





FCN论文链接:Fully Convolutional Networks for Semantic Segmentation
作者代码(caffe版):https://github.com/shelhamer/fcn.berkeleyvision.org
tensorflow版参考代码:https://github.com/MarvinTeichmann/tensorflow-fcn
一、什么是语义分割?

物体检测:如上左图,将物体在图片中用矩形框框出并分类。
语义分割(semantic segmentation):如上右图,对图片的每个像素进行分类,包括背景。
语义分割与实例分割的区别:语义分割只需要对每个像素进行归类。但是实例分割需要将同一类别的不同实例区分开,如自行车1,自行车2。
二、什么是FCN?
- 用卷积层替换全连接层
FCN(Fully Convolutional Networks )全卷积神经网络,是像素级分割算法的重要里程碑。FCN的第一个核心思想非常简单,用卷积层替换分类网络中的全连接层。

图二中上方的分类神经网络,通过最后三层全连接层,将神经元连接到类别数上。全卷积神经网络,将最后三层全连接层,全部替换为卷积层。假设总共有20个类别,全连接层最后输出的张量维度20,可以理解为1*1*20。其中1*1不能体现空间位置信息。如果换为卷积层,假设最后的输出张量维度假设为60*40*20,那么60*40则能保留一部分的空间信息。可以理解为vgg原本只能输出一个类别,但是全连接层替换为卷积层后的vgg,可以输出60*40个类别,并且包含了一定的空间信息,这是对图像每个像素点能够进行分类的前提。
在作者提供的代码中,分类框架使用vgg16为例,最后三个全连接层,改为卷积核尺寸分别为[7, 7, 512, 4096],[1, 1, 4096, 4096],[1, 1, 4096, 21]的卷积层。最后输出一张三维的feature map(前两维是feature map的宽、高)
- FCN怎么实现对每个像素分类?
FCN将全连接层替换为卷积层后,虽然feature map可以输出更多的类别信息,但也是原图下采样32倍后得到的,怎么为原图每个像素都输出一个类别标记?在文中作者提到使用转置卷积。
关于转置卷积的具体操作细节,以下内容来源于该回答:
怎样通俗易懂地解释反卷积?www.zhihu.com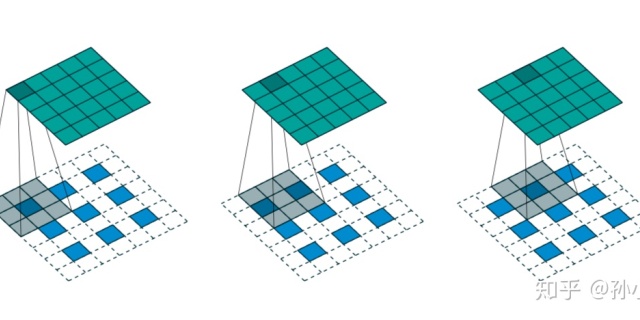
假设输入图像
卷积核
当stride为1,padding为0,可以算出经过卷积操作后输出张量尺寸为
全连接层可以用一个矩阵表示其运算,卷积层同样可以:
把
把输出图像
对于输入的元素矩阵
通过推导,我们可以得到稀疏矩阵
此时,输入
这里只关注维度的话,并不一定要求
这就实现了特征图低分辨率上采样至高分辨率。
由于上述推导清晰的说明了转置的过程,所以虽然在FCN文章中,作者使用反卷积(deconvolution )这个词,但是转置卷积并不能完全还原出原始数据,和信号处理中的反卷积有所区别,所以业界都称其为转置卷积。
另外啰嗦一句转置卷积核参数的初始化。如果对转置卷积核同样随机初始化参数,训练过程收敛慢,并且有可能不收敛。所以一般采用双线性插值对其参数进行初始化,这里的双线性插值,和知道四个位置的数值,对其他格点插值的算法有一定区别。例如下述代码,初始化尺寸为
import numpy as np
k_size = 5
factor = (k_size+1)//2
if k_size % 2 == 0:
center = factor - 0.5
else:
center = factor - 1
row, col = np.ogrid[:k_size, :k_size]
weights = (1 - abs(row - center)*1.0/factor) * (1 - abs(col - center)*1.0/factor)初始化后的weights:
array([[0.11111111, 0.22222222, 0.33333333, 0.22222222, 0.11111111],
[0.22222222, 0.44444444, 0.66666667, 0.44444444, 0.22222222],
[0.33333333, 0.66666667, 1. , 0.66666667, 0.33333333],
[0.22222222, 0.44444444, 0.66666667, 0.44444444, 0.22222222],
[0.11111111, 0.22222222, 0.33333333, 0.22222222, 0.11111111]])caffe中的初始化代码和此处有一定出入,只要是运用了双线性插值的思想初始化转置卷积核,都可以起到一定帮助收敛的效果。
- FCN网络结构
讲神经网络如果没有网络结构图,总感觉不清晰,以下先说说FCN-32的网络结构:
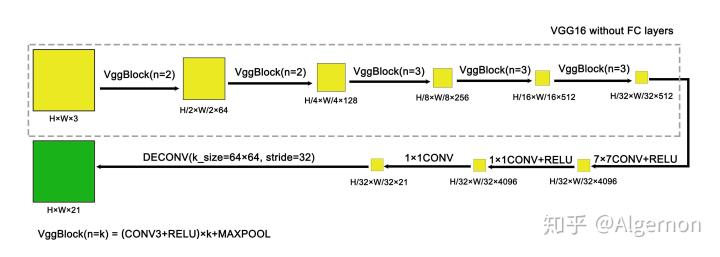
FCN-32s,不使用跨层连接,简单粗暴一条路走到头。图片进行下采样32倍后,直接使用64*64,步长为32的转置卷积层,将特征图放大至原图大小,channel变为21类别数(第21类为背景)。

FCN-8s先将32倍下采样后的特征图,使用4*4,步长为2的转置卷积放大至16倍下采样,与之前的16倍下采样特征图对位相加(之前下采样16倍特征图需要用1*1卷积将channel统一为21),再使用4*4,步长为2的转置卷积层放大至8倍下采样,同样与之前的8倍下采样图进行相加。最后经过16*16,步长为8的转置卷基层,将特征图放缩至原图大小。
FCN在设计时,对图片进行下采样32倍,再上采样32倍,所以输入图片的尺寸是任意的。
三、小结
FCN论文中同时也做了精度分析,这里不再赘述,因为FCN的精度远不如发展至今天的分割算法。FCN的意义在于,引入转置卷积,开创了像素级分割的鼻祖算法。
FCN不仅对图像进行分割,同时对每个点进行分类,引入条件随机场后,提升了分类的准确率。例如天空像素点的周围,鸟的概率要远大于鱼。
总结一下,FCN的意义在于:
1.不使用全连接层进行分类,而替换为卷积层,对空间进行分类。
2.使用转置卷积,实现了神经网络的上采样。
3.FCN可以融入其他现有的分类、检测算法框架中,可以共用特征提取的卷积层。例如,mask rcnn算法就是将FCN与检测算法faster rcnn合并。
4.跨层连接,类似于ResNet的思想,是启发式的。
欢迎指正。















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









