





环境
Python
python --version
(mac自带)
brew install python
pip
pip --version
pip 是 Python 包管理工具,该工具提供了对Python 包的查找、下载、安装、卸载的功能
curl https://bootstrap.pypa.io/get... -o get-pip.py
sudo python get-pip.py
安装依赖
pip freeze >package.txt
sudo pip install -r package.txt
启动
cd index
chmod a+x ziru_room.py
python ziru_room.py
思路分析
1.反反爬虫
一般公司都有安全部门,防止大规模的撞库或者带宽挤占,那爬取的时候肯定会被拦截,定位然后律师函警告。
所以我觉得一个爬虫系统最重要的就是反 反爬虫。
我们先分析一下,一般简单的反爬虫什么思路?
用户请求的Headers,用户行为,网站目录和数据加载方式
headers里面主要根据userAgent查重。userAgent 属性是一个只读的字符串,声明了浏览器用于 HTTP 请求的用户代理头的值。简单来说就是浏览器向服务器”表明身份“用的。
用户行为主要靠ip。ip的话不用讲了,和身份证号差不多,所以我们发起请求应该用动态的,同一ip多次访问就可能被拉入ip黑名单,而且会导弹定位到你的服务器所在位置。
第三个方式比较高端了,我这次没有展示。前两种是爬虫伪装成浏览器读取数据,但是第三种是模拟出一个浏览器进行用户点击提交等操作,它本身就是一个没有界面的浏览器,从填写表单到点击按钮再到滚动页面,全部都可以模拟。这时候就可以根据一些其它方式,如识别点触式(12306)或者滑动式的验证码。
整理好思路开始实现,我们的目标是实现一个动态的ip和userAgent池,每次请求伪装成不一样的来源
step1: 我们去爬取一个开放代理ip的网站。。。然后试试他开放的ip可不可用,可用的话加入我们的ip池。 详见 代码 ziru_room.py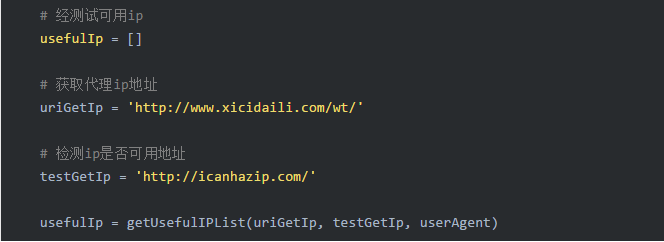
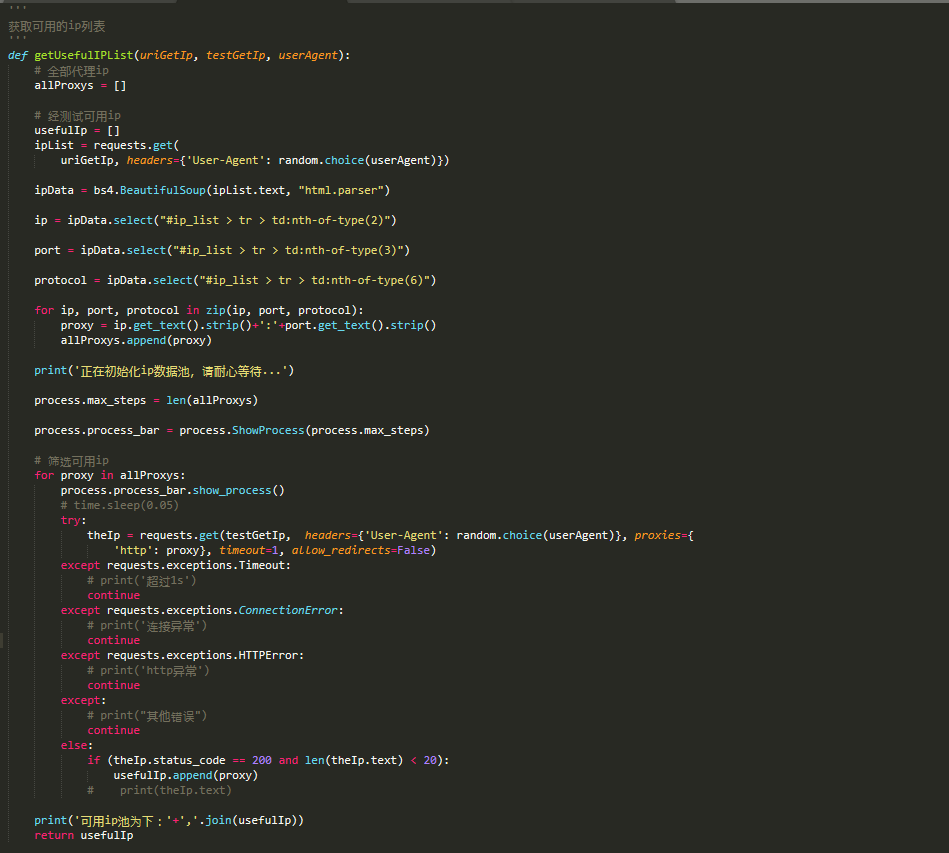
step2: 构造userAgent池
这个不像ip会经常挂,所以写死问题不大。
2.爬取数据
我们的原材料准备好了,开始爬取,可以看见用的是random.choice()去ip,userAgent池取得随机配置 组成 get请求。详见 代码 ziru_room.py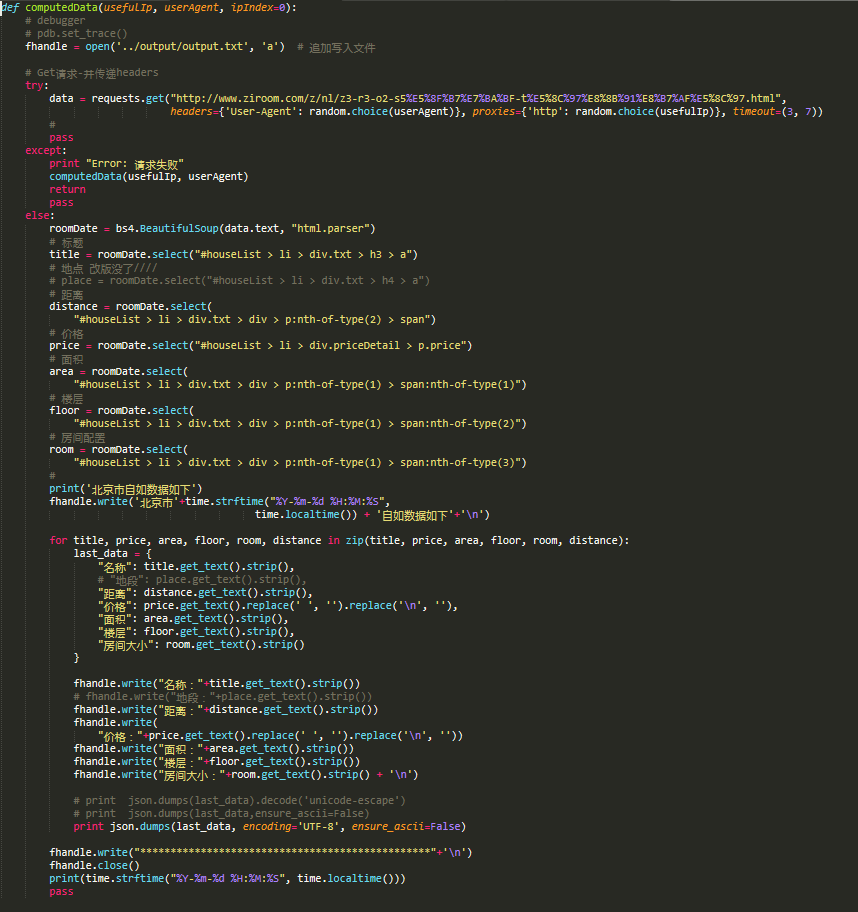
3.其他部分
因为爬取可用的ip组成ip池,是一个比较耗时的过程,所以加入了图像化的等待显示,详见 代码 process.py
自动化爬取要有点节操,所以得加入延时,详见 代码 ziru_room.py
while(True):
computedData(usefulIp, userAgent)time.sleep(60)
python 一点其他感触,写起来很简洁,这个换行缩进还有dict对象中文Unicode搞了很久。。。目前和node相比优缺点在哪里还没有分析好,可以留言探讨下。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









