







目录
1.pclass与survived的关系
xy[['Survived','Pclass']].groupby(['Pclass']).mean().plot.bar()
plt.show()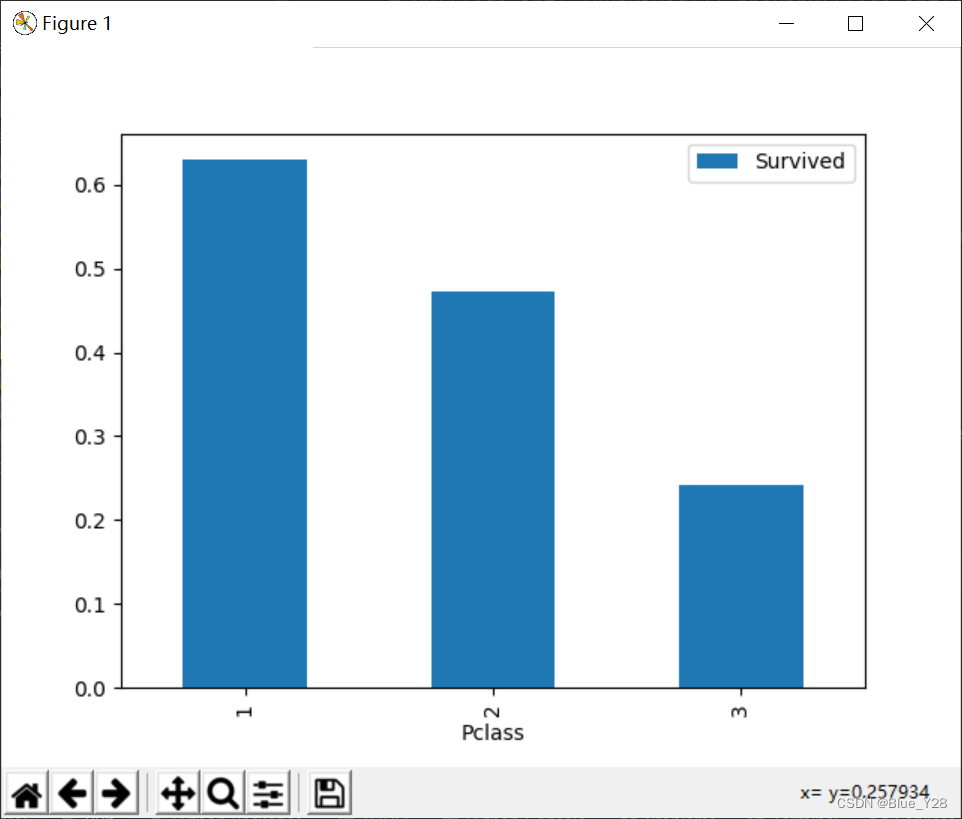
2.sex与survived的关系
xy[['Sex','Survived']].groupby(['Sex']).mean().plot.bar()
plt.show()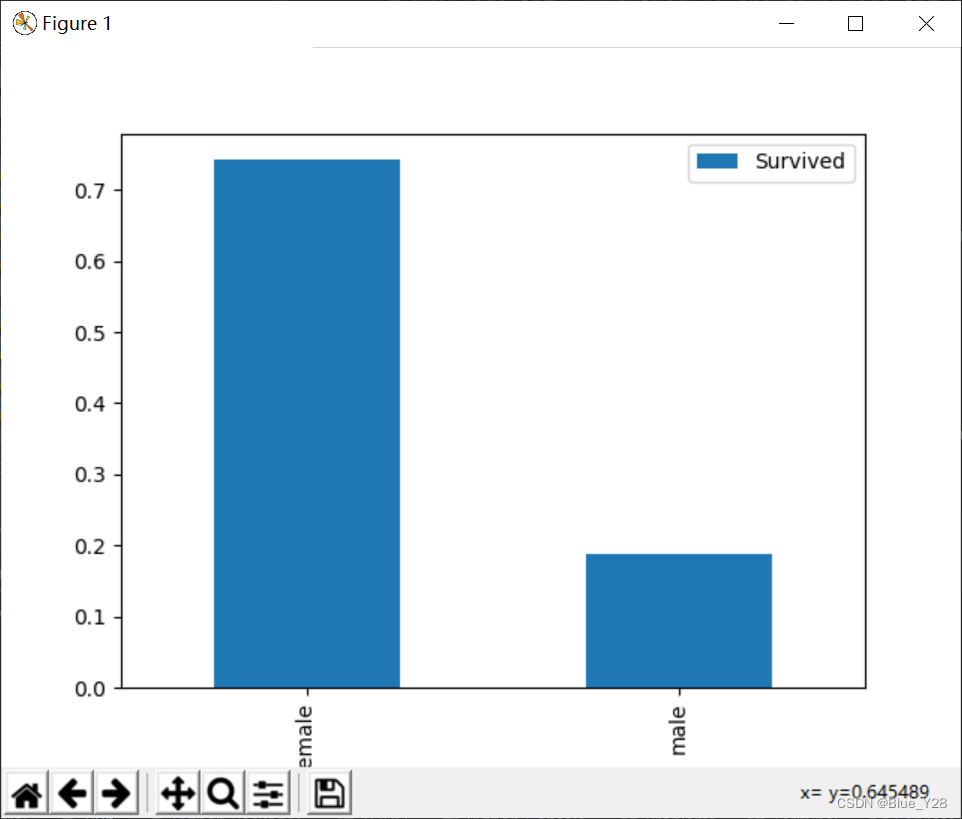
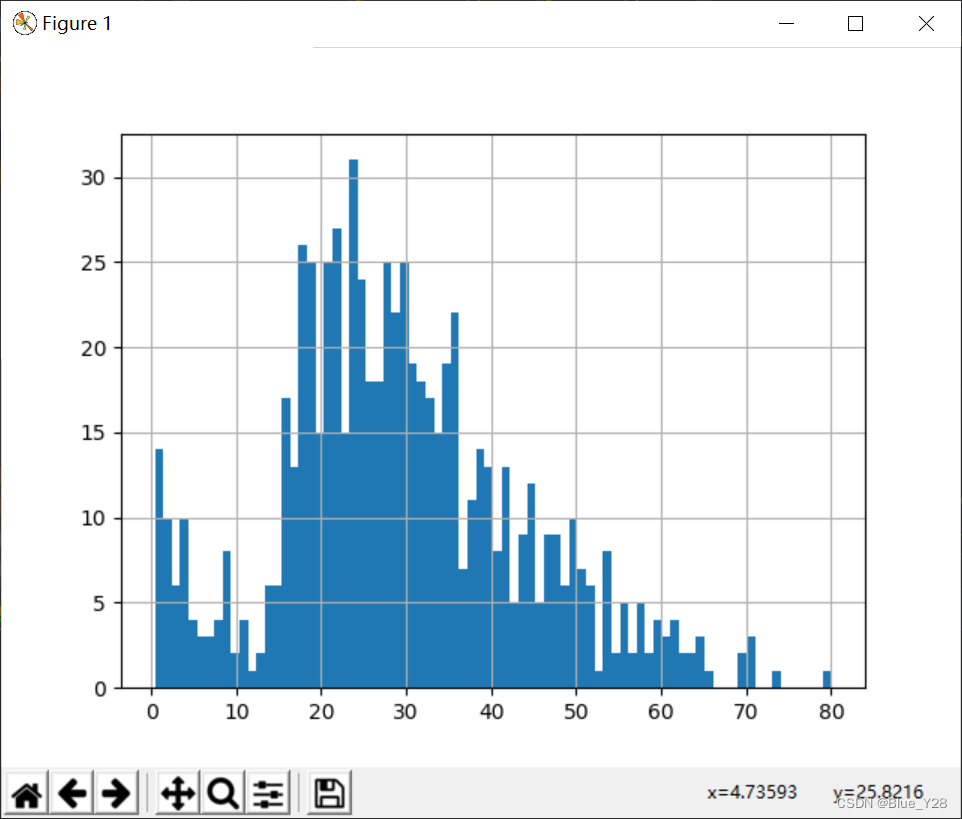
3.age与survived的关系
先看看age的分布
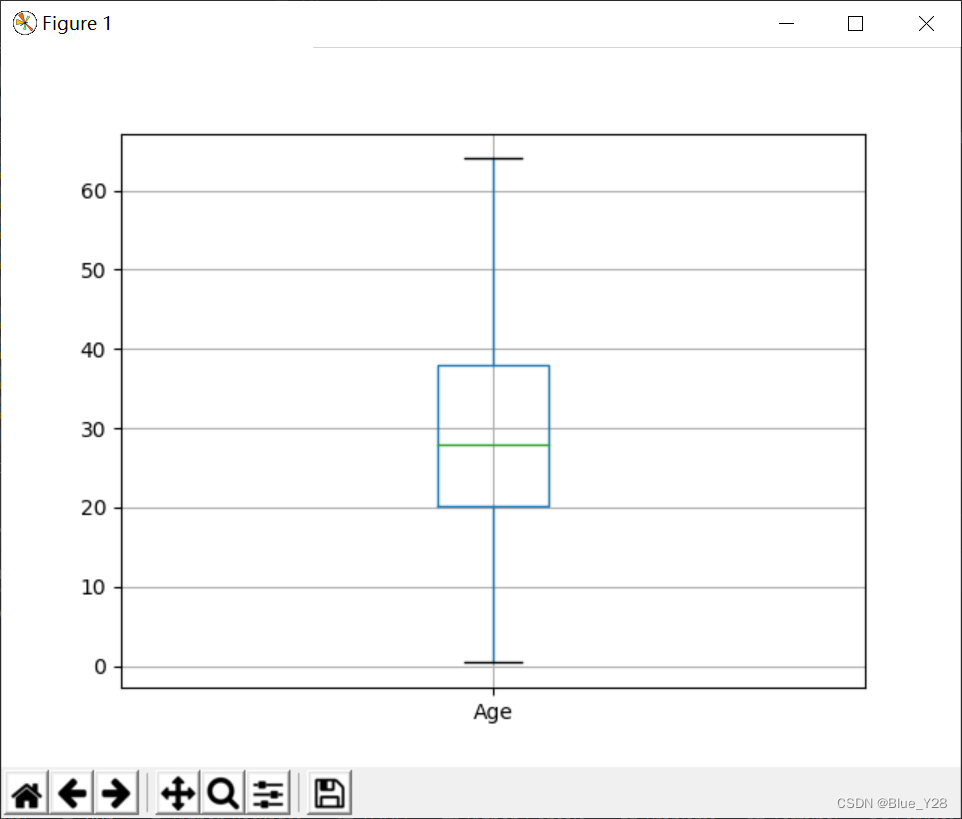
通过这个箱型图可以发现,中位线在28岁左右,下四分位线20岁,上四分位线38岁;每个部分分别包含了25%的数据

4.sibsp与survived的关系
xy[['SibSp','Survived']].groupby(['SibSp']).mean().plot.bar()
plt.show()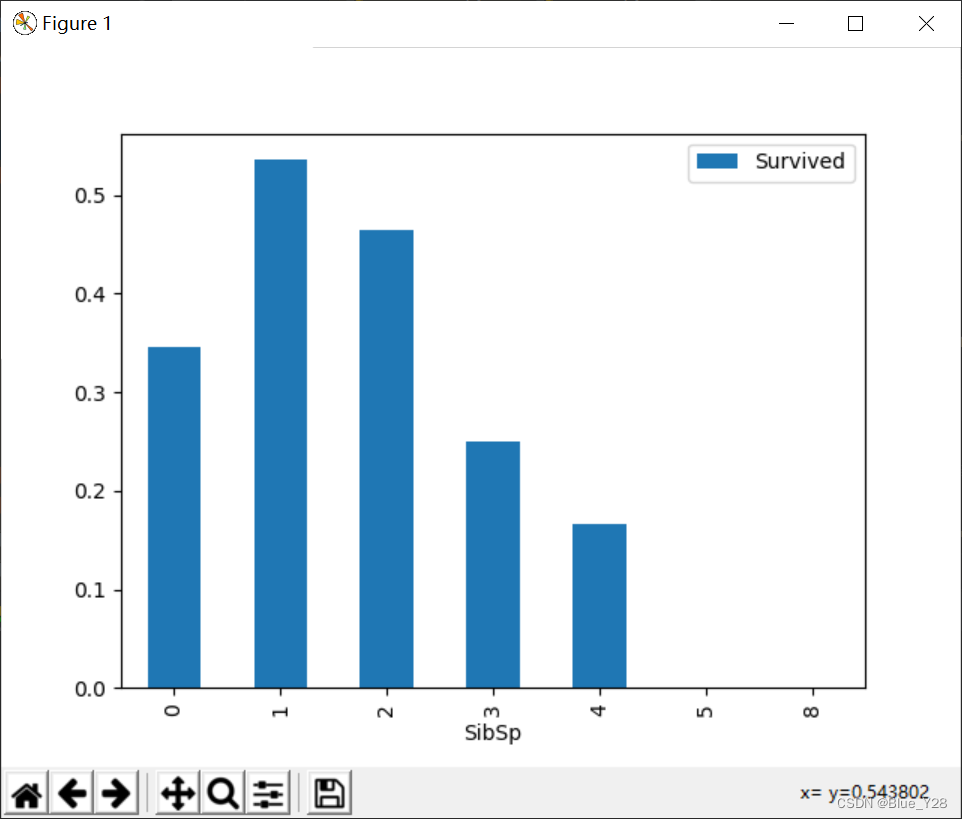
5.Parch与survived的关系

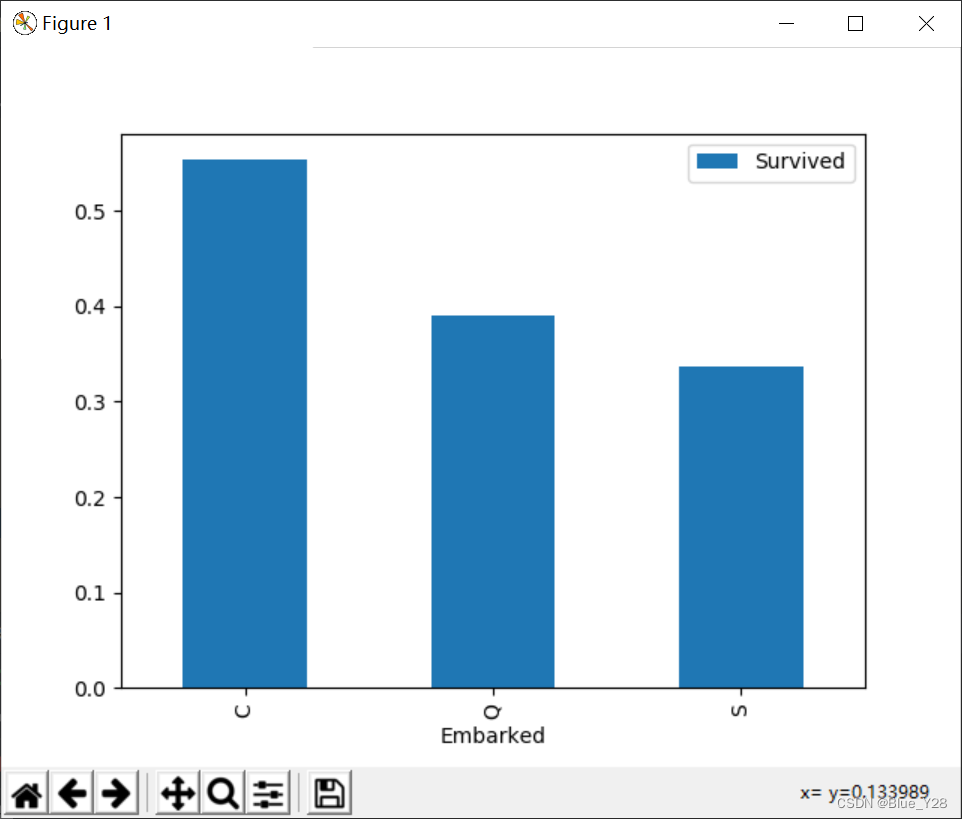
6.Embarked与survived的关系
sns.countplot('Embarked',hue='Survived',data=xy)
plt.title('Embarked and Survived')
plt.show()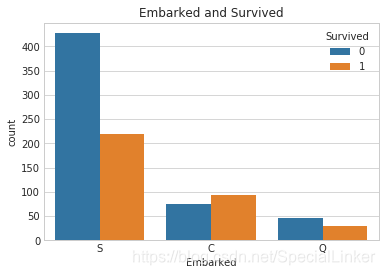
结论
| 变量 | 定义 | key | 结论:是否选做特征值 |
| survival | Survival | 0 = No, 1 = Yes | |
| pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd | 高级的船舱的生存几率高 |
| sex | Sex | 女性生存几率高 | |
| Age | Age in years | 青壮年的生存几率高 | |
| sibsp | # of siblings / spouses aboard the Titanic | 配偶或亲戚个数少的生存几率高 | |
| parch | # of parents / children aboard the Titanic | 同行的父母子女人数少的生存几率高 | |
| ticket | Ticket number | 不做特征 | |
| fare | Passenger fare | 票价与船舱等级相匹配,因而选择船舱等级作为特征值 | |
| cabin | Cabin number | 由于缺失值太多,不选做特征值 | |
| embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown, S = Southampton | 不同的上船地点生存几率相差不多 |
特征处理
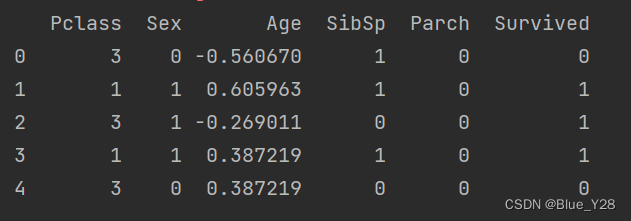
在选出pclass、sex、age、sibsp、parch做特征后,将这些属性做处理。
#变量转换
train_data = xy[['Pclass','Sex','Age','SibSp','Parch','Survived']]
train_data.loc[train_data['Sex'] == 'male', 'Sex'] = 0
train_data.loc[train_data['Sex'] == 'female', 'Sex'] = 1
X_age = np.array(train_data['Age']).reshape(-1,1)#直接变成一列
train_data['Age'] = StandardScaler().fit_transform(X_age)
print(train_data.head())结果显示


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









