





一、数据准备
二、数据清洗
1、缺失值处理
2、异常值
三、EDA
1、发表文章数量最多的作者
2、发表时间统计
3、发表单位统计
4、文献来源统计
5、关键词统计
四、共现网络
五、K-means聚类
六、数据降维,可视化结果
七、数据集+源码获取
作为八月份的第一篇文章,这次我们分享一个最近做的案例,分析知网的学者数据信息,不多咕咕咕,我们一步一步开始分析

一、数据准备
这次主要是通过知网获取的学者信息,进行一个学者画像的分析。一共是从知网下载了三份数据。如下图所示。  每份数据的格式都是一样的。包含
每份数据的格式都是一样的。包含 'SrcDatabase-来源库','Title-题名','Author-作者','Organ-单位','Source-文献来源','Keyword-关键词','Summary-摘要','PubTime-发表时间'八个字段。因此我们可以将这三份数据合并到一个DataFrame中,再进行后续的数据清洗。代码如下。
import pandas as pdimport numpy as npimport osimport matplotlib.pyplot as pltplt.style.use('seaborn')base='./datasets/'datasets=os.listdir(base)print(datasets)dfs=[]for dataset in datasets: df=pd.read_excel(os.path.join(base,dataset),encoding='gbk') dfs.append(df)df=pd.concat(dfs)df.head()二、数据清洗
1、缺失值处理
观察上述合并后的数据,可以看到第一列数据是不需要的。其次,部分列的数据存在缺失值,对于存在缺失值的元素,这里直接删除对应行即可。
2、异常值
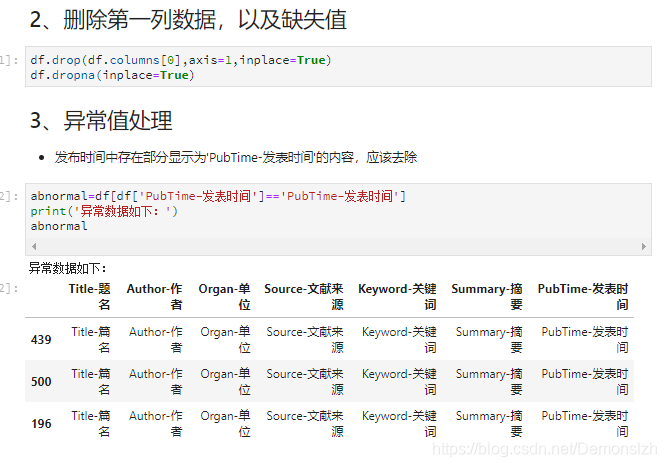
这里的异常值主要是部列中的值为标题名称。这里做个筛选,同样删除这些数据即可。
三、EDA
数据清洗完毕后接着进行数据探索。可以看到数据集中的各列数据均有挖掘价值。将相关内容可视化化出来。
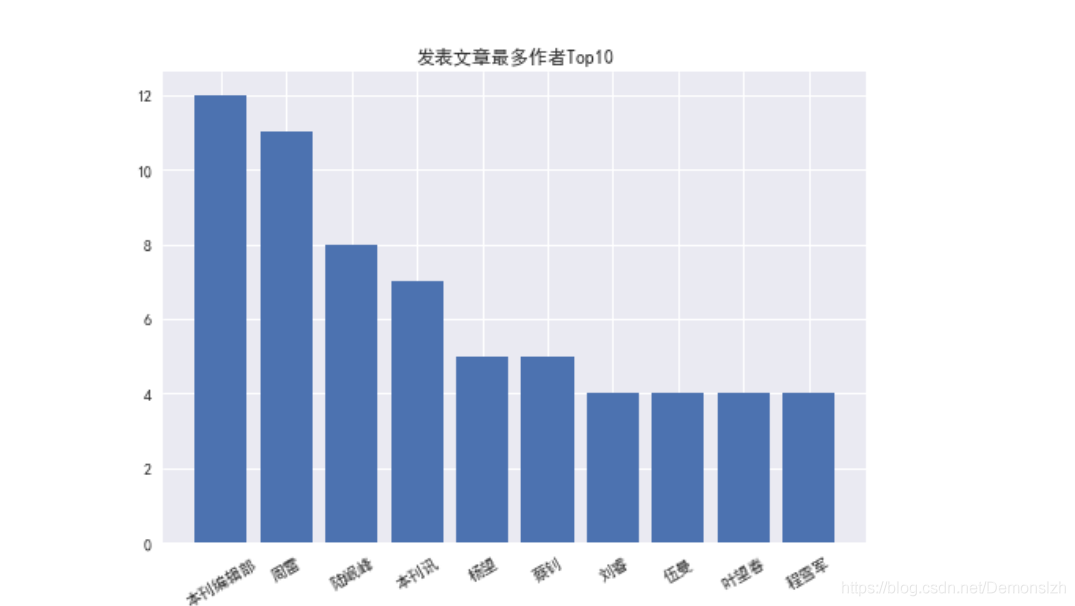
1、发表文章数量最多的作者
从数据列可以发现,有的文章为多名作者合作完成,因此需要做一个简单的拆分
keywords={}exponet=[]#每篇文章各个关键词出现次数之和,排序依据for keys in df['Author-作者']: key_list=keys.split(';') for key in key_list: if key=='': continue if key in keywords: keywords[key]+=1 else: keywords[key]=1keywords=dict(sorted(keywords.items(),key=lambda x:x[1],reverse=True)[:10])plt.title('发表文章最多作者Top10')plt.bar(keywords.keys(),keywords.values())plt.xticks(rotation=30)#排序DataFramefor keys in df['Author-作者']: score=0 for key in keys.split(';'): try: score+=keywords[key] except: pass exponet.append(score)df['数量']=exponetdf=df.sort_values(by='数量',ascending=False)print("根据作着排序结果如下:")df.head()
2、发表时间统计
这里我们统计每年总共发表的文章数量
dates=pd.to_datetime(df['PubTime-发表时间'])year_num=dates.map(lambda x:x.year).value_counts()year_num.index=year_num.index.sort_values(ascending=False)year_num.plot()plt.xlabel('年份')plt.ylabel('文章累计数')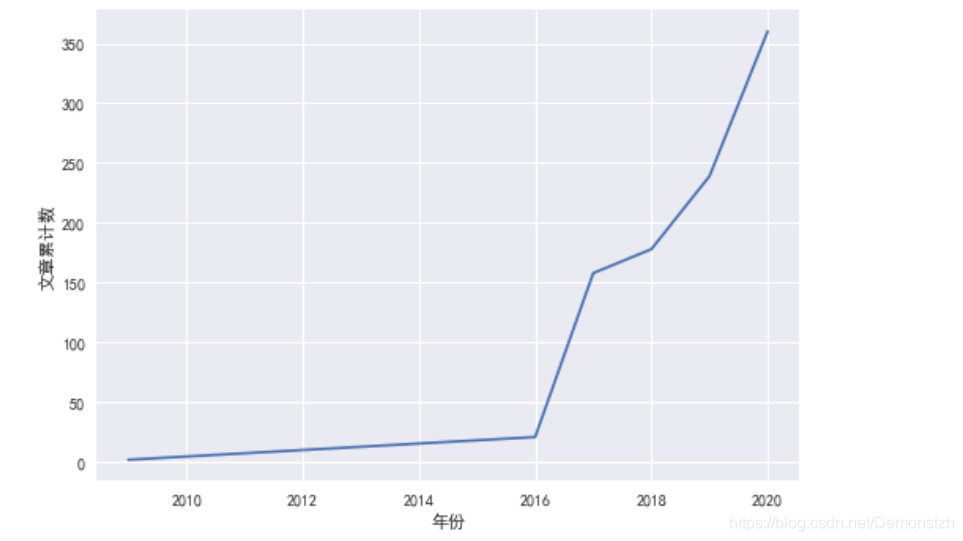
3、发表单位统计
接着统计各个单位发表数量的Top10
organ=df['Organ-单位'].value_counts()organ[:10].plot(kind='bar',title='单位发表数量top10')df['数量']=[organ[i] for i in df['Organ-单位'] ]df=df.sort_values(by='数量',ascending=False)print("根据单位排序结果如下:")df.head()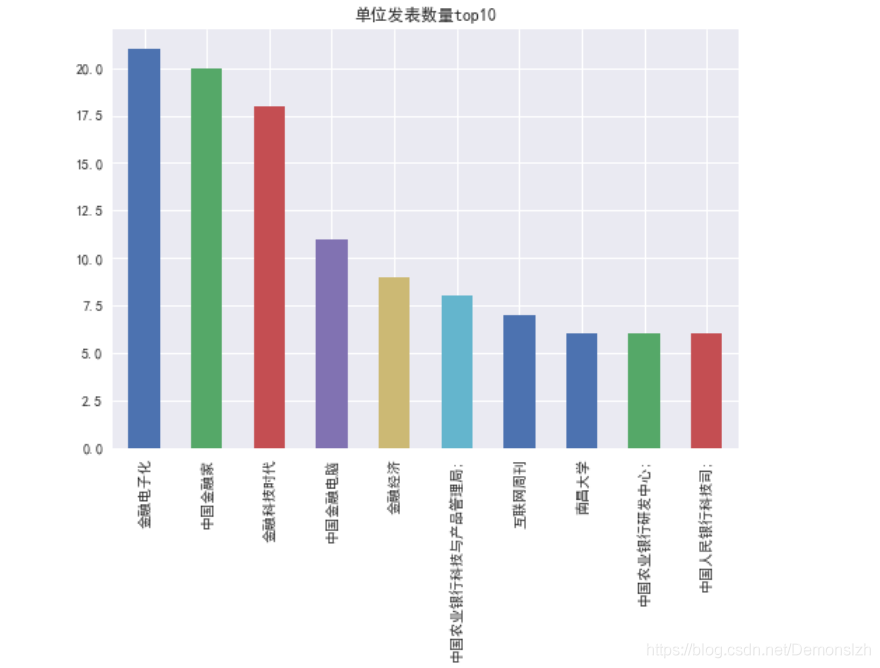
4、文献来源统计
Source=df['Source-文献来源'].value_counts()Source[:10].plot(kind='bar',title='文献来源数量top10')df['数量']=[Source[i] for i in df['Source-文献来源'] ]df=df.sort_values(by='数量',ascending=False)print("根据单位排序结果如下:")df.head()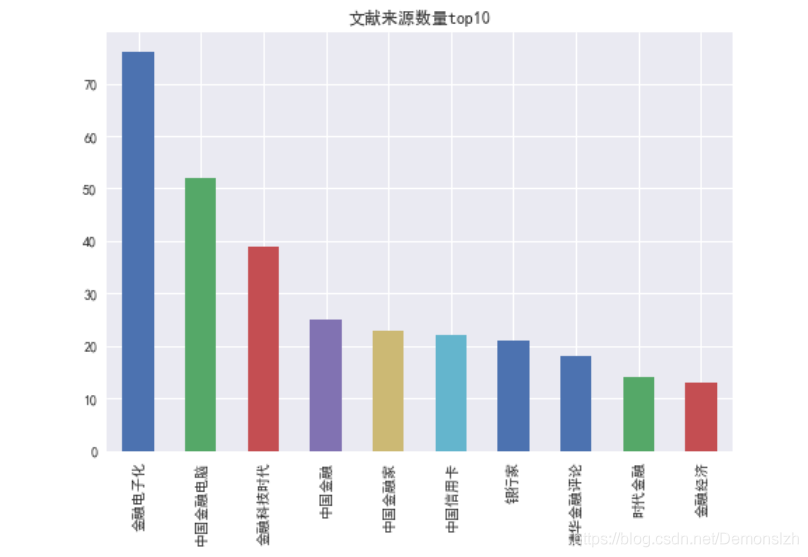
5、关键词统计
关键词统计的方法与1中的作者发表文章数量的统计方法类似。这里我们统计前15个关键词
keywords={}exponet=[]#每篇文章各个关键词出现次数之和,排序依据for keys in df['Keyword-关键词']: key_list=keys.split(';') for key in key_list: if key=='': continue if key in keywords: keywords[key]+=1 else: keywords[key]=1keywords=dict(sorted(keywords.items(),key=lambda x:x[1],reverse=True)[:10])plt.title('关键词Top10')plt.bar(keywords.keys(),keywords.values())plt.xticks(rotation=30)#排序DataFramefor keys in df['Keyword-关键词']: score=0 for key in keys.split(';'): try: score+=keywords[key] except: pass exponet.append(score)df['数量']=exponetdf=df.sort_values(by='数量',ascending=False)print("根据关键词排序结果如下:")df.head()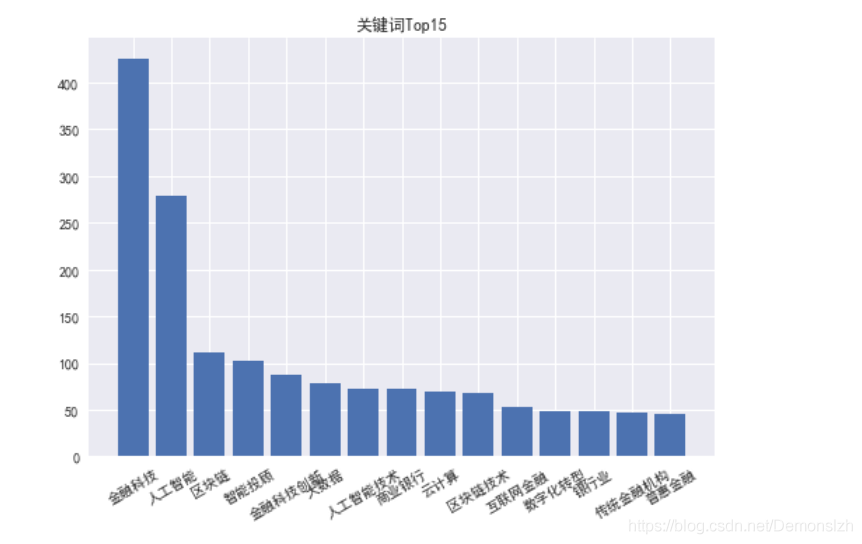
四、共现网络
构建作者与作者之间的合作网络。那么这个思路主要如下。
首先是将所有作者提取出来,这个在之前数据探索的过程中已经实现。将作者名作为行与列构建一个新的矩阵。
authors=[]ketwords={}for keys in df['Author-作者']: key_list=keys.split(';') for key in key_list: if key=='': continue if key in keywords: keywords[key]+=1 else: keywords[key]=1 if key not in authors: authors.append(key)l=len(authors)arr=np.zeros((l,l))co_author_arr=pd.DataFrame(arr,index=authors,columns=authors)co_author_arr.head() 对于上述的Dataframe我们将他当作一个二维数组,那么: 当作者i与作者j在同一条记录出现时,
对于上述的Dataframe我们将他当作一个二维数组,那么: 当作者i与作者j在同一条记录出现时, co_author_arr[i][j]+=1,然后将同一个关系合并 co_author_arr[i][j]+=co_author_arr[j][i]。最后形成我们最终的结果。如果用Python的基本循环语法去遍历这个数据会是一个很漫长的过程。所以我们通过Pandas内置的迭代对象进行遍历。
leg=len(authors)count=0for index,row in co_author_arr.iterrows(): for name in row.index: if name!=index: row[name]+=1 row[name]+=co_author_arr.loc[name,index] count+=1 print('\r{}%'.format(count/leg*100),end='')co_author_arr.head()最后结果如下 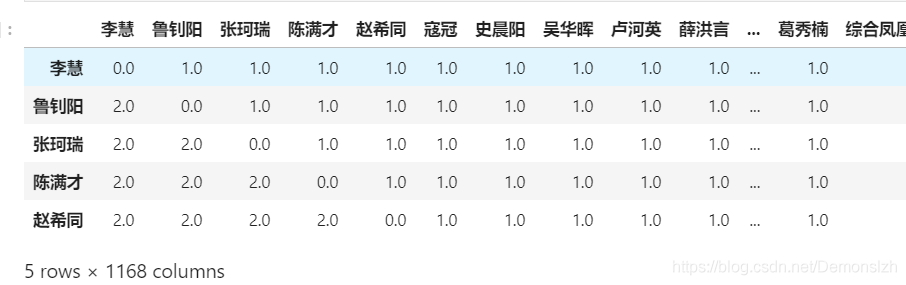
五、K-means聚类
由于每篇文章都包含多个不同的主题,我们为了能更合理地归类这些文章,可以将这些文章进行聚类。将所有唯一的关键词作为行,所有文章标题作为列构建一个新的DataFrame,所有元素初始化为0。如果当前文章包括某个关键词,则将该元素的值置为1。
建立聚类表格
keywords=[]for keys in df['Keyword-关键词']: key_list=keys.split(';') for key in key_list: if key=='': continue if key not in keywords: keywords.append(key) title=df['Title-题名']arr=np.zeros((len(title),len(keywords)))tit_key=pd.DataFrame(arr,index=title,columns=keywords)tit_key.head()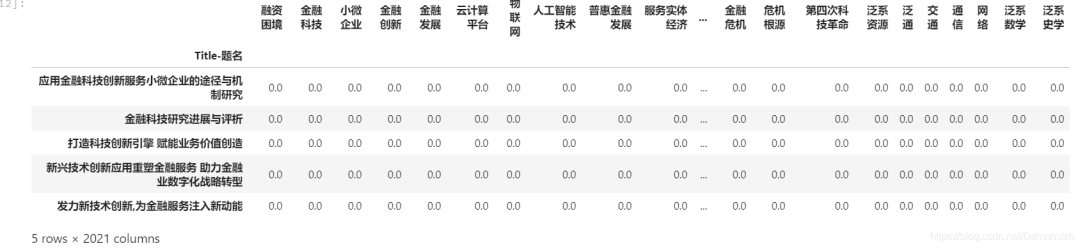
计算结果
df=df.set_index('Title-题名')for index,row in tit_key.iterrows(): kw=df.loc[index,'Keyword-关键词'] try: keys=kw.split(';') for k in keys: if k in keywords: row[k]=1 except: passtit_key.head() 
为了选取最优的簇数,我们通过不同的评估系数(CH指标、轮廓系数指标、SSE簇内误方差指标)进行评估,根据可视化的结果选取最佳的K值
from sklearn.cluster import KMeans from sklearn.metrics import silhouette_scorefrom sklearn.metrics import calinski_harabaz_score#三种评价指标silhouettteScore = []CH_score=[]SSE=[]for i in range(2,30): ##构建并训练模型 print('\r正在构建模型:{}%'.format((i-1)/28*100),end='') kmeans = KMeans(n_clusters = i,random_state=123).fit(tit_key) score = silhouette_score(tit_key,kmeans.labels_) ch=calinski_harabaz_score(tit_key,kmeans.labels_) silhouettteScore.append(score) CH_score.append(ch) SSE.append(kmeans.inertia_) def plot_one(scores,title): plt.figure(figsize=(10,6)) plt.plot(range(2,30),scores,linewidth=1.5, linestyle="-") plt.title(title)plot_one(silhouettteScore,'轮廓系数')plot_one(CH_score,'CH')plot_one(SSE,'SSE')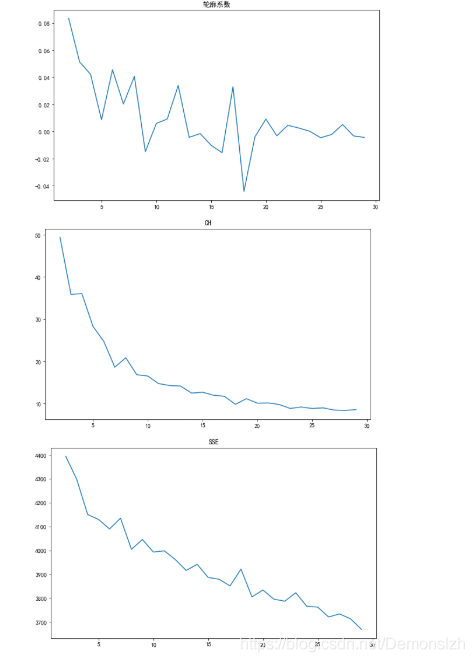 通过上图,我们选择K=16作为聚类的簇数
通过上图,我们选择K=16作为聚类的簇数
六、数据降维,可视化结果
from sklearn.manifold import TSNEkmeans=KMeans(n_clusters=16,random_state=123).fit(tit_key) #构建并训练模型tsne = TSNE(n_components=2,init='random',random_state=177).fit(tit_key)result=pd.DataFrame(tsne.embedding_) ##将原始数据转换为DataFrameresult['labels'] = kmeans.labels_ ##将聚类结果存储进df数据表 # ## 绘制图形plt.figure(figsize=(12,10))for i in range(17): temp=result[result['labels']==i] plt.scatter(temp[0],temp[1])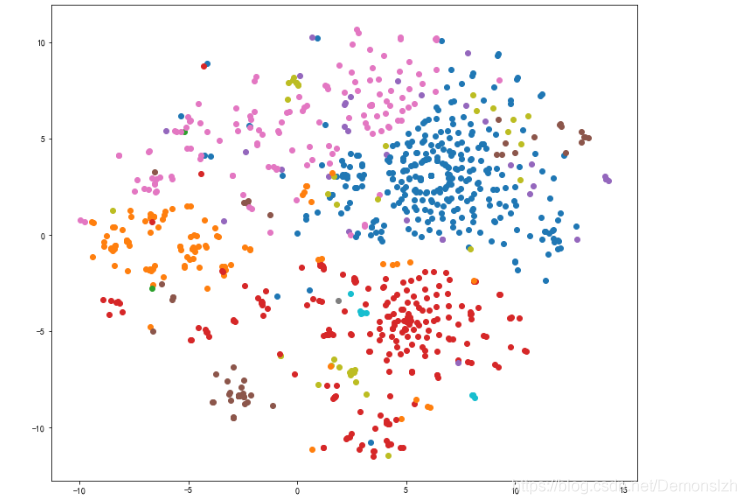
七、数据集+源码获取
关注以下公众号,回复 0020即可获取下载链接 















 6443
6443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









