







selenium python 简单入门
大家好,相信大家想把网页内容手动点击才能看的东西自动批量的获取下来,包括想保存知识内容,做资料搜集,计算价格等等,但苦于过往的方法都有点难,知道使用webkit核心的chrome ,firefox,edge等的浏览器的出现,在加上附带内置的自动化测试工具,让这些事情变的比较简单容易,隆重介绍(装作好像只有我知道一样),selenium !!!这个就是自动化测试工具,它不但可以获取页面元素,下载还可以模拟键盘,鼠标,点击,拖放等等
1.安装
假设大家都用chrome
首先我们要确定chrome的版本
emmm 打开浏览器看我觉得太低端,上代码:
import subprocess
cmd="(Get-Item (Get-ItemProperty 'HKLM:\SOFTWARE\Microsoft\Windows\CurrentVersion\App Paths\chrome.exe').'(Default)').VersionInfo|select FileVersion"
completed = subprocess.run(["powershell", "-Command", cmd], capture_output=True)
print(completed.stdout.decode().strip().splitlines()[2])
这个是在python 上运行powershell 语句去获取chrome语句
stdout 是 bytes 类型,所以我需要decode()
strip() 拔走一些空格,其实并没有
splitlines() 把它拆成多行文本
[2]第三行
好吧,我以为大家都不懂,所以我水了…
接着要装 chromedriver ,selenium需要指明不同浏览器对应的driver才可以使用
去这里下载对应chrome版本的 chromedriver,如果你使用开发版(金雀)的话就需要下载金雀版的chromedriver,至于firefox,edge,phantomjs都是一样,用法并无二致就不多说了
https://chromedriver.chromium.org/
如果学会了selenium甚至可以根据版本去这个网直接爬下来,嗯,我就是这么做的
在python 运行selenium打开chromedriver之前,是必须要增加参数的,那首先就开始第一条selenium的实例
import time
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
import re
class hello:
def __init__(self,url,selepath='c:\\1\\selenium\\chromedriver\\98\\chromedriver.exe'):
self.url=url
self.seleniumpath=selepath
ser = Service(self.seleniumpath)
"""
这个是新版本的selenium指定的语法,以前是用Options
在这里还能自己加上 header 等语句,后面会找例子解释
"""
self.driver=webdriver.Chrome(service = ser)
"""
无头模式 --headless,就是后台运行,不会看见有chrome打开,测试就不打开了
包含多种参数
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
#chrome_options.add_argument("--disable-extensions")
#chrome_options.add_argument("--disable-gpu")
#chrome_options.add_argument("--no-sandbox") # linux only
chrome_options.add_argument("--headless")
# chrome_options.headless = True # also works
driver = webdriver.Chrome(service = ser,options=chrome_options)
"""
self.driver.maximize_window()
#self.driver.
#窗口最大化
self.driver.get(self.url)
#打开网页
def closedriver(self):
self.driver.close()
x=hello('https://www.baidu.com')
x.closedriver()
注意自己保存的chromedriver路径
注意打开的网站必须有 https:// 或 http://开头
注意最后要做 closedriver() 关闭driver,不然就会有机会把driver留在进程,别怕,它很安静,就是呆呆的,一动也不动,也不会出来咬你屁股
旧版本你开多少次你不关它就有多少个,现在大几率只有一两个了
如何获取网页元素(element)
有学过一点dom,或者其他爬虫的话,都知道通常是怎么捕获网页元素的,分别是 class名,id名,包含名,xpath路径,ccs选择器,tag等等,列出来的最常用,其实还有别的这里不细说了
怎么找到这些元素的名字呢
用浏览器 的 devtools吧,打开chrome后按f12或ctrl+shift+i就会打开开发者工具,然后你就可看到整个网页渲染后的代码,嗯,是渲染后的,这个很关键
随便拿百度百科练练手吧
打开devtools 然后点一下
 这个按钮
这个按钮
然后指向你想要的获取的网页元素
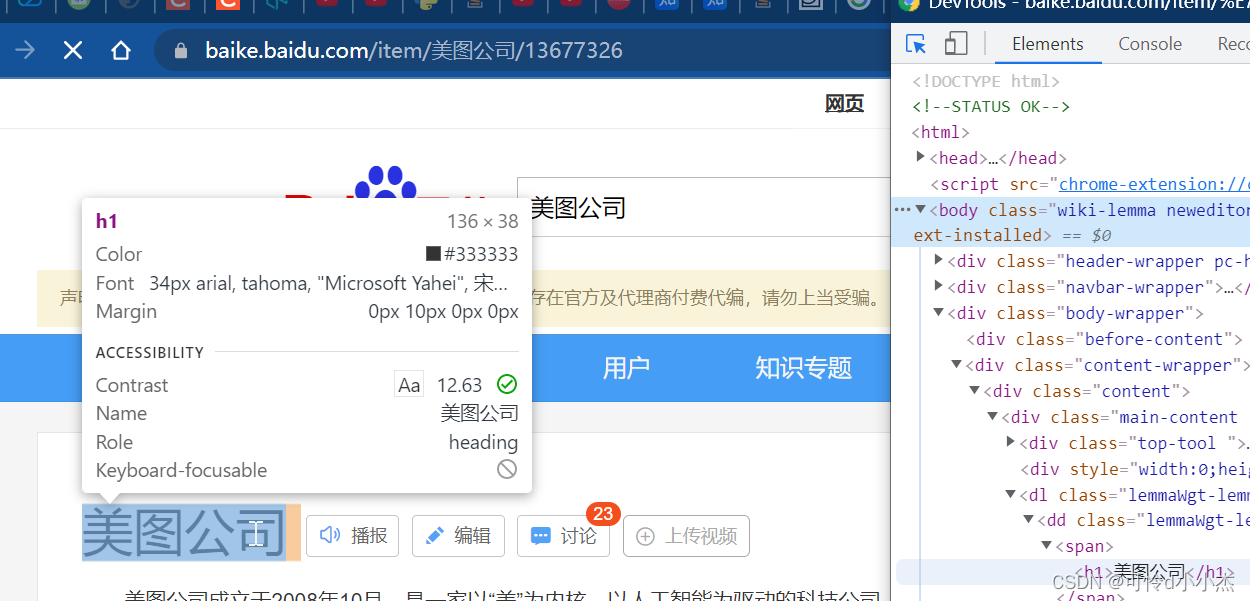
就很简单的知道这个元素的位置
再右键>复制
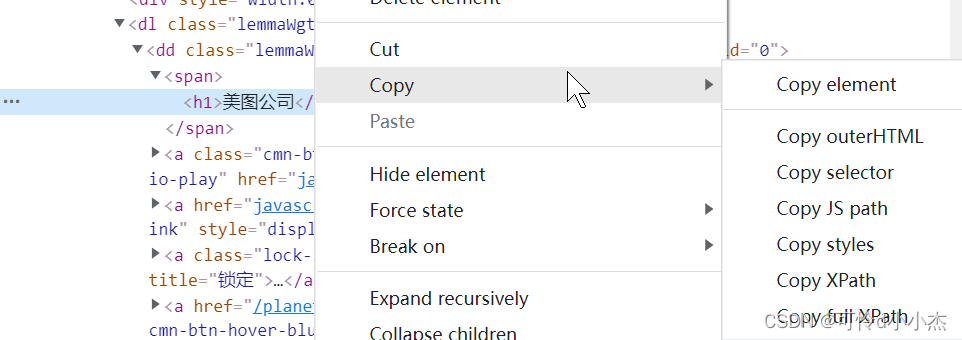
有必要讲解一下:
copy element: 当前的网页代码段,包括嵌套的都会一次复制
copy outerHtml:差不多同上不知道有啥区别
copy jspath js路径
copy styles: css style
copy xpath: xpath 路径 它会尽量用@classname @id 作为路径,也是 findbyelement (by.xpath) (待会示范)
copy full xpath : 绝对xpath路径
xpath 是最快的最准确,但是路径也是最长的,嫌麻烦可以单独获取 classname id 等等,方法是选取元素后再下面的properties就可以看到了
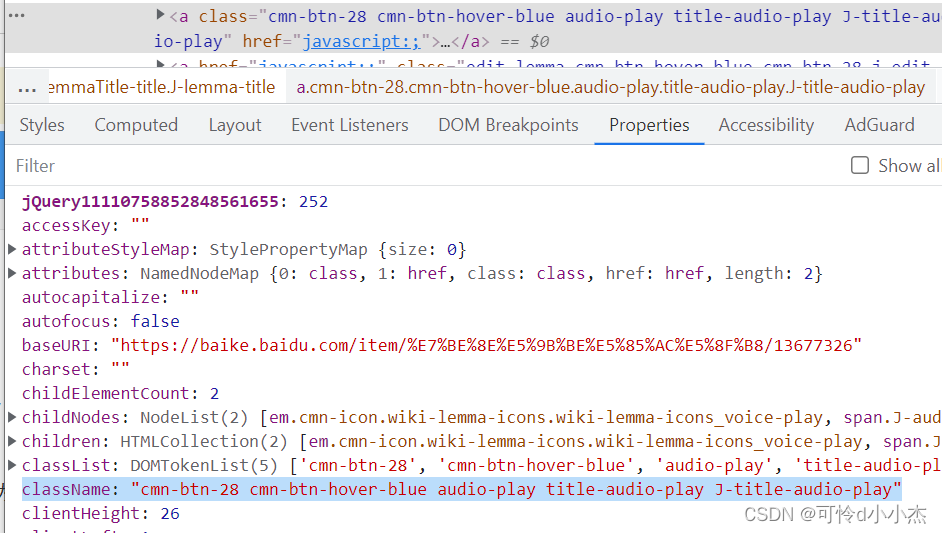
好了,复制了路径,就可以获取元素内容了,请看下面代码:
x=self.driver.find_element(By.CSS_SELECTOR,"body")
y=self.driver.find_element(By.XPATH,"/html/body/div[3]/div[2]/div/div[1]/dl[1]/dd/a[1]")
#xpath绝对路径
z=self.driver.find_element(By.class_namee,"cmn-btn-28.cmn-btn-hover-blue.audio-play.title-audio-play.J-title-audio-play")#classname 不允许空格,空格用.代替
上面的是简单版的,不是很保险,就以后再补充吧
然后捕获元素,就可以拿到里面的内容了
z.get_attribute('textContent')
#获取文本内容
z.get_attribute('innerHTML')
#获取该元素下的整片代码
z.get_attribute('href')
#获取网址
z.get_attribute('src')
#加载的文件内容,如图片,js,文件等等
接着是模拟鼠标,键盘动作了
首先讲轻度,对于单一的操作
z.click()
z.send_key("abcd")
z.send_key(Keys.PAGE_DOWN)
尤其是PAGE_DOWN 这个是用来翻页的,因为是模拟渲染效果,所以翻页是必须的
多个动作 action chains:
source_element = self.driver.find_element(By.link_text,"Courses")
target_element = self.driver.find_element(By.link_text,"Hard")
action = ActionChains(self.driver)
#action.move_to_element(By.class_name,"xxx")
#action.sendkeys
#action.click()
action.drag_and_drop(source_element, target_element)
action.perform()
就是把多个动作放到action ,然后perform()释放
由于变幅问题,还有延时执行,切换tab,iframe就下次再讲吧














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









