







本次是采用python清洗数据,然后导入oracle,最后使用tableau进行展示
一 导入相关包
1.本次数据集是kaggle的Titanic
import pandas as pd
from sqlalchemy import create_engine
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor2.导入后查看相关信息
df=pd.read_csv('train.csv')
df[:3]
-------------------------------------------------------------------------------------------------------------------------
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S2.1统计描述信息
df.info()
print('-'*50)
df.describe()
----------------------------------------------------------
-----------------------------------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
--------------------------------------------------
PassengerId Survived Pclass Age SibSp Parch Fare
count 891.000000 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208
std 257.353842 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429
min 1.000000 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000 0.000000 7.910400
50% 446.000000 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200
75% 668.500000 1.000000 3.000000 38.000000 1.000000 0.000000 31.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200二 处理数据
我们发现age,cabin,embarked三列有空值.
1.对于缺失值我们可以采取方法:
(1) 填充
(2) 删除
如果数据集很多,且缺失值很少,我们可以直接考虑删除.这里我们采用填充.
1.1 Embarked缺失两,且由于值的属性为上船地点,且地点总共才三个,我们用众数填充
df.Embarked[df.Embarked.isnull()]=df.Embarked[df.Embarked.notnull()].mode().values1.2 Cabin缺失值很多,由于值属性为船舱,那么是不是缺失代表本身就没有船舱, 我们可以考虑赋值一个新的值给它,比如'Nocabin'
df['Cabin']=df['Cabin'].fillna('Nocabin')1.3 剩下的是年龄,年龄在我们的猜测中是属于比较重要的属性.
我们采取机器学习的方式来预测下,其中采用随机森林回归
由于sklearn只能识别数值特征,我们需要将sex转换为数字,(sex特征对于年龄的猜测比较重要)我们对年龄采取one-hot编码
onehot_sex=pd.get_dummies(df['Sex'],prefix='Sex')在将两个表合并,可以看到后面已经有我们合并的表了
df=df.join(onehot_sex)
df.head(3)
--------------------------------------
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Sex_female Sex_male
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 Nocabin S 0 1
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C 1 0
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 Nocabin S 1 02 接下来对年龄进行随机森林回归预测
#提取相关数值特征好做预测
age_feauture=df[['Age','Survived','Survived','Pclass','SibSp','Parch','Fare','Sex_female','Sex_male']]
#以age是否为空区分开数据
age_null=age_feauture[age_feauture['Age'].isnull()]
age_notnull=age_feauture[age_feauture['Age'].notnull()]将age非空的值进行模型训练
x=age_notnull.values[:,1:] #剔除age列
y=age_notnull.values[:,0] #只包含age列
rfr=RandomForestRegressor(n_estimators=1000, n_jobs=-1) #实例化模型
rfr.fit(x,y) #训练模型
predict_age=rfr.predict(age_null.values[:,1:]) #预测数据
df.Age[df['Age'].isnull()]=predict_age #将预测年龄赋值再次查看数据信息
df.info()
print('-'*50)
df.describe()
-------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 14 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 891 non-null object
Embarked 891 non-null object
Sex_female 891 non-null uint8
Sex_male 891 non-null uint8
dtypes: float64(2), int64(5), object(5), uint8(2)
memory usage: 85.3+ KB
--------------------------------------------------
PassengerId Survived Pclass Age SibSp Parch Fare Sex_female Sex_male
count 891.000000 891.000000 891.000000 891.000000 891.000000 891.000000 891.000000 891.000000 891.000000
mean 446.000000 0.383838 2.308642 29.645483 0.523008 0.381594 32.204208 0.352413 0.647587
std 257.353842 0.486592 0.836071 13.784712 1.102743 0.806057 49.693429 0.477990 0.477990
min 1.000000 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000 0.000000 0.000000
25% 223.500000 0.000000 2.000000 21.000000 0.000000 0.000000 7.910400 0.000000 0.000000
50% 446.000000 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200 0.000000 1.000000
75% 668.500000 1.000000 3.000000 37.000000 1.000000 0.000000 31.000000 1.000000 1.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200 1.000000 1.000000目前数据清洗完毕,我们开始第三步,导入到数据库
三 导入数据库
1.这里用的oracle数据库调用的是sqlalchemy.create_engine
engine=create_engine("oracle://username:password@IP/db")
#创建链接
#oracle 由于我使用的oracle,这里采用oracle,如果是mysaql就写mysql
#username 账户名
#password 密码
#IP就是你库的IP本地就是localhost
#db就是库名,比如我的就是ORCL这里在网上找到各数据类型转换,在python的类型转到oracle会因为类型不同报错
from sqlalchemy.dialects.oracle import
BFILE, BLOB, CHAR, CLOB, DATE,
DOUBLE_PRECISION, FLOAT, INTERVAL, LONG, NCLOB,
NUMBER, NVARCHAR, NVARCHAR2, RAW, TIMESTAMP, VARCHAR,
VARCHAR2
#定义函数,自动输出DataFrme数据写入oracle的数类型字典表,配合to_sql方法使用
def mapping_df_types(df):
dtypedict = {}
for i, j in zip(df.columns, df.dtypes):
if "object" in str(j):
dtypedict.update({i: VARCHAR(256)}) #将obeject类型转为varchar
if "float" in str(j):
dtypedict.update({i: NUMBER(19,8)})
if "int" in str(j):
dtypedict.update({i: VARCHAR(19)})
if "datetime" in str(j):
dtypedict.update({i: DATE}) #将datetime转为date
return dtypedict
#转换后也要注意与oracle列的数据类型是否一致,
#比如这里datetime,但是oracle创建的相关列是varchar,显示还是会不同#我们将df的类型转换下
dtypedict=mapping_df_types(df)
#然后使用to_sql写入数据库
df.to_sql('tiantic',engine,index=False,if_exists='append',dtype=dtypedict,chunksize=100)
#数据的写入我们采用pd的to_sql
#tiantic为表名,如果不存在则创建
#engine为我们上面创建的链接
#index=false代表是否将df的index写进去,由于df的index都是一串数字,所以选false
#if_exists='append'代表为加入
#dtype=dtypedict就是指定类型为我们上面定义的函数
#chunksize=100类似循环,一次写入100条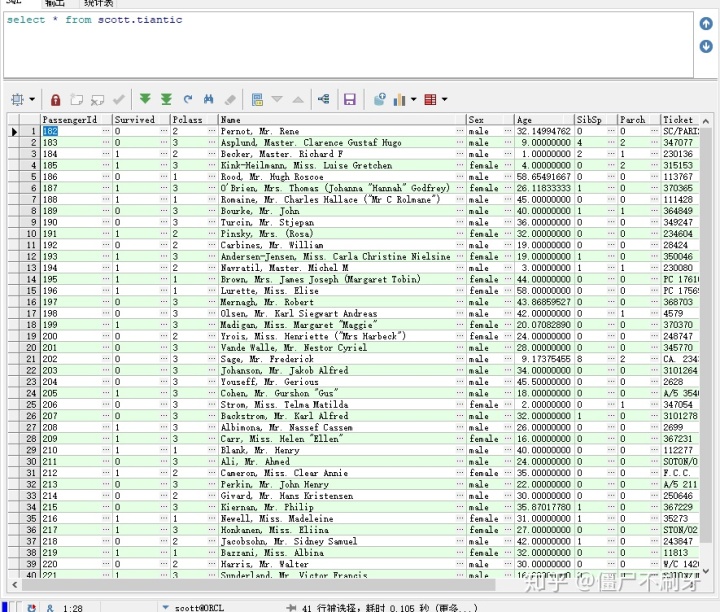
然后写入的过程就完成了,接下来就用sql进行操作了
四 sql部分
1.我们用sql查看下sex(男女)的生存率
select
tt.sex,
count(case when tt.survived=1 then 1 else null end)/count(tt.survived) 存活率,
count(case when tt.survived=0 then 1 else null end)/count(tt.survived) 死亡率
from TIANTIC tt
group by tt.sex
----------------------------------------------------------------
SEX 存活率 死亡率
male 0.188908145580589 0.811091854419411
female 0.74203821656051 0.25796178343949嗯 ,果然还是绅士风度,女士优先啊
2.我们在看下pclass(船票等级)
select
tt.pclass,
count(case when tt.survived=1 then 1 else null end)/count(tt.survived) 存活率,
count(case when tt.survived=0 then 1 else null end)/count(tt.survived) 死亡率
from TIANTIC tt
group by tt.pclass
order by tt.pclass
-----------------------------------------------------------------------------
PCLASS 存活率 死亡率
1 0.62962962962963 0.37037037037037
2 0.472826086956522 0.527173913043478
3 0.242362525458248 0.757637474541752高等级船票的果然存活比较容易
3.我们在看下age(年龄)
select
case when tt.age<=12 then '儿童'
when 12<tt.age and tt.age<=18 then '少年'
when 18<tt.age and tt.age <=25 then '青年'
when 25<tt.age and tt.age <=40 then '壮年'
when 40<tt.age and tt.age <=55 then '中年'
else '老年' end 人生阶段,
count(case when tt.survived=1 then 1 else null end)/count(tt.survived) 存活率,
count(case when tt.survived=0 then 1 else null end)/count(tt.survived) 死亡率
from tiantic tt
group by
case when tt.age<=12 then '儿童'
when 12<tt.age and tt.age<=18 then '少年'
when 18<tt.age and tt.age <=25 then '青年'
when 25<tt.age and tt.age <=40 then '壮年'
when 40<tt.age and tt.age <=55 then '中年'
else '老年' end
order by 存活率 desc
------------------------------------------------------------------------------------
人生阶段 存活率 死亡率
儿童 0.525641025641026 0.474358974358974
少年 0.4625 0.5375
中年 0.37007874015748 0.62992125984252
壮年 0.365853658536585 0.634146341463415
青年 0.364583333333333 0.635416666666667
老年 0.266666666666667 0.733333333333333
老人的存活率低猜测是因为人老了不方便了,年轻人存活还是比较高的
接下来我们用tableau进行数据展示,毕竟图比数据好看
五 tableau部分
1.我们打开tableau,找到oracle.

2.登录oracle
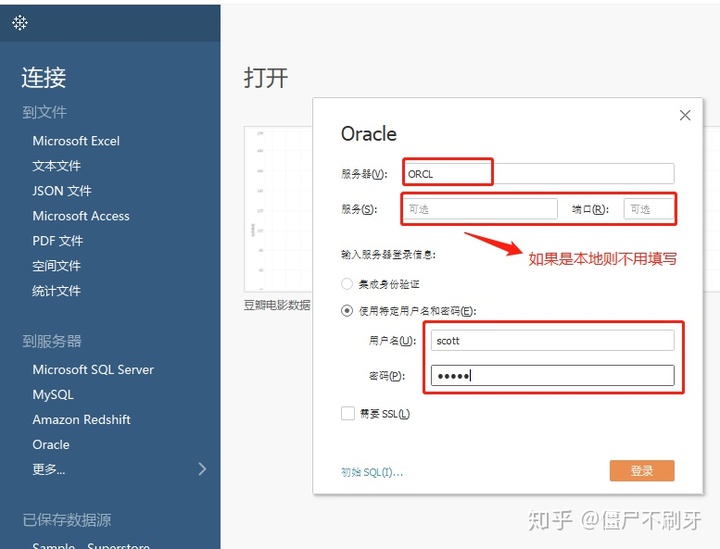
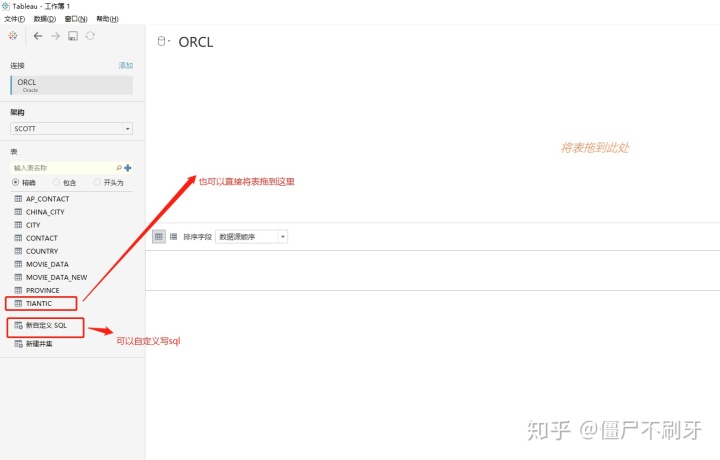
3.然后我们就可以在tableau里打开oracle数据库,可以自定义查询,也可以使用sql语句
4.这里我们只筛选了部分数据出来,所以用自定义查询
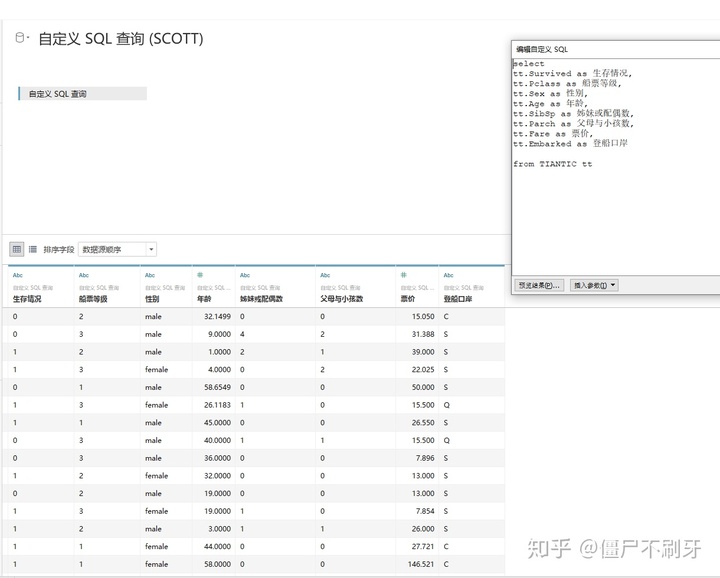
5.这里不用计算是因为我们在tableau上还是可以进行部分计算的,语法类似sql.
6.我们创建一些维度和度量
7.右键创建计算字段
8.创建字段和度量
8.1 生存情况:由于生存情况是数值型,我们将其转换为[生.死]
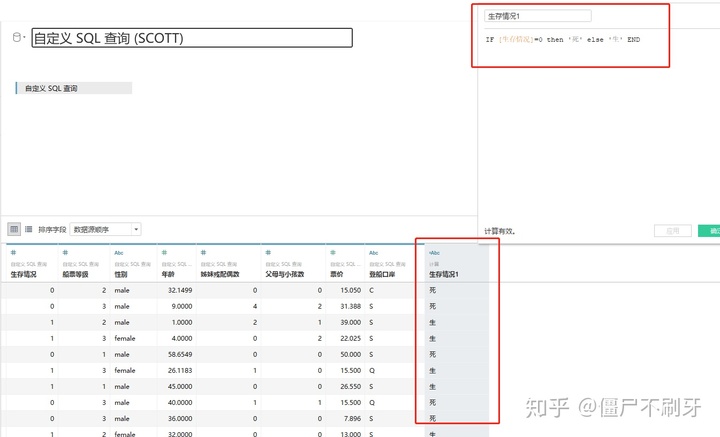
语法是不是与case when很类似
8.2 船票等级 我们觉得123不好看也不好听,我们改成头等舱,商务舱,经济舱

8.3 年龄 我们还是按照之前sql的进行划分
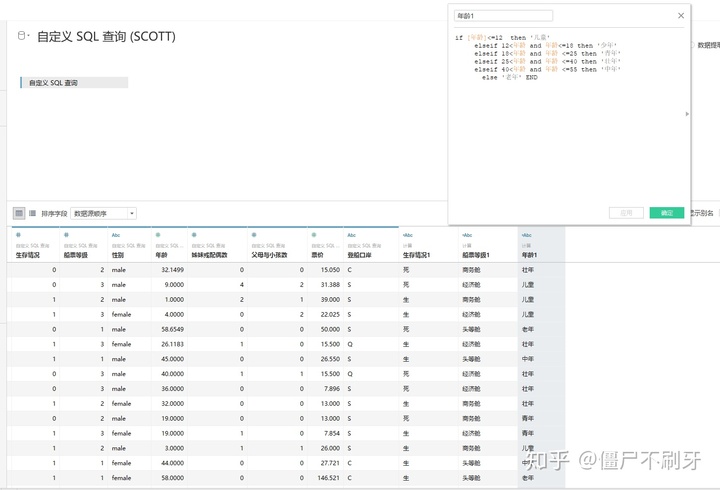
8.4 由于票价和船票等级与年龄相关,我们这里就不需要划分了,然后在划分一个人口数量,用于计数就可以了
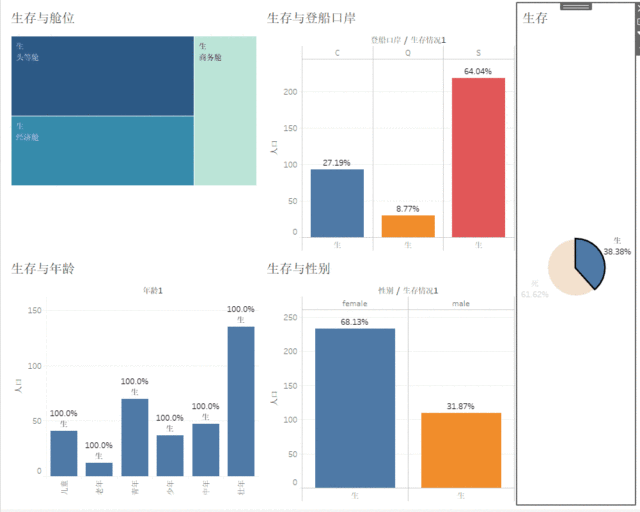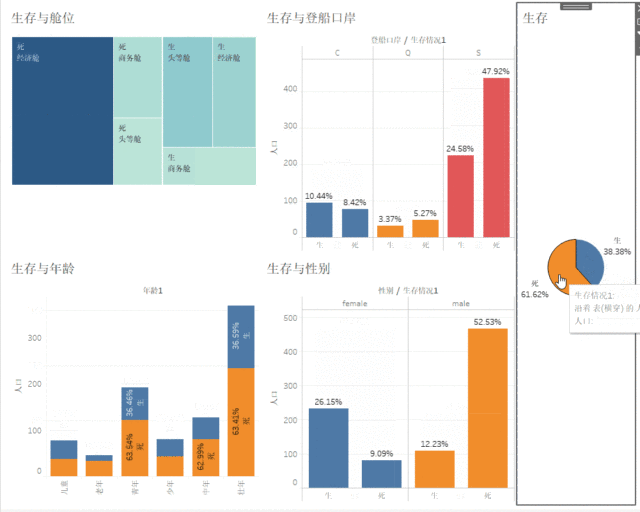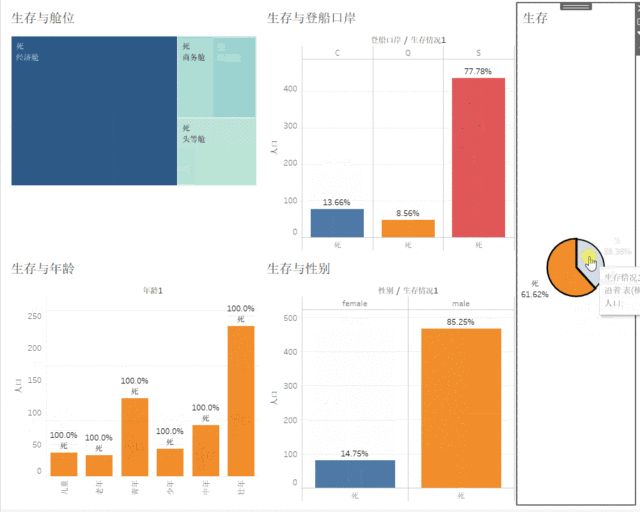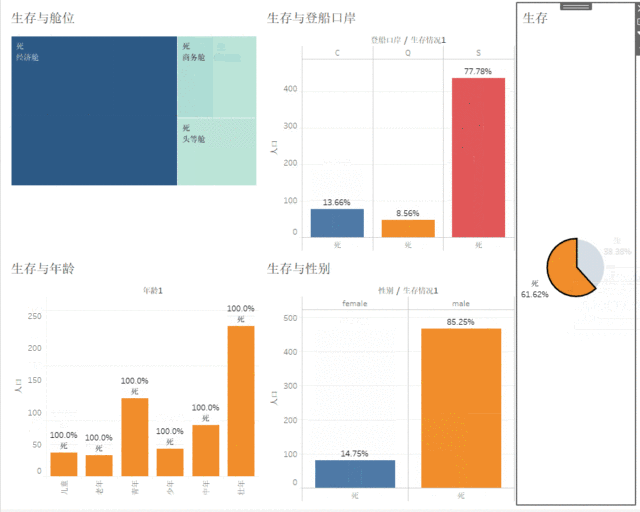
9. 我们画个饼图来看看生存率
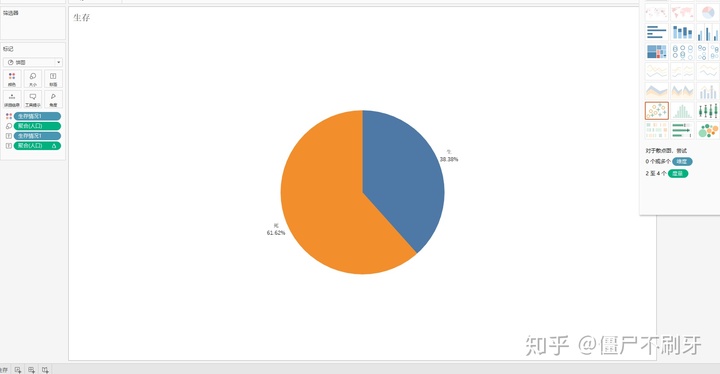
38%多点生存,好可怕
9.1 我们在画图看看生存和性别的比例
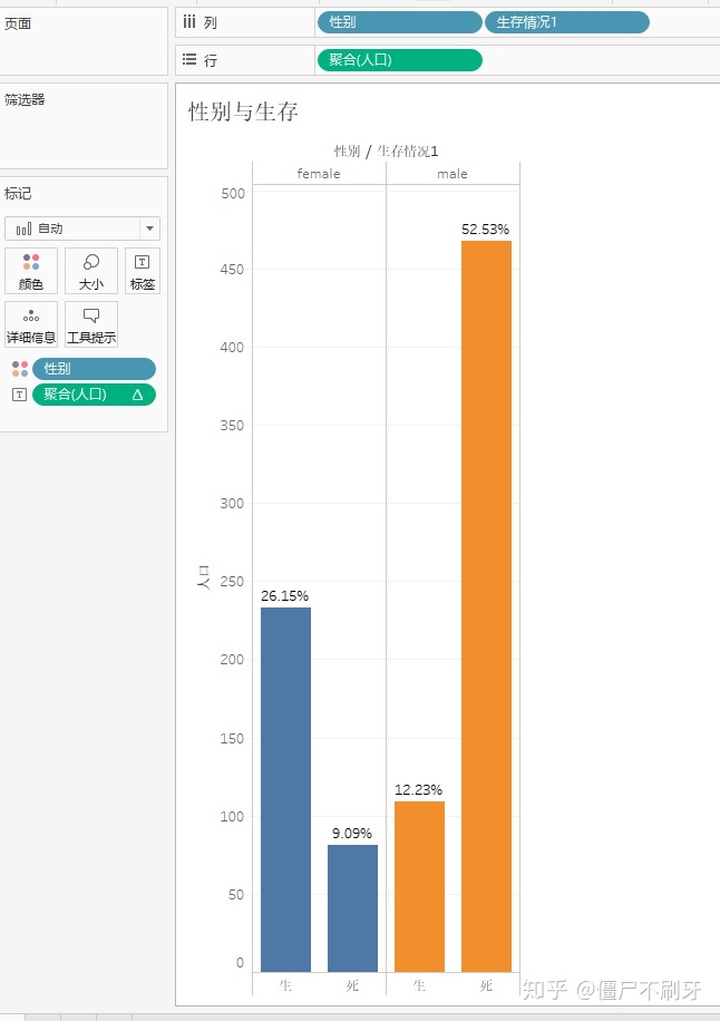
女性的生存率高出男性两倍,死亡率比男性低40%多
9.2 我们在看下生存与年龄的关系
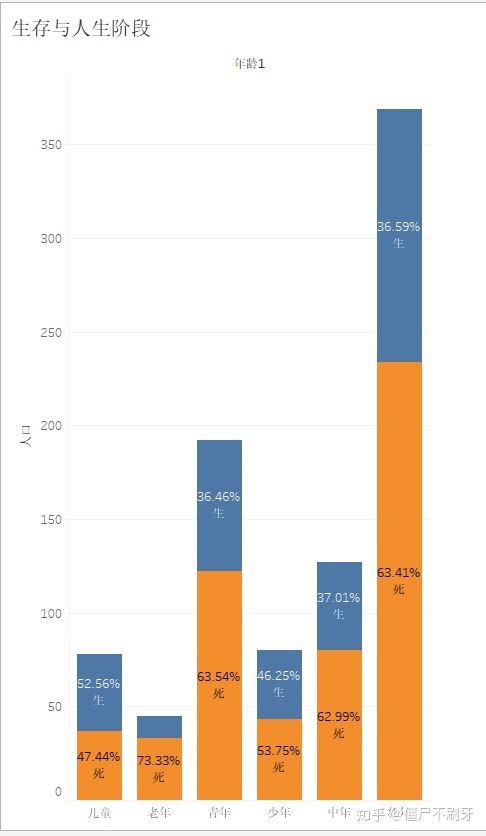
生存率最高的儿童和少年,而老年的死亡率最高,在根据前面的女性生存率高,绅士风度十足,至于老人比较低,可能真的是体力问题吧
9.3 生存与仓位的关系
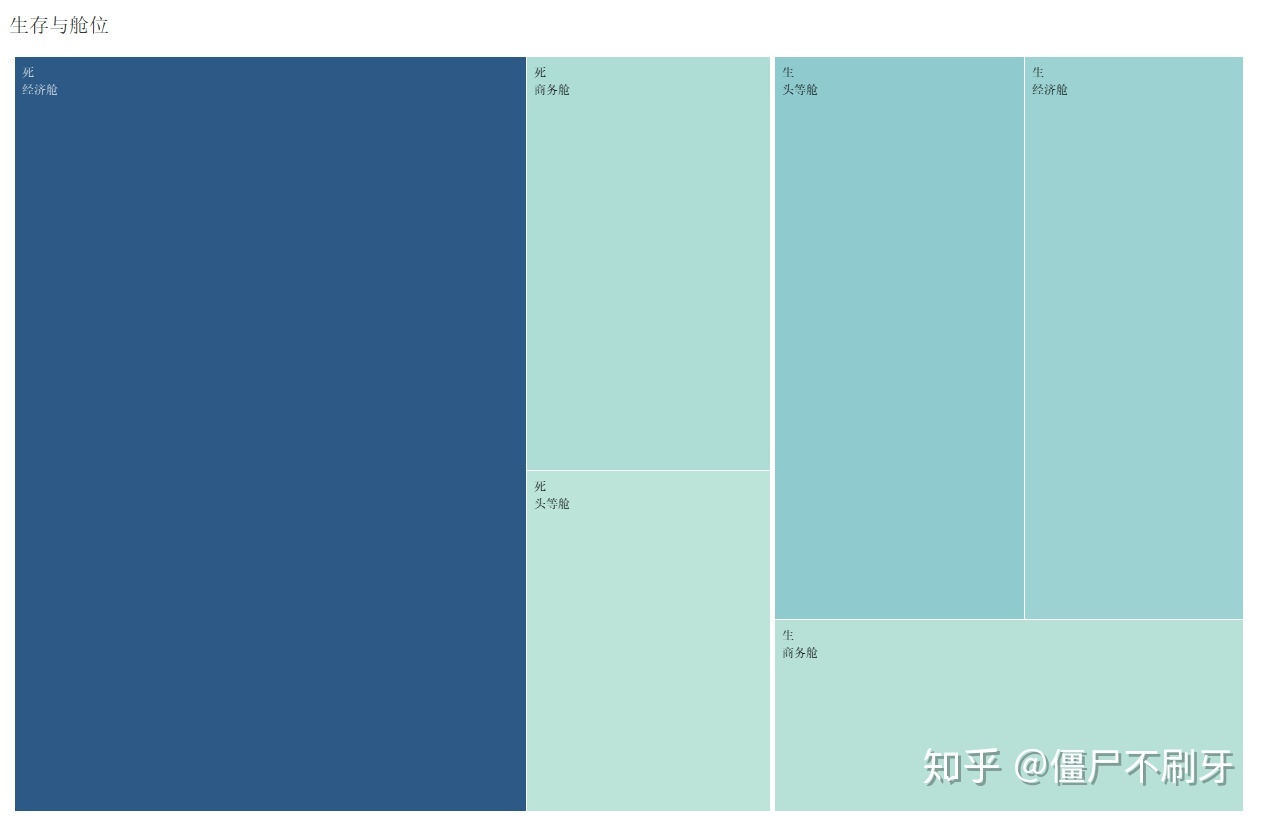
头等舱的生存率果然还是要高的
9.4 生存与家人数量
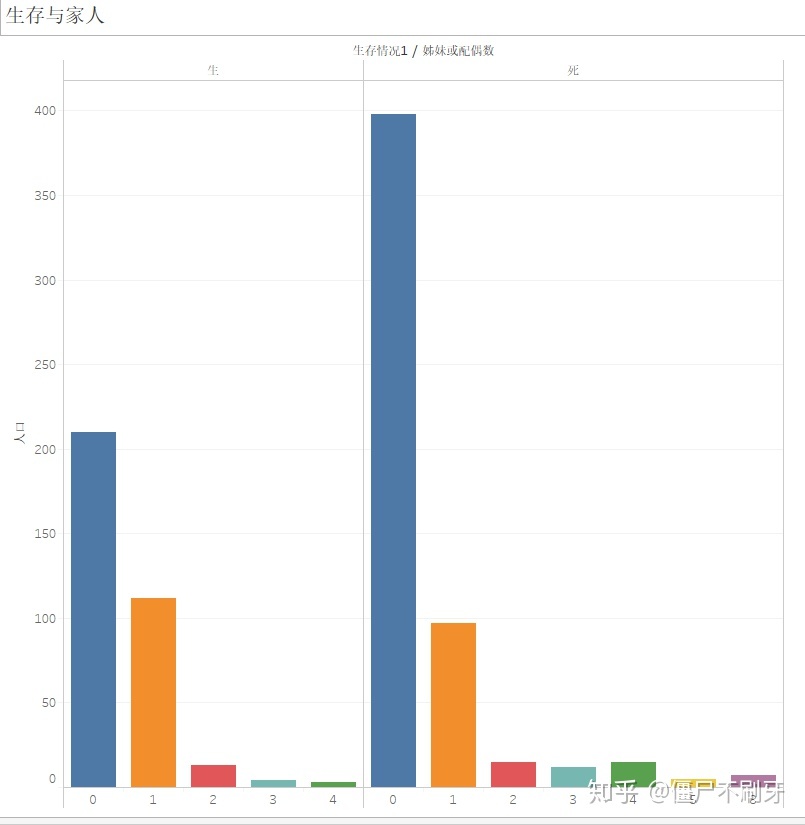
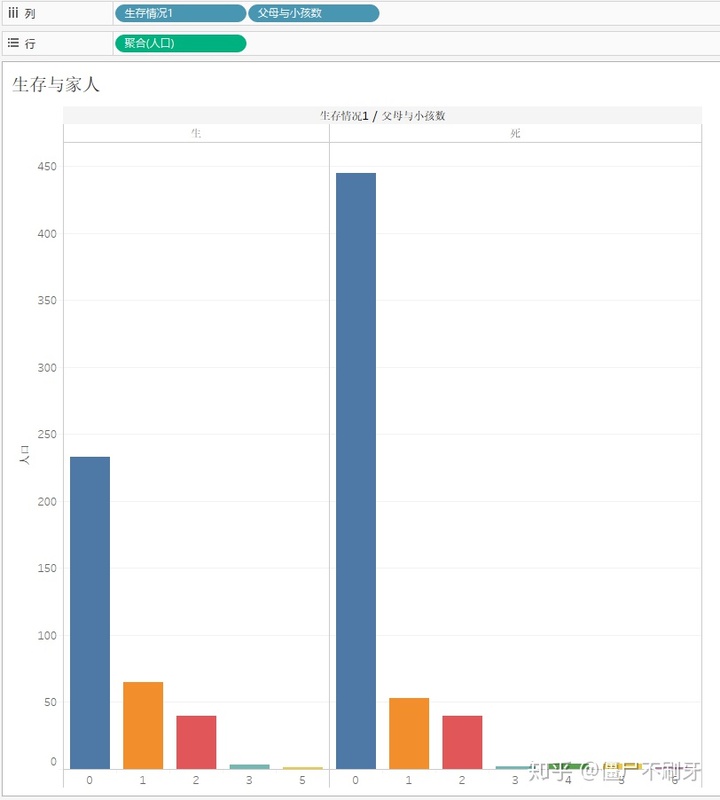
似乎闻到了单身狗的狂吠.....(⊙﹏⊙)
9.5 生存与登船口岸
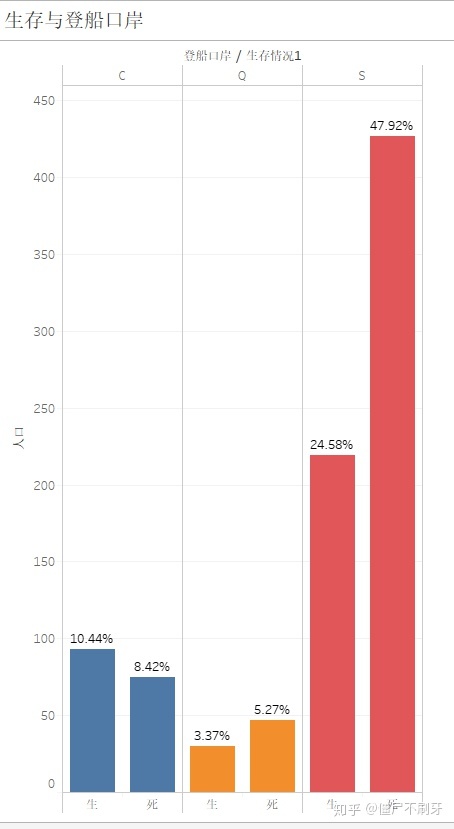
似乎C口登船的人存活率高点
最后完成仪表盘,将生与死作为筛选器联动仪表盘
最后附上tableau地址:
Tableau Publicpublic.tableau.com














 846
846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









