使用累积奖赏来评估策略的好坏,最优策略则表示在初
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2287
2287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









