







关注vx :follow_bobo,加入机器学习群
公众号回复:style, 获得可运行完整代码

卷积神经网络图像风格转换 Neural network Style Transfer



首先由Gatys,Ecker和Bethge(A Neural Algorithm of Artistic Style in 2015)发表的开创性论文说起,它展示了将一个图像的艺术风格与另一个图像的内容相结合的方法。
基本思想就是采用由预训练的深度卷积神经网络(例如VGG 16)学习的特征表示来获得图像的样式和特征表示(feature Representaton)。 一旦找到这些表示,那么我们尝试优化生成的图像以重新组合不同目标图像的内容和样式。 因此,该概念使纹理,对比度和颜色随机化,同时保留内容图像的形状和语义特征。 虽然它有点类似于颜色转换,但它将自身与传递纹理(样式)和其他各种扭曲的能力分开,而传统的颜色过滤器是不可能保存各种纹理的。
这里给出了内容照片X和样式照片Y,我们如何将Y的样式转移到内容X以生成新的照片Z.我们如何训练CNN来处理和优化差异(X和Y之间的差异)达到最佳全局(Z)?
Gatys在原始论文(A Neural Algorithm of Artistic Style in 2015)中表示:
“将输入图像转换为另一个样式图像的样式(纹理)作为优化问题,可以通过训练深度神经网络来解决”

风格转换基础网络结构
内容丢失(Content Loss):它表示传输网络的输出图像的内容与输入图像的内容或“内容目标”的相似程度,如果输入图像(X)和样式图像(Y)在内容方面彼此相似,它(内容丢失值)往往为零,如果它们不同则会增长。 为了正确捕获图像的内容,我们需要保留内容图像的空间(形状,边界等)和高级特征。 由于像VGG16这样的图像分类卷积神经网络被迫在更深层学习高级特征/抽象表示或图像的“内容”,因此对于内容比较,我们在更深层使用激活(activation)/特征映射 或者在输出(softmax)层之前的2层。 可以根据需要选择L(从中提取内容特征的层),并且所选择的层越深,输出图像看起来就越抽象。 所以L是网络的超参数。

Gram矩阵和风格丢失(Style Loss):这个听起来稍微复杂一点,原始样式图像(Y)和网络输出图像(Z)之间的风格损失也被计算为从VGG-16的层输出中提取的特征(激活后)之间的距离。 这里的主要区别在于,不是直接从VGG-16的层比较特征表示,而是将那些特征表示转换成空间相关矩阵(在激活特征中),这通过计算Gram矩阵来完成。 Gram矩阵包含样式图像的各层中每对特征图之间的相关性。 因此,基本上Gram矩阵捕获了在图像的不同部分共同出现的特征趋势。它表示一组向量的内部点积,这样可以捕获了两个向量之间的相似性,如果两个向量彼此相似, 然后他们的点积将很大,因此Gram矩阵将很大。

那我们要如何理解Gram在风格转换中的应用呢?Gram矩阵就是每一层滤波后的feature map, 后将其转置并相乘得到的矩阵,如下图所示。其实就是不同滤波器滤波结果feature map两两之间的相关性。譬如说,(如下图)某一层中有一个滤波器专门检测尖尖的塔顶这样的东西,另一个滤波器专门检测黑色。又有一个滤波器负责检测圆圆的东西,又有一个滤波器用来检测金黄色。对梵高的原图做Gram矩阵,谁的相关性会比较大呢?如上图所示,“尖尖的”和“黑色”总是一起出现的,它们的相关性比较高。而“圆圆的”和“金黄色”都是一起出现的,他们的相关性比较高。因此在风格转移的时候,其实也在风景图里去寻找这种“匹配”,将尖尖的渲染为黑色,将圆圆的渲染为金黄色。如果我们承认“图像的艺术风格就是其基本形状与色彩的组合方式” ,这样一个假设,那么Gram矩阵能够表征艺术风格就是理所当然的事情了。
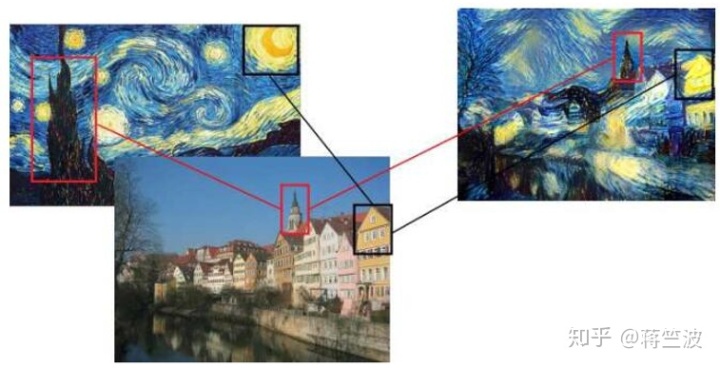
在原文中,Gatys建议采用浅conv层和深conv层的结合来计算风格损失,用于风格表示。因此,风格丢失是每个conv层激活矩阵的原始样式图像(Y)与生成的图像(Z)在样式特征上的均方差(欧氏距离)和。

总损失:总损失是内容损失和风格损失的加权总和,如下所示。

训练网络的目的是同时最小化内容丢失和风格丢失。 α和β是内容丢失和风格丢失的权重,也是整个CNN的超参数。 这些值的选择仅取决于生成的图像(Z)中需要保留多少内容或风格。 这里我们从随机(白噪声)图像矩阵开始,并在每次迭代中计算内容图像(内容丢失)和风格图像(样式丢失)之间的特征图距离(总损失)以计算总损失。 这种损失通过网络反向传播,然后通过适当的优化技术(相当于梯度下降)在迭代(几千次)上最小化总损失,以更新随机图像矩阵,尽可能接近内容和样式图像。 直到我们获得最小阈值损失值以生成优化的混合图像(Z),其看起来类似于内容(X)和样式图像(Y)
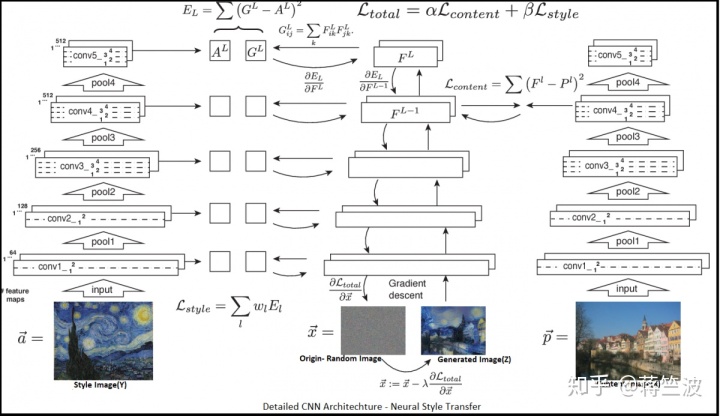
根据上述典型的NST网络,在较深层计算内容丢失以捕获高级特征(空间),而对于样式图像捕获详细风格特征(纹理,颜色等),在每个转换块的浅层(conv-1)通过提取网络输出来计算风格损失 。 典型的预训练分类CNN如VGG16由几个转换块组成,其具有2或3个卷积(Conv2D)层(conv1,conv2等),然后是池化层。所以样式图像网络是 多输出模型。
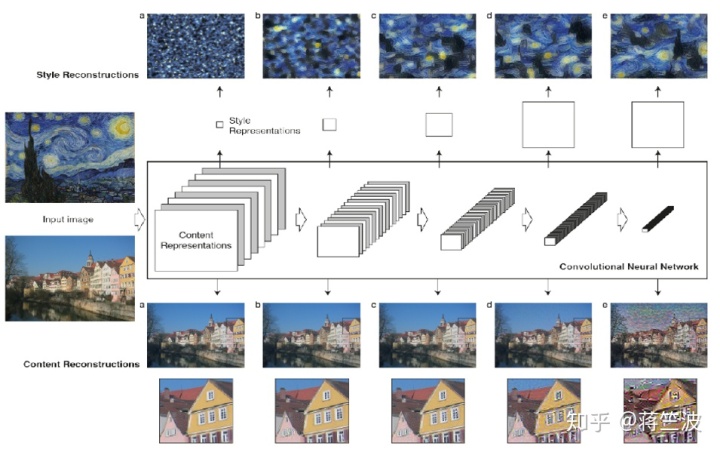
Neural Style Transfer on real-time Video因为视频只是一组图像的集合。这些图像被称为帧,可以组合得到原始视频。所以我们可以循环所有单独帧的步骤,重新组合并生成风格化的视频。
Step 1: Loading pre-trained VGG-16 CNN model
我们将使用Keras应用程序用预先训练的权重加载VGG-16。
from keras.applications.vgg16 import VGG16
shape = (224,224)
vgg=VGG16(input_shape=shape,weights='imagenet',include_top=False)Step 2: Define the content model and cost function
对于高级内容功能,考虑到要保存图像全局特征。因此我们将使用平均池化(average pooling) 替换max-pool(可能会丢弃一些信息)。然后我们将从13个卷积层中选择任何更深层作为“输出”并将模型定义到该层。 然后我们将在n / w中提供我们的预处理内容图像(X),以在输出层计算(预测)特征/激活图,该模型的模型输出与定义形状的任何随机(白噪声)矩阵相对应 (224 x 224 x 3)。 我们计算内容图像网络的MSE损失和梯度。有助于将输入图像(随机图像)更新为梯度的相反方向,并允许内容丢失值减小,以便生成的图像将与输入的图像匹配 图片。
content_model = vgg_cutoff(shape, 13)
#Can be experimented with other deep layers
# make the target
target = K.variable(content_model.predict(x))
# try to match the input image
# define loss in keras
loss=K.mean(K.square(target content_model.output))
# gradients which are needed by the optimizer
grads = K.gradients(loss, content_model.input)Step 3: Define the style model and style loss function
两个图像的特征图在给定层产生相同的Gram矩阵,我们希望两个图像具有相同的样式(但不一定是相同的内容)。因此,网络中早期层中的激活图将捕获一些更精细的纹理( 低级特征),而激活贴图更深的层将捕获更高级别的图像样式元素。为了获得最佳结果,我们将结合浅层和深层作为输出来比较图像的样式表示和 我们相应地定义了多输出模型。
首先,我们计算每层的Gram矩阵,并计算样式网络的总样式损失。 我们对不同的层采用不同的权重来计算加权损失。 然后基于样式损失(样式分量的差异)和渐变,我们更新输入图像(随机图像)并减少样式损失值,使得生成的图像(Z)纹理看起来类似于样式图像(Y)。
#Define multi-output model
symb_conv_outputs = [layer.get_output_at(1) for layer in vgg.layers
if layer.name.endswith('conv1')]
multi_output_model = Model(vgg.input, symb_conv_outputs)
#Style feature map(outputs) of style image
symb_layer_out = [K.variable(y) for y in multi_output_model.predect(x)]
#Defining Style loss
def gram_matrix(img):
X = K.batch_flatten(K.permute_dimensions(img,(2,0,1)))
gram_mat = K.dot(X,K.transpose(X))/img.get_shape().num_elements()
return gram_mat
def style_loss(y,t):
return K.mean(K.square(gram_matrix(y)-gram_matrix(t)))
#Style loss calculation through out the network
#Defining layer weights for layers
weights = [0.2,0.4,0.3,0.5,0.2]
loss=0
for symb,actual,w in zip(symb_conv_outputs,symb_layer_out,weights):
loss += w * style_loss(symb[0],actual[0])
grad = K.gradients(loss,multi_output_model.input)
get_loss_grad=K.Function(inputs=[multi_output_model.input], outputs=[loss] + grad)Step 4: Define the total cost(overall loss)
现在我们可以将内容和样式损失结合起来以获得网络的整体损失。我们需要使用合适的优化算法在迭代中最小化该数据。
#Content Loss
loss=K.mean(K.square(content_model.output-content_target)) * Wc #Wc is content loss weight(hyperparameter)
#Defining layer weights of layers for style loss
weights = [0.2,0.4,0.3,0.5,0.2]
#Total loss and gradient
for symb,actual,w in zip(symb_conv_outputs,symb_layer_out,weights):
loss += Ws * w * style_loss(symb[0],actual[0]) #Wc is content loss weight(hyperparameter)
grad = K.gradients(loss,vgg.input)
get_loss_grad = K.Function(inputs=[vgg.input], outputs=[loss] + grad)Step 5: Solve the optimization problem
在定义整个符号计算图之后,优化算法是主要组件,其将能够迭代地最小化整体网络成本。 这里不使用keras标准优化器函数(例如optimizers.Adam,optimizers.sgd等),这可能需要更多时间,我们将使用有限内存BFGS(Broyden-Fletcher-Goldfarb-Shanno),这是一个近似的数值 使用有限数量的计算机内存的优化算法。 由于其产生的线性存储器要求,该方法非常适用于涉及大量无关变量(参数)的优化问题。 与普通BFGS一样,它是一种标准的准牛顿方法,通过最大正则化对数似然来优化平滑函数。
Scipy的最小化函数(fmin_l_bfgs_b)允许我们传回函数值f(x)及其渐变f'(x),我们在前面的步骤中计算过。 但是,我们需要将输入展开为1-D数组格式的最小化函数,并且丢失和渐变都必须是np.float64。
#Wrapper Function to feed loss and gradient with proper format to L-BFGS
def get_loss_grad_wrapper(x_vec):
l,g = get_loss_grad([x_vec.reshape(*batch_shape)])
return l.astype(np.float64), g.flatten().astype(np.float64)
#Function to minimize loss and iteratively generate the image
def min_loss(fn,epochs,batch_shape):
t0 = datetime.now()
losses = []
x = np.random.randn(np.prod(batch_shape))
for i in range(epochs):
x, l, _ = scipy.optimize.fmin_l_bfgs_b(func=fn,x0=x,maxfun=20)
# bounds=[[-127, 127]]*len(x.flatten())
#x = np.clip(x, -127, 127)
# print("min:", x.min(), "max:", x.max())
print("iter=%s, loss=%s" % (i, l))
losses.append(l)
print("duration:", datetime.now() - t0)
plt.plot(losses)
plt.show()
newimg = x.reshape(*batch_shape)
final_img = unpreprocess(newimg)
return final_img[0]Step 6: Run the optimizer function
在输入内容框架和样式图像上运行优化器,并根据定义的符号计算图形,深度网络完成其最小化总体损失的预期工作,并生成看起来与内容和样式图像一样接近的图像。
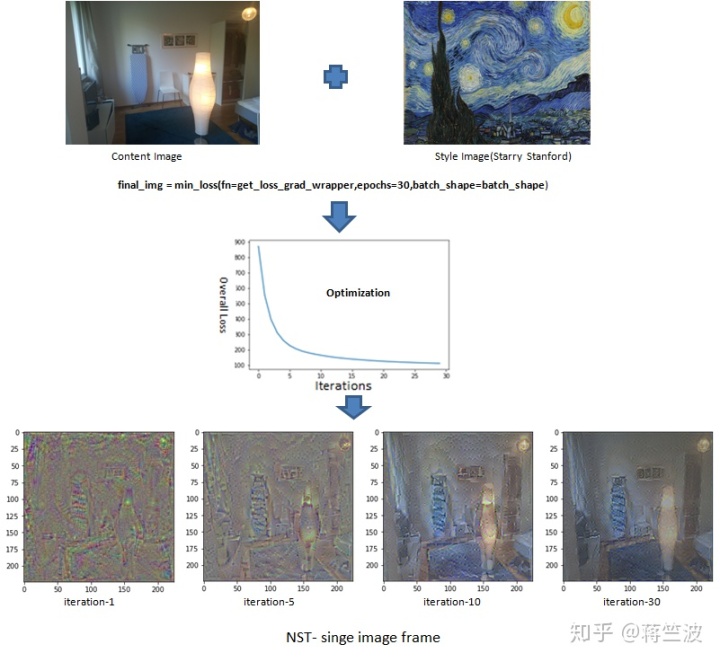
输出图像仍然很嘈杂,因为我们只运行网络30次迭代。理想的NST网络应针对数千次迭代进行优化,以达到最小损耗阈值,从而生成清晰的混合输出。
#Vedio Reading and extracting frames
cap = cv2.VideoCapture(path)
while(True):
ret, frame = cap.read()
frame = cv2.resize(frame,(224,224))
X = preprocess_img(frame)
#Running the above optimization as per defined comutation graph and generate styled image frame#
final_img = min_loss(fn=get_loss_grad_wrapper,epochs=30,batch_shape=batch_shape)
plt.imshow(scale(final_img))
plt.show()
cv2.imwrite(filename, final_img)
#Recombine styled image frames to form the video
video = cv2.VideoWriter(video_name, 0, 1, (width,height))
for image in images:
video.write(cv2.imread(os.path.join(image_folder, image)))
cv2.destroyAllWindows()
video.release()
Output: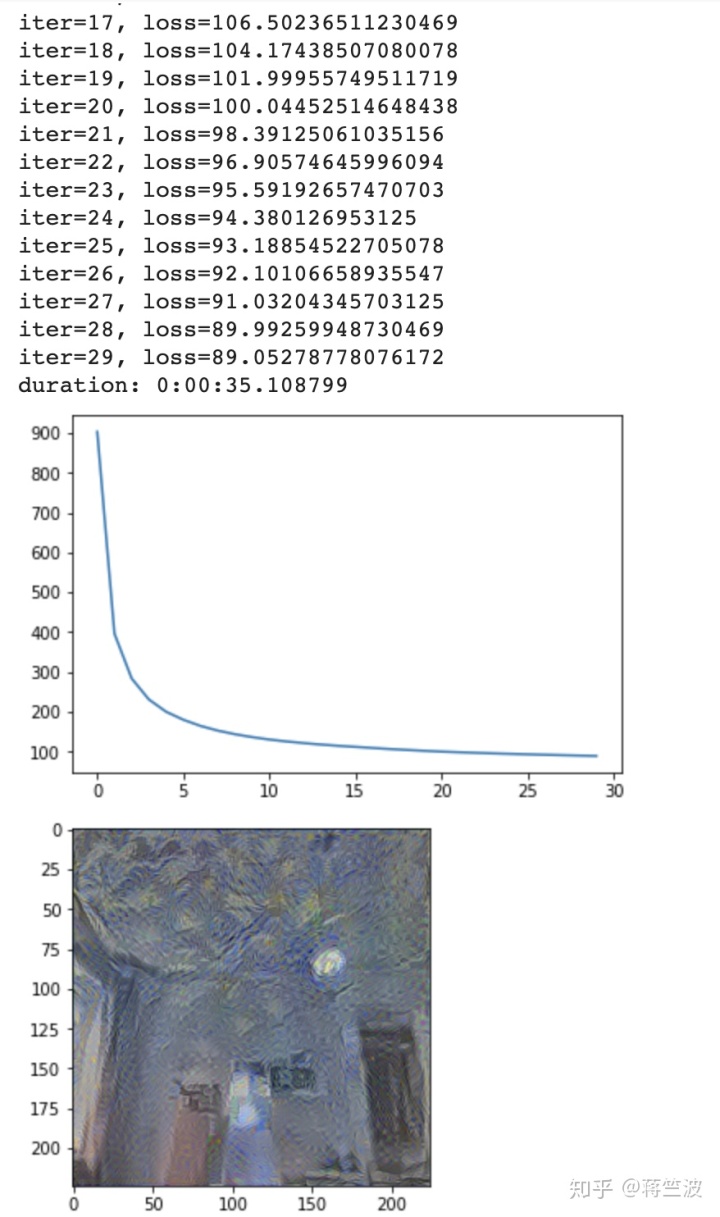
当然我们也可以使用设备相机尝试使用视频,并尝试在线模式(实时视频)中的样式传输,只需调整VideoCapture模式即可。
cap = cv2.VideoCapture(0)
cap.release()公众号回复:style, 获得可运行完整代码
随波竺流(Follow Bobo.AI)是由世界各地优秀的机器学习从业人员共同创立的AI交流公众号,我们将持续为大家带来从入门,提升到实践等一整套全面且新颖的AI知识!
转发分享,加入我们吧~

长按识别、扫码关注最新动态
公众号ID:follow_bobo















 611
611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









