






原理分析:
图像、视觉中很多问题都涉及到将一副图像转换为另一幅图像(Image-to-Image Translation Problem),这些问题通常都使用特定的方法来解决,不存在一个通用的方法。但图像转换问题本质上其实就是像素到像素的映射问题。本文根据cGAN提出可以用于Image-to-Image Translation中多个任务的通用框架。 任务主要包括:从标签图合成相片,从线稿图重构对象,给图片上色等。
cGAN结构:
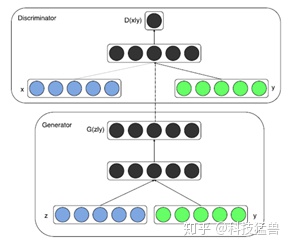

本文工作介绍:
本文主要在三个部分改进了cGAN, 包括目标函数,生成器的网络结构和判别器的判别方式。
1. 对目标函数的修改
由之前的:
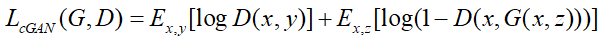
再加上这一项:
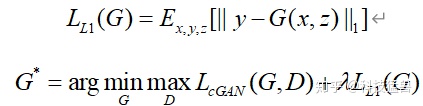
加入了
2. 在生成器中,用U-net结构代替encoder-decoder
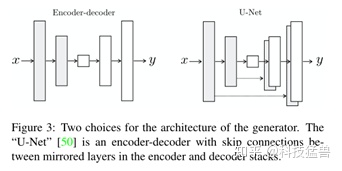
在Image-to-Image Translation的大多任务中,图像的底层特征同样重要,所以利用U-net代替encoder-decoder。
在输入和输出之间存在很多可以共享的低级信息,在网络中直接传递这些信息可能会有所帮助。为了使生成器避开这样的信息瓶颈问题,我们模仿“U-Net”增加了跳线连接。特别的,我们在每第i层和第n−i层之间添加跳线,其中n是网络的总层数。每根跳线简单的将第i层和第n−i层的特征通道连接在一起。
3.提出PatchGAN
通常判断都是对生成样本整体进行判断,比如对一张图片来说,就是直接看整张照片是否真实。而且Image-to-Image Translation中很多评价是像素对像素的,所以在这里提出了分块判断的算法,在图像的每个块上去判断是否为真,最终平均给出结果。
PatchGAN的差别主要是在于Discriminator上,一般的GAN是只需要输出一个true or fasle 的矢量,这是代表对整张图像的评价;但是PatchGAN输出的是一个N x N的矩阵,这个N x N的矩阵的每一个元素,比如a(i,j) 只有True or False 这两个选择(label 是 N x N的矩阵,每一个元素是True 或者 False),这样的结果往往是通过卷积层来达到的,因为逐次叠加的卷积层最终输出的这个N x N 的矩阵,其中的每一个元素,实际上代表着原图中的一个比较大的感受野,也就是说对应着原图中的一个Patch,因此具有这样结构以及这样输出的GAN被称之为Patch GAN。
这么设计的原因是依靠L1项来保证低频的准确性。为了对高频信息建模,关注对局部图像块(patches)就已经足够了。
4.优化和推理
为了优化网络,作者使用标准的方法:交替训练D和G。我们使用minibatch SGD并应用Adam优化器。
在推理的时候,作者用训练阶段相同的方式来运行生成器。在测试阶段使用dropout和batch normalization。这种方法下,当batch size设为1的时候,就是instance normalization,对于图像生成任务很有效。在我们的实验中,一些实验使用1的batch size,其他的使用4,发现在这两种情况下差异很小。
Experiments:
为了研究条件GANs的通用性,我们在各种任务和数据集上测试了该方法,包括图形学任务(比如相片生成)和视觉任务(比如语义分割):

评价指标:
这篇论文的evaluation metrics来自pix2pix的paper。传统的per-pixel mean-squared error无法评估结构性损失,所以无法准确地评价visual quality。于是作者采用以下的指标:
1. AMT perceptual studies
这个指标是基于Amazon Mechanical Turk (AMT)这个平台来评估实验结果的。把一张真图和一张假图称为“1个pair”,先给25个参与者每个人练习10个pair,告诉他们结果。具体的练习方法是每张图片展示1秒,之后参与者回答哪个图片是假图。再测试40个pair,以评估哪个算法能更好地欺骗受试者。
2. FCN score
这个指标是针对cityspace数据集,任务具体是把labels转换为photos,如下图所示。

这个指标背后的思想是:如果生成的图像是真实的,那么训练在真实图像上的分类器也能够正确地对合成图像进行分类。为此,我们采用流行的FCN-8s[39]结构进行语义分割。
把生成的图片通过FCN,FCN预测generated photo的labels。然后,可以使用语义分割的metrics将该标签映射与输入地面真值标签进行比较。FCN具体使用的是FCN-8s,在cityspaces数据集上进行训练。
目标函数影响:

当只用
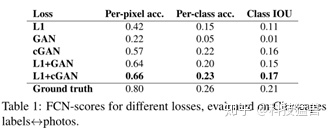
FCN-scores 越高,表示图片中有更多可辨认的物体。作者同样尝试了去掉cGAN的条件,就相当于不去判断这个图片是否与输入图片相似,只需要关注图片是否像真实照片,但是这样的效果并不好。
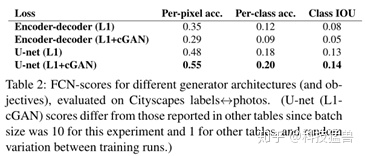
Generator结构影响:

这里作者探索了G的结构使用U-net与encoder-decoder时的影响,对于不同的损失函数,U-net架构会带来不一样的效果。
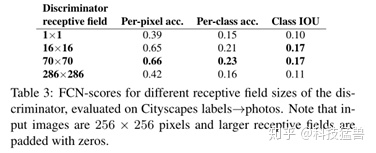
Discriminator结构影响:
我们测试了判别器接收域使用不同patch size N的效果:从1x1的“PixelGANs”到整张图像256x256的“ImageGANs”。上图图呈现了定性结果,上表呈现了FCN分数的定量结果。请注意本文其他地方,如果没有特别指明,均使用的是70x70的“PatchGANs”,本节所有实验都使用L1+cGAN的loss。
PixelGAN对于空间清晰度没有帮助,但是提升了结果的色彩效果。比如图中的巴士,在L1 loss下是灰色的,在PixelGAN下变成了橘红色。颜色直方图匹配在图像处理中一个很常见的问题,PixelGANs或许能成为一个解决方法。
使用16x16的PathGAN进一步提升了输出的清晰度,但是出现了一些不自然的纹理。70x70则减轻了这种效果。如果进一步提高N,使用256x256并没有提升效果,实际上FCN得分还下降了。这也许是因为ImageGAN相比70x70的patch拥有更多的参数和更深的深度,导致难以训练。

代码解读:
1.models.py:
模块定义:
import torch.nn as nn
import torch.nn.functional as F
import torch
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
##############################
# U-NET
##############################
class UNetDown(nn.Module):
def __init__(self, in_size, out_size, normalize=True, dropout=0.0):
super(UNetDown, self).__init__()
layers = [nn.Conv2d(in_size, out_size, 4, 2, 1, bias=False)]
if normalize:
layers.append(nn.InstanceNorm2d(out_size))
layers.append(nn.LeakyReLU(0.2))
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class UNetUp(nn.Module):
def __init__(self, in_size, out_size, dropout=0.0):
super(UNetUp, self).__init__()
layers = [
nn.ConvTranspose2d(in_size, out_size, 4, 2, 1, bias=False),
nn.InstanceNorm2d(out_size),
nn.ReLU(inplace=True),
]
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x, skip_input):
x = self.model(x)
x = torch.cat((x, skip_input), 1)
return x模型定义:
class GeneratorUNet(nn.Module):
def __init__(self, in_channels=3, out_channels=3):
super(GeneratorUNet, self).__init__()
self.down1 = UNetDown(in_channels, 64, normalize=False)
self.down2 = UNetDown(64, 128)
self.down3 = UNetDown(128, 256)
self.down4 = UNetDown(256, 512, dropout=0.5)
self.down5 = UNetDown(512, 512, dropout=0.5)
self.down6 = UNetDown(512, 512, dropout=0.5)
self.down7 = UNetDown(512, 512, dropout=0.5)
self.down8 = UNetDown(512, 512, normalize=False, dropout=0.5)
self.up1 = UNetUp(512, 512, dropout=0.5)
self.up2 = UNetUp(1024, 512, dropout=0.5)
self.up3 = UNetUp(1024, 512, dropout=0.5)
self.up4 = UNetUp(1024, 512, dropout=0.5)
self.up5 = UNetUp(1024, 256)
self.up6 = UNetUp(512, 128)
self.up7 = UNetUp(256, 64)
self.final = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(128, out_channels, 4, padding=1),
nn.Tanh(),
)
def forward(self, x):
# U-Net generator with skip connections from encoder to decoder
d1 = self.down1(x)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
d6 = self.down6(d5)
d7 = self.down7(d6)
d8 = self.down8(d7)
u1 = self.up1(d8, d7)
u2 = self.up2(u1, d6)
u3 = self.up3(u2, d5)
u4 = self.up4(u3, d4)
u5 = self.up5(u4, d3)
u6 = self.up6(u5, d2)
u7 = self.up7(u6, d1)
return self.final(u7)
##############################
# Discriminator
##############################
class Discriminator(nn.Module):
def __init__(self, in_channels=3):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, normalization=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalization:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(in_channels * 2, 64, normalization=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1, bias=False)
)
def forward(self, img_A, img_B):
# Concatenate image and condition image by channels to produce input
img_input = torch.cat((img_A, img_B), 1)
return self.model(img_input)2.datasets.py:
import glob
import random
import os
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, mode="train"):
self.transform = transforms.Compose(transforms_)
self.files = sorted(glob.glob(os.path.join(root, mode) + "/*.*"))
if mode == "train":
self.files.extend(sorted(glob.glob(os.path.join(root, "test") + "/*.*")))
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
w, h = img.size
img_A = img.crop((0, 0, w / 2, h))
img_B = img.crop((w / 2, 0, w, h))
if np.random.random() < 0.5:
img_A = Image.fromarray(np.array(img_A)[:, ::-1, :], "RGB")
img_B = Image.fromarray(np.array(img_B)[:, ::-1, :], "RGB")
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {"A": img_A, "B": img_B}
def __len__(self):
return len(self.files)3.pix2pix.py:
导入必要的库:
import argparse
import os
import numpy as np
import math
import itertools
import time
import datetime
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from models import *
from datasets import *
import torch.nn as nn
import torch.nn.functional as F
import torch
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="facades", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_height", type=int, default=256, help="size of image height")
parser.add_argument("--img_width", type=int, default=256, help="size of image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument(
"--sample_interval", type=int, default=500, help="interval between sampling of images from generators"
)
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between model checkpoints")
opt = parser.parse_args()
print(opt)
os.makedirs("images/%s" % opt.dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % opt.dataset_name, exist_ok=True)
cuda = True if torch.cuda.is_available() else False损失函数与初始化:
# Loss functions
criterion_GAN = torch.nn.MSELoss()
criterion_pixelwise = torch.nn.L1Loss()
# Loss weight of L1 pixel-wise loss between translated image and real image
lambda_pixel = 100
# Calculate output of image discriminator (PatchGAN)
patch = (1, opt.img_height // 2 ** 4, opt.img_width // 2 ** 4)
# Initialize generator and discriminator
generator = GeneratorUNet()
discriminator = Discriminator()
if cuda:
generator = generator.cuda()
discriminator = discriminator.cuda()
criterion_GAN.cuda()
criterion_pixelwise.cuda()需要注意的是这个patch
patch = (1, opt.img_height // 2 ** 4, opt.img_width // 2 ** 4)
你仔细一算,图片是(256,256)的,这里的patch为(16,16),与Discriminator输出的维度相符。
导入参数值:
if opt.epoch != 0:
# Load pretrained models
generator.load_state_dict(torch.load("saved_models/%s/generator_%d.pth" % (opt.dataset_name, opt.epoch)))
discriminator.load_state_dict(torch.load("saved_models/%s/discriminator_%d.pth" % (opt.dataset_name, opt.epoch)))
else:
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)定义优化器与图片预处理:
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# Configure dataloaders
transforms_ = [
transforms.Resize((opt.img_height, opt.img_width), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]导入数据:
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
val_dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, mode="val"),
batch_size=10,
shuffle=True,
num_workers=1,
)
# Tensor type
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def sample_images(batches_done):
"""Saves a generated sample from the validation set"""
imgs = next(iter(val_dataloader))
real_A = Variable(imgs["B"].type(Tensor))
real_B = Variable(imgs["A"].type(Tensor))
fake_B = generator(real_A)
img_sample = torch.cat((real_A.data, fake_B.data, real_B.data), -2)
save_image(img_sample, "images/%s/%s.png" % (opt.dataset_name, batches_done), nrow=5, normalize=True)
训练和保存模型:
prev_time = time.time()
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# Model inputs
real_A = Variable(batch["B"].type(Tensor))
real_B = Variable(batch["A"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((real_A.size(0), *patch))), requires_grad=False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *patch))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
optimizer_G.zero_grad()
# GAN loss
fake_B = generator(real_A)
pred_fake = discriminator(fake_B, real_A)
loss_GAN = criterion_GAN(pred_fake, valid)
# Pixel-wise loss
loss_pixel = criterion_pixelwise(fake_B, real_B)
# Total loss
loss_G = loss_GAN + lambda_pixel * loss_pixel
loss_G.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Real loss
pred_real = discriminator(real_B, real_A)
loss_real = criterion_GAN(pred_real, valid)
# Fake loss
pred_fake = discriminator(fake_B.detach(), real_A)
loss_fake = criterion_GAN(pred_fake, fake)
# Total loss
loss_D = 0.5 * (loss_real + loss_fake)
loss_D.backward()
optimizer_D.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, pixel: %f, adv: %f] ETA: %s"
% (
epoch,
opt.n_epochs,
i,
len(dataloader),
loss_D.item(),
loss_G.item(),
loss_pixel.item(),
loss_GAN.item(),
time_left,
)
)
# If at sample interval save image
if batches_done % opt.sample_interval == 0:
sample_images(batches_done)
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(generator.state_dict(), "saved_models/%s/generator_%d.pth" % (opt.dataset_name, epoch))
torch.save(discriminator.state_dict(), "saved_models/%s/discriminator_%d.pth" % (opt.dataset_name, epoch))需要注意的是这2句话: # Adversarial ground truths
valid = Variable(Tensor(np.ones((real_A.size(0), *patch))), requires_grad= False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *patch))), requires_grad= False)
你会发现valid和fake的size都是(nunber of images,17,17)的。
而pred_fake为D的输出,也是这个size,所以可以求loss。















 898
898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









