






讲解之前我们先了解一些基本概念,什么是字符集?字符集就像一张表,这个表里面有很多的符号,每个符号都可以通过下标(这个符号在表的中的序号)对应到,有点类似js中的map,例如97这个下标代表的就是符号a。当然,字符集是有很多种,最常见的就是ASCII字符集了,还有中文的GB2312字符集,每个字符集其实就是一张表,上面有各种符号,然后通过下标和它们对应。当然,最全的,包含所有符号的字符集是Unicode,今天讲的字符都是基于Unicode字符集的。
有了字符集,我们就可以利用下标去对应符号了,但是一个字符集中有很多的字符,这样有些下标就会很长了,如14324,17423等,因此要对这些下标进行编码来节省空间,编码方式有utf-8,utf-16和Unicode编码等。
在js中,最常见的就是Unicode编码了(注意:Unicode字符集和Unicode编码是两个不同的概念),第一种情况,它以\x开头,后面加上两个十六进制表示单字节字符,如'\x61'表示的就是字符a,怎么来的呢,因为十六进制的61代表十进制的97,而97下标代表的就是a符号;第二种情况,它以\u开头,后面加4个十六进制表示一个字符,例如'\u0061',这个表示的也是字符a,和\x不同,\u每次利用两个字节表示一个字符(一个字节表示可以表示两个十六进制),\x则使用一个字节,因此\x只能表示255个符号,而\u可以表示65535个字符。
因此有的时候我们会遇到如何识别单字节和双字节的问题,我们就可以利用\x或者\u来判断:
/*测试是否是单字节*/
/[\u0000-\u00ff]/g.test(str);
/[\x00-\xff]/g.test(str);
/*测试是否是双字节*/
/[\u0100-\uffff]/g.test(str)
测试是否是单/双字节,主要看字符的序号是否大于255,如果大于255,那么一个字节就存不下了,因为一个字节8位,最多放序号位255的字符。
当然,在js中,除了Unicode编码,还有一种八进制的转义字符,如'\141'表示的也是字符a,注意,和上面不同,这里用的是八进制,因为141的八进制代表的是十进制的97,所以取的是下标为97的符号。需要注意的是,它只能表示255个符号,最大为'\377',同时注意例如'\128'表示的是两个字符,第一个为八进制转移字符:'\12',另一位为'8',因为八进制里面最大的是7,没有8。
除了在js中存在这种编码方式,在html和css中也是存在的。在html中,+十进制+;可以表示一个符号,例如a表示的就是符号a,或者+十六进制+;也可以表示,如a表示的也是a,只不过一个用的是下标的十进制一个是十六进制。注意,因为html的这种隐藏编码方式,会导致我们有的时候踩到坑, &符号的分割拼接陷阱
在css中,主要是提现在伪元素后面的content中,例如:
#a:after{
content:'\61'
}
这里的content其实是符号a,在css里中,\后面加上下标的十六进制即可表示这个字符。
为了方便大家如何查编码,进制转换,总结了一些常用的获取以及转换的方法:
/*符号和下标转换*/
'a'.charCodeAt(0);//获取符号的下标数字
String.fromCharCode(97);///通过下标,找到这个字符
/*十进制变其他进制*/
97 .toString(16);//十进制变成十六进制
97 .toString(8);//十进制变成八进制
97 .toString(2);//十进制变成二进制
/*其他进制变十进制*/
parseInt(61,16);//十六进制变十进制
parseInt(141,8);//八进制变十进制
parseInt(1100001,2);//二进制变十进制
上面讲了字符中的一些基本知识,在字符集中还有两个特殊的东西,一个是中文,一个是emoji。
中文在Unicode字符集中的分布比较广泛:
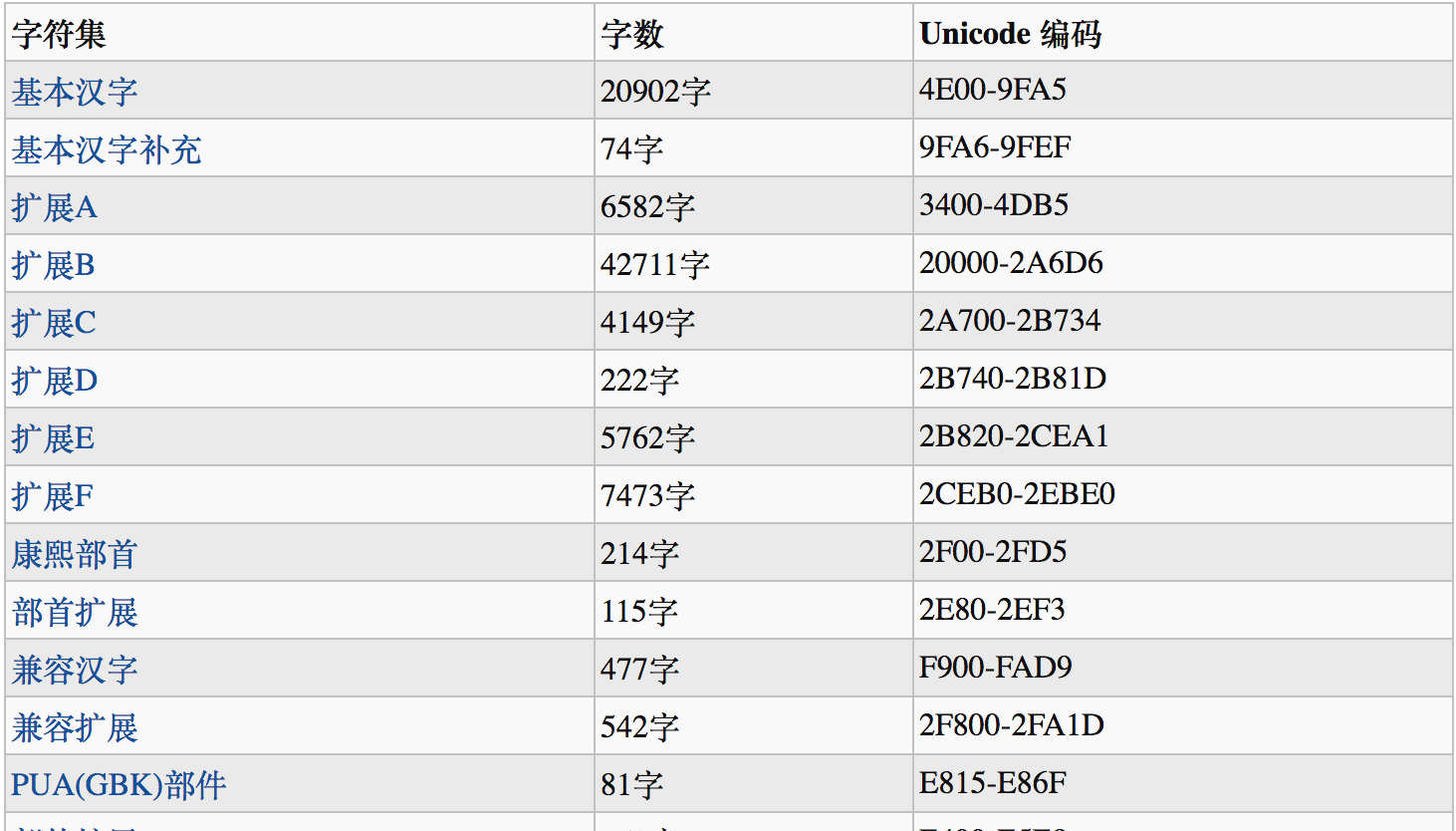
上图只是一部分分布,但是主要的中文集中在\u4e00-\u9fa5之间,因此有的时候会遇到验证是否存在中文:
[\u4e00-\u9fa5]/g.test(str);
注意啊,上面只是验证绝大多数的中文,不是完整的验证,例如中文中的"𠮷"就无法通过,因为它的下标不在这个范围之内。
emoji就是Unicode字符表中的表情,这玩意的在Unicode字符表中很靠后的位置,下标排在65535之后,这回导致一个什么问题呢?上面我们说到在js中,可以用\u加上十六进制表示字符,但是这个最大只能表示\uFFFF,也就是下标为65535的字符,无法表示更大的字符,因此,在这个时候,就需要用两个\u来表示了,例如😂,它就是用'\uD83D\uDE02'表示的。
因此一个emoji需要4个字节(一个中文需要两个字节),我们平常用的String.charCodeAt(0)就无法获取它的正确下标了,例如'😂'.charCodeAt(0)就是55357,它获取的是第一个\u的十进制,因此获取emoji的正确下标需要用codePointAt方法,'😂'.codePointAt(0)为128514。(恢复用String.fromCodePoint方法),那平常我们也会遇到验证emoji,代码如下:
/\ud83c[\udf00-\udfff]|\ud83d[\udc00-\ude4f]|\ud83d[\ude80-\udeff]/g.test('😂');
现在来讲讲utf-8编码,utf-8编码也是用来编码下标的,它先计算出下标的二进制,然后根据它的长度把它们塞到一个特殊序列的二进制中:
1字节 0xxxxxxx (0-127)
2字节 110xxxxx 10xxxxxx (128-2047)
3字节 1110xxxx 10xxxxxx 10xxxxxx (2048-65535)
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx (65536-1114111)
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
什么意思呢?假如汉字'我',下标为25105,在范围2048-65535之内,因此我们要把25105的二进制拆分成三部分(4-6-6):0110 001000 010001,然后在第一部分前面加1110,第一部分变成11100110,第二部分前面加10,第二部分变成10001000,第三部分前面加10,第三部分变成10010001,因此小标25105被编码成了三个字节,分别是11100110 10001000 10010001,转成十六进制也就是e6 88 91。但是注意,这里的e6 88 91我们是不能用\u去用的,因为\u是Unicode编码,因此你写\ue68891是无法识别的。
那utf-8在js的什么地方有用到呢?在encodeURI或者encodeURIComponent的时候用到,例如我们encodeURI(‘我'),那么结果为%E6%88%91,其中的三个十六进制就是我们刚刚计算出来的那三个。与之类似的有一个escape方法,我们escape('我')发现是%u6211,这个其实就是%u+字符的十六进制,和\u6211这个类似。
但是我们可以发现encodeURI或者encodeURIComponent在进行utf-8编码的时候其实是将二进制变成了十六进制,这样其实结果会变长3倍,'我'这个汉字在encodeURI或者encodeURIComponent编码后变成了%E6%88%91,变成了9个字符,其实正常只会变成三个字符(下标为230,136,145的字符),虽然这些字符可能肉眼看不到,但是它们也是确实的字符。因此,在某些情况下,我们还是希望有一个将字符进行utf-8编码/解码的方法,下面就是我写的utf-8编码/解码的js方法
var UTF8 = {
encode: function(str) {
var rs = '';
for(var i of str) {
var code = i.codePointAt(0);
if(code < 128) {
rs += i;
} else if(code > 127 && code < 2048) {
rs += String.fromCharCode((code >> 6) | 192, (code & 63) | 128);
} else if(code > 2047 && code < 65536) {
rs += String.fromCharCode((code >> 12) | 224, ((code >> 6) & 63) | 128, (code & 63) | 128);
} else if(code > 65536 && code < 1114112) {
rs += String.fromCharCode((code >> 18) | 240, ((code >> 12) & 63) | 128, ((code >> 6) & 63) | 128, (code & 63) | 128);
}
}
console.log(rs);
return rs;
},
decode: function(str) {
var rs = '';
for(var i = 0; i < str.length; i++) {
var code = str.charCodeAt(i);
console.log(code);
if((240 & code) == 240) {
var code1 = str.charCodeAt(i + 1),
code2 = str.charCodeAt(i + 2),
code3 = str.charCodeAt(i + 3);
rs += String.fromCodePoint(((code & 7) << 18) | ((code1 & 63) << 12) | ((code2 & 63) << 6) | (code3 & 63));
i += 3;
} else if((224 & code) == 224) {
var code1 = str.charCodeAt(i + 1),
code2 = str.charCodeAt(i + 2);
rs += String.fromCodePoint(((code & 15) << 12) | ((code1 & 63) << 6) | (code2 & 63));
i += 2;
} else if((192 & code) == 192) {
var code1 = str.charCodeAt(i + 1);
rs += String.fromCodePoint(((code & 31) << 6) | (code1 & 63));
i++;
} else if((128 & code) == 0) {
rs += String.fromCharCode(code);
}
}
console.log(rs);
}
};
这里面有很多二进制的或,且,移位操作,我们先来看如何进行utf-8编码:

我们再看看看如何解码:

其实通过也可以通过先用encodeURI或encodeURIComponent进行编码,然后将%十六进制变成十进制,不过那样的话还需要处理一些额外的符号,例如%或者&等,因为encodeURI或encodeURIComponent默认是会给它们编码的。















 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









