






本文是【统计师的Python日记】第13天的日记
回顾一下:
- 第1天学习了Python的基本页面、操作,以及几种主要的容器类型。
- 第2天学习了python的函数、循环和条件、类。
- 第3天了解了Numpy这个工具库。
- 第4、5两天掌握了Pandas这个库的基本用法。
- 第6天学习了数据的合并堆叠。
- 第7天开始学习数据清洗,着手学会了重复值删除、异常值处理、替换、创建哑变量等技能。
- 第8天接着学习数据清洗,一些常见的数据处理技巧,如分列、去除空白等被我一一攻破。
- 第9天学习了正则表达式处理文本数据。
- 第10天学习了数据的聚合操作、数据透视表pivot_table()方法、交叉表crosstab。
- 第11天学习了class类的概念以及如何写一个类。
- 第12天学习了机器学习库 sklearn,并用这个工具完整建了一个模型。
原文复习(点击查看):
第1天:谁来给我讲讲Python?
第2天:再接着介绍一下Python呗
第3天:Numpy你好
第4天:欢迎光临Pandas
第四天的补充
第5天:Pandas,露两手
第6天:数据合并
第7天:数据清洗(1)
第8天:数据清洗(2)文本处理
第9天:正则表达式
第10天:数据聚合
第11天:class 类—老司机的必修课
第12天:一把 sklearn 走天下
今天将带来第13天的学习日记,开始学习 TensorFlow,介绍的版本是1.X。本文先认识一下 TensorFlow 的建模流程,学习搭建一个 logistic 回归,再用 TensorFlow 跑一个深度神经网络。
目录如下:
前言
一、Windows 下 Tensorflow 快速安装
二、初识 Tensorflow
三、学习:Tensorflow 搭建 logistic 回归
四、练习:用 tensorflow 跑一个深度神经网络
五、TensorFlow高级API:tf.contrib.learn
前言
在12天的日记中,我们有了解过 sklearn 针对传统的机器学习,适合中小型的项目,那种数据量不大、CPU上就可以完成的运算。而 tensorflow 针对深度学习任务,适合数据量较大、一般需要GPU加速的运算。但是自由度比较高,需要自己动手写很多东西。
本文中,我们快速安装一下tensorflow,再简单认识一下tensorflow,再用 tensorflow 跑一个简单的 logistic regression,了解用 tensorflow 建模的基本零件工具。之后,再正式的跑一个神经网络。
(本文所有演示都是 tensorflow 1.X)
一、Windows 下 Tensorflow 快速安装
我们知道正是因为有了 Anaconda+Pycharm, 我们才可以愉快轻松的使用Python 以及它的各种库。使用 Tensorflow 也是一样,经过踩坑尝试,Windows 下最快的安装流程如下:
① 下载安装 Pycharm
② 下载安装 Anaconda3-4.2.0-Windows(对于的Python版本是3.5.x,这个很重要)
③ Pycharm 里的解释器(Interpreter)选择 Anaconda 下的 python.exe
④ Package中安装tensorflow(可以看到还是1.X版)
至此,我们就安装好了 Tensorflow,可以尝试在 Pycharm 中运行:
import tensorflow as tf
注意这里是CPU版本,GPU版本的设置我们后面有机会再介绍,先安装CPU版本学习一下。
二、初识 Tensorflow
在各种资料上,我们都看到过类似这样对 tensorflow 的介绍:
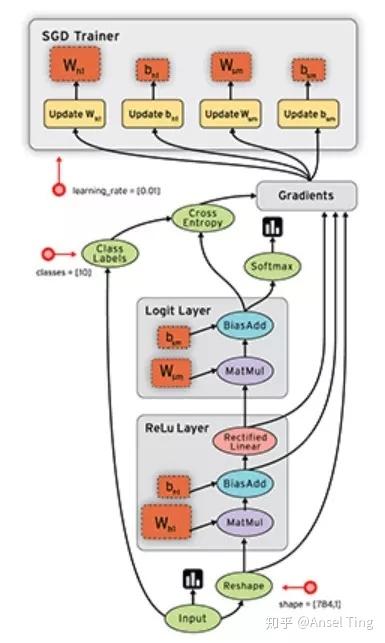
tensorflow 用图的形式来表示运算过程的一种模型,每一个节点都表示数学操作,线将其联系起来,即“张量”(tensor)
这是什么意思呢?在学习logistic模型的时候,我们了解过,构建一个模型需要哪些流程?
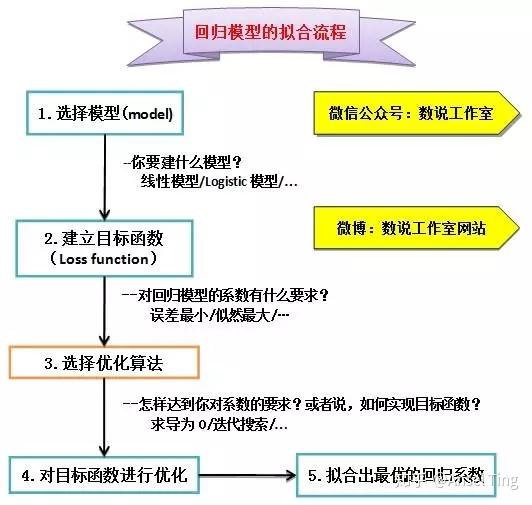
详见 logistic从生产到使用(下),构建一个模型,大致需要这样几个流程:
- 定义模型的形式(线性回归/logistic回归......)
- 建立目标函数(误差最小/似然最大......)
- 选择优化算法(用怎样的方法使得目标函数达到一个最优值)
- 优化目标函数,得到最佳参数
在tensorflow的数据流图中,就是要自己去定义这些运算模块,也就是构建 Graph,代码不会生效。之后要启动一个 Session,程序才会真正运行。先简单了解三个概念:
- graph:计算流图,在图中中定义了一些运算
- op:操作,graph都是由op组成的
- session:执行graph,给graph灌入数据,得到结果
我们就用 logistic regression 来学习一下 tensorflow 建模过程和这些概念。
三、学习:Tensorflow 跑 logistic 回归
如下图,一段 Tensorflow 程序我们大概要完成三步:准备数据、定义Graph、执行Session,先大体了解一下:
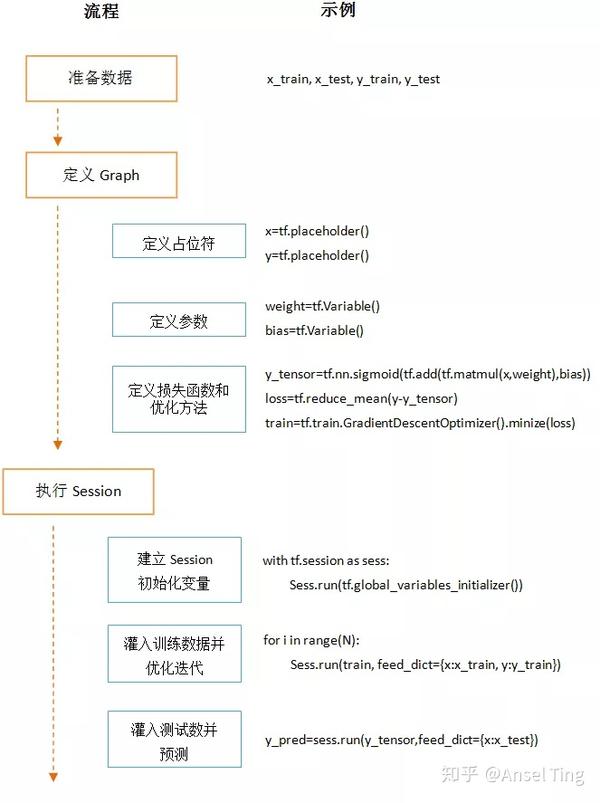
1、准备数据
1.1 划分数据集 train_test_split()
本文仍采用 iris 数据。首先划分数据集,训练集:测试集=7:3
#划分数据集
1.2 处理哑变量 get_dummies()
另外,这个数据的 lable 是多分类的,在上一文中(一把 sklearn 走天下),sklearn 可以自动用 one-vs-rest 的思路进行处理。Tensorflow 需要事先把多分类的处理成哑变量,我们把 y_train 和 y_test 处理成多分类的哑变量:
#哑变量
y_train=pd.get_dummies(y_train)
y_test=pd.get_dummies(y_test)2、定义 graph
我们要开始对模型框架进行一些定义, 具体来说:
我们先把一个模型中的占位符、变量定义出来,再定义损失函数、进而定义损失函数的优化方法,这基本可以理解为把模型的样子搭好了,
在后面执行session时,再把真实的数据喂给占位符,并执行优化方法,得到最优的参数。
2.1 定义数据占位符 tf.placeholder
placeholder 是占位符,大概意思是一个数据空壳,后期我们要把真实的数据灌进去。
#占位符
x=tf.placeholder(tf.float32,[None,4])
y=tf.placeholder(tf.float32,[None,3])2.2 定义变量 tf.Variable()
建模的本质就是找到最优的参数,这个参数就是我们要定义的变量。logistic 回归中,由于有四个特征,因此变量是 w1/w2/w3/w4,还有一个常量 bias。
但是,注意这里我们把y不是简单0/1的预测,因为y是3分类的,我们把y处理成了3分类的哑变量,在预测时候,我们需要对3类分别预测,取预测概率最大的结果。

因此在本例中,变量有4×3=12个,是一个4×3的矩阵,而且 bias 也不是一个,而是3个,即 3×1 的向量。
变量定义为:
#定义变量
weight=tf.Variable(tf.random_normal([4,3]),dtype=tf.float32)
bias=tf.Variable(tf.constant(0.01, shape=[6]))我们通过 tf.Variable() 创建 Variable 类的实例,向 graph 中添加变量。我们要在参数中定义好这个 Variable 的形状,用 tf.random_normal() 。
tf.random_normal() 函数是从正态分布中输出随机值。参数形式为:
random_normal这里shape就是[4,3],因为上面说过,weight 是一个4×3的矩阵。
2.3 定义损失函数和优化方法
这里,我们的损失函数是让y的预测值与真实值的均方误差,优化的目的是让这个损失函数最小:
#定义y的预测值y_pred_sgmd
y_pred=tf.add(tf.matmul(x,weight),bias)
y_pred_sgmd=tf.nn.sigmoid(y_label)
#定义损失函数loss:采用均方误差
loss=tf.reduce_mean(tf.square(y-y_pred_sgmd))
#定义迭代优化方法train:采用梯度下降
train=tf.train.GradientDescentOptimizer(0.2).minimize(loss)- tf.matmul(x, weight) 是矩阵x 乘以 矩阵weight。
- tf.add(tf.matmul(x, weight), bias) 就是再加上bias。
- tf.square(a) 是对a里每一个元素求平方。
- reduce_mean() 的形式如下:
reduce_mean作用是在第一个参数 input_tensor 矩阵中,按照 axis 指定维度求平均,axis不指定,将所有元素加总求平均值,axis=0,求纵轴平均值,=1求横轴平均值。比如:
x - tf.train.GradientDescentOptimizer(0.2) 梯度下降优化器,0.2是学习率。minimize(loss) 说明优化的目标是最小化 loss。
3、优化执行
我们要开始真正执行求解了,先灌入训练数据,再执行优化,得到最优模型之后,对测试集上的数据进行预测。
整体代码如下,后面分段解释:
#Session
with tf.Session() as sess:
#下面的code都是在这个sess下面
#变量初始化:给Graph图中的变量初始化
sess.run(tf.global_variables_initializer())
#迭代8000次
for i in range(8000):
sess.run(train, feed_dict={x:X_train,y:y_train})
#每1000次输出一次loss
if (i%1000==0):
print (sess.run(loss,feed_dict={x:X_train,y:y_train}))
#输出最终的参数:weight和bias
print (sess.run(weight), sess.run(bias))
#灌入测试数据
#直接输出3分类的结果
#3分类的原始概率结果
pred_y_3level = sess.run(y_label_sgmd, feed_dict={x: X_test})
print (pred_y_3level)
#选择概率最大的分类
y_argmax=tf.argmax(y_label_sgmd, 1)
y_pred=sess.run(y_argmax, feed_dict={x:X_test})
print (y_pred)
#计算精准、召回、F1 score
y_true=np.argmax(np.array(y_test),1)
print (y_true)
print("Precision", metrics.precision_score(y_true, y_pred,average='micro'))
print("Recall", metrics.recall_score(y_true, y_pred, average='micro'))
print("f1_score", metrics.f1_score(y_true, y_pred, average='micro'))3.1 建立 session
#建立session
with tf.Session() as sess:
#下面的code都是在这个sess下面这里表示建立一个会话Session,用于执行计算,同时也负责分配计算资源和变量存放。
3.2 变量初始化
#变量初始化:给Graph图中的变量初始化
sess.run(tf.global_variables_initializer())在使用变量之前,需要对变量进行初始化,使用 tf.global_variables_initializer() 来初始化全局变量。
3.3 灌入训练数据,训练模型
#迭代8000次
for i in range(8000):
sess.run(train, feed_dict={x:X_train,y:y_train})
#每1000次输出一次loss
if (i%1000==0):
print (sess.run(loss,feed_dict={x:X_train,y:y_train}))
#输出最终的参数:weight和bias
print (sess.run(weight), sess.run(bias))- feed_dict 的作用是给 placeholder 占位符进行赋值,灌入具体数据。
- sess.run(train, feed_dict={}) 就是运行我们之前定义的优化 train,并且灌入训练数据给 placeholder。
- sess.run(loss, feed_dict={}) 就是灌入训练数据给 placeholder,并运行 loss,print 出来,查看迭代过程的 loss 变化。
3.4 用测试数据,进行测试
#直接输出3分类的结果
#3分类的原始概率结果
pred_y_3level = sess.run(y_label_sgmd, feed_dict={x: X_test})
print (pred_y_3level)
#选择概率最大的分类
y_argmax=tf.argmax(y_label_sgmd, 1)
y_pred=sess.run(y_argmax, feed_dict={x:X_test})
print (y_pred)sess.run(y_label_sgmd,feed_dict={x: X_test})
就是灌入测试数据,执行 y_label_sgmd 。因为我们把y处理成了哑变量,所以 pred_y_3leve 是直接计算出来的是三分类每一类的概率,比如,执行 print (pred_y_3level) 的结果是:
[[ 1.14419532e-03 1.62675023e-01 9.32786524e-01]
[ 1.80235207e-02 7.11646140e-01 1.15287527e-01]
[ 9.94252741e-01 8.70510414e-02 4.32862507e-05]
[ 4.18097188e-04 5.59823513e-01 8.71750891e-01]
...
[ 9.83450115e-01 1.70802653e-01 9.36481520e-05]]
我们最终会选择概率最大的一类作为最终结果,所以我们把 y_label_sgmd 换成 tf.argmax(y_label_sgmd, 1) ,argmax(input, axis) 对矩阵input,根据axis取值的不同,返回每行(axix=1)或每列(axis=0)最大值的索引。
所以执行 print (y_pred) 后的结果大概是:
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 2 0 2 2 0 0 2 2 0 0 2 0 0 1 1 0 2 2 0 2 2 2 0 2 1 1 2 0 2 0 0]
3.5 模型评价
#计算精准、召回、F1 score
y_true = np.argmax(np.array(y_test), 1)
print("Precision", metrics.precision_score(y_true, y_pred,average='micro'))
print("Recall", metrics.recall_score(y_true, y_pred, average='micro'))
print("f1_score", metrics.f1_score(y_true, y_pred, average='micro'))这里仍然使用 sklearn 的 metrics 计算精准、召回、F1 score(from sklearn import metrics),在上一天的日记中已经学习过(一把 sklearn 走天下)。最终执行结果为:
Precision 0.844444444444
Recall 0.844444444444
f1_score 0.844444444444
四、练习:用 tensorflow 跑一个深度神经网络
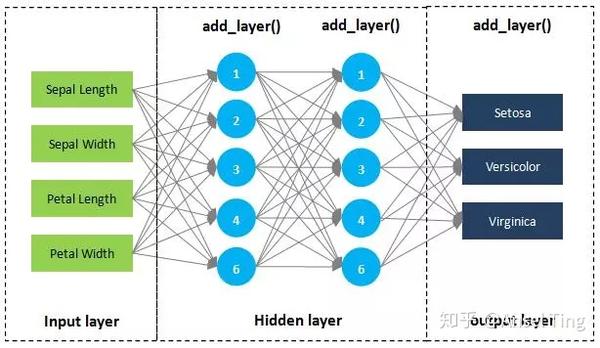
我们仍以 iris 数据集为例,用神经网络来对鸢尾花的品种进行预测。神经网络的基本概念,比如神经元、激活函数等,这里不做介绍。我们对神经网络做如下设计:
① 输入层,是4个特征。
② 隐含层有一层,我们用6个神经元。
③ 输出层有3个输出,分别代表每一个品种的概率。
④ 对输出层的3个概率,取最大概率作为最终结果。
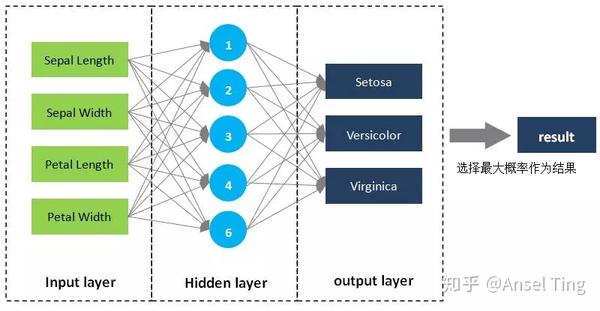
code如下所示,总体框架思路不变,仍然是数据准备、定义Graph、执行Session,Session 中先初始化变量,再执行训练、执行预测、查看效果。
#coding:utf-8
import tensorflow as tf
from sklearn import datasets
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn import metrics
#1.数据处理
#1.1训练集/测试集
iris=datasets.load_iris()
X=iris.data
y=iris.target
X_train, X_test, y_train, y_test=train_test_split(X,y,test_size=0.3,random_state=0)
#1.2处理哑变量
y_train=pd.get_dummies(y_train)
y_test=pd.get_dummies(y_test)
#2.定义Graph
#2.1占位符
x = tf.placeholder(tf.float32,[None,4])
y = tf.placeholder(tf.float32,[None,3])
#2.2输入→隐藏层,6个神经元,4个输入
w1 = tf.Variable(tf.random_normal([4, 6]), dtype=tf.float32)
b1 = tf.Variable(tf.constant(0.01, shape=[6]))
y1 = tf.nn.sigmoid(tf.matmul(x, w1) + b1)
#2.3隐藏层→输出层,3个输出,6个输入
w2 = tf.Variable(tf.random_normal([6, 3]), dtype=tf.float32) # 输出层,3个神经元,10个输入
b2 = tf.Variable(tf.constant(0.01, shape=[6]))
y_label_sgmd = tf.nn.sigmoid(tf.matmul(y1, w2) + b2)
#2.4loss和train
loss=tf.reduce_mean(tf.square(y-y_label_sgmd))
train=tf.train.GradientDescentOptimizer(0.05).minimize(loss)
#3启动Session
with tf.Session() as sess:
#3.1变量初始化:给Graph图中的变量初始化
sess.run(tf.global_variables_initializer())
#3.2执行训练,并查看loss
for i in range(4000):
sess.run(train, feed_dict={x:X_train,y:y_train})
if (i%1000==0):
print ('step=',i,',loss=',sess.run(loss,feed_dict={x:X_train,y:y_train}))
#3.3执行预测,查看结果
y_argmax = tf.argmax(y_label_sgmd, 1)
y_pred = sess.run(y_argmax, feed_dict={x: X_test})
y_true = np.argmax(np.array(y_test), 1)
print('预测结果:',y_pred)
print('真实结果:',y_true)
#3.4计算精准、召回、F1 score
y_true = np.argmax(np.array(y_test), 1)
print("Precision", metrics.precision_score(y_true, y_pred, average='micro'))
print("Recall", metrics.recall_score(y_true, y_pred, average='micro'))
print("f1_score", metrics.f1_score(y_true, y_pred, average='micro'))结果如下:
step= 0 ,loss= 0.324072
step= 1000 ,loss= 0.180962
step= 2000 ,loss= 0.134391
step= 3000 ,loss= 0.110529
step= 4000 ,loss= 0.0967584
预测结果: [2 1 0 2 0 2 0 1 1 1 2 1 2 1 2 0 1 2 0 0 2 2 0 0 2 0 0 1 1 0 2 2 0 2 2 1 0 2 1 1 2 0 2 0 0]
真实结果: [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0 1 1 1 2 0 2 0 0]
Precision 0.866666666667
Recall 0.866666666667
f1_score 0.866666666667
code中的2.2和2.3是定义神经网络的内部结构,分别是:
- 输入层→隐藏层
- 隐藏层→输出层
这两个结构基本是一样的,我们也可以把这个过程打包成一个函数 add_layer(),一个添加层的函数,避免重复定义。同时还能隐藏层可以多定义几层。
我们定义一个添加层的函数 add_layer(),中间设计2个隐藏层,如下所示:
code如下:
import tensorflow as tf
from sklearn import datasets
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn import metrics
#1.数据处理
#1.1训练集/测试集
iris=datasets.load_iris()
X=iris.data
y=iris.target
X_train, X_test, y_train, y_test=train_test_split(X,y,test_size=0.3,random_state=0)
#1.2处理哑变量
y_train=pd.get_dummies(y_train)
y_test=pd.get_dummies(y_test)
#2.定义Graph
#2.1占位符
x = tf.placeholder(tf.float32,[None,4])
y = tf.placeholder(tf.float32,[None,3])
#2.2定义添加层函数 add_layer()
def add_layer(input, input_n, output_n):
w = tf.Variable(tf.random_normal([input_n, output_n]), dtype=tf.float32)
b = tf.Variable(tf.constant(0.01, shape=[output_n]))
output= tf.nn.sigmoid(tf.matmul(input, w) + b)
return output
#2.3添加隐藏层和输出层
#第一个隐藏层,6个神经元,4个输入
y1=add_layer(x,4,6)
#第二个隐藏层,6个神经元,6个输入
y2=add_layer(y1,6,6)
#输出层,3个输出,6个输入
y_label_sgmd=add_layer(y2,6,3)
#2.4loss和train
loss=tf.reduce_mean(tf.square(y-y_label_sgmd))
train=tf.train.GradientDescentOptimizer(0.05).minimize(loss)
#3启动Session
with tf.Session() as sess:
#3.1变量初始化:给Graph图中的变量初始化
sess.run(tf.global_variables_initializer())
#3.2执行训练,并查看loss
for i in range(5000):
sess.run(train, feed_dict={x:X_train,y:y_train})
if (i%1000==0):
print ('step=',i,',loss=',sess.run(loss,feed_dict={x:X_train,y:y_train}))
#3.3执行预测,查看结果
y_argmax = tf.argmax(y_label_sgmd, 1)
y_pred = sess.run(y_argmax, feed_dict={x: X_test})
y_true = np.argmax(np.array(y_test), 1)
print('预测结果:',y_pred)
print('真实结果:',y_true)
#3.4计算精准、召回、F1 score
y_true = np.argmax(np.array(y_test), 1)
print("Precision", metrics.precision_score(y_true, y_pred, average='micro'))
print("Recall", metrics.recall_score(y_true, y_pred, average='micro'))
print("f1_score", metrics.f1_score(y_true, y_pred, average='micro'))结果如下:
step= 0 ,loss= 0.2868q43
step= 1000 ,loss= 0.165464
step= 2000 ,loss= 0.132134
step= 3000 ,loss= 0.1124
step= 4000 ,loss= 0.0921755
预测结果: [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0 2 1 1 2 0 2 0 0]
真实结果: [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0 1 1 1 2 0 2 0 0]
Precision 0.977777777778
Recall 0.977777777778
f1_score 0.977777777778
五、TensorFlow高级API:tf.contrib.learn
除了tensorflow的固有套路,还可以用 tf.contrib.learn,这是TensorFlow的高级API,里面内置了一些已经封装好的 Estimator。如:
- 线性回归
tf.contrib.learn.LinearRegressor - 逻辑回归
tf.contrib.learn.LogisticRegressor - 线性分类
tf.contrib.learn.LinearClassifier - 深度神经网络DNN
tf.contrib.learn.DNNClassifier
对于本例,使用这个API(tf.contrib.learn.DNNClassifier)可以:
不用设置哑变量、不用做各种定义、只需要10行代码
公众号后台回复【tfapi】获取代码。

推荐阅读:
- 机器学习分类大全
- 一把 sklearn 走天下
- 3行代码实现 Python 并行处理,速度提高6倍!
- 海量文本用 Simhash, 2小时变4秒!
- 循环、分支...都可以在Python中用函数实现! | 函数式编程,打开另一个世界的大门
- Python & R 代码 对照速查表
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









