





一.整型数int
含义:整型数是不带小数部分的数字。包括自然数、0以及负数。
如:100 0 -5
在Python 3里,只有一种整数类型 ,不分整型和长整型。使用Python的内置函数type可以查看变量所指的数据类型。Python的整数类型与其它语言表示的整数类型不太相同,其它语言整型的取值范围与机器位数有关,例如,在32位机器上,整型的取值范围约是-2^31到2^31,在64位的机器上整型的取值范围约是-2^63到2^63。而Python的整型能表示的数值仅与机器支持的内存大小有关,也就是说Pyhton可以表示很大的数,可以超过机器位数所能表示的数值范围。
1.整型数的字面值的表示方式:
a.十进制表示:
10
200
9999999
9999999999999999999999999999
b.二进制的表示方式:(0b开头,后面跟0和1)
0b111
0b101
0b1111111111
c.八进制的表示方式:(0o开头,后面跟0~7)
0o177 #127
0o11 #9
d.十六进制的表示方式:(0x开头,后面跟0~9,A~F,a~f)
0x11 #17
0xFF #255
0x1234ABCD
2.整型数的构造函数
int(x,base=10) #base代表是几进制,默认是10进制
int(x=0) #用数字或字符串转换为整数,如果不给出参数,则返回0
二.浮点型float
浮点型数就是带有小数点部分的数字
1.表示方式:
a.小数形式:
3.14
3.1
3.0.14.14
b.科学计数法:
#小数+e/E+正负号(正号可省略)+指数
6.18E-1
2.9979e8
2.浮点数的构造函数
float(obj) #用字符串或数字转换为浮点数,如果不给出参数则返回0
三.复数complex
虚数不能单独存在,它们总是和一个值为0.0的实数部分一起构成一个复数.复数分为两部分,实部(real)+虚部(image),虚部以j或J结尾
1.字面值:
1j(2j)1+1J
3-4J(-100+100J)
2.复数的构造函数:
complex(r=0.0, i=0.0) #用数字创建一个复数(实部为r, 虚部为i)
四.布尔类型bool
用来表示真和假两个状态的类型
True表示真(条件满足或成立)
False表示假(条件不满足或不成立)
说明:
True的值是1
False的值是0
1.bool类型的构造函数
bool(x) #用x创建一个布尔值(True/False)
2.bool(x) 返回假值的情况
None #空值
False #布尔假值
0 #整型00.0#浮点0
0j #复数0''#空字符串
() #空元组
[] #空列表
{} #空字典
set() #空集合frozenset() #空固定集合
b'' #空字节串
bytearray(b'') #空字节数组
五.空值 None 对象
说明:
None是一个表示不存在的特殊对象
None和False不同。
None不是0。
None不是空字符串。
None和任何其他的数据类型比较永远返回False。
None有自己的数据类型NoneType。
你可以将None赋值给任何变量,也可以将任何变量赋值给一个None值得对象,但是你不能创建其他NoneType对象。
作用:
用来占位
用来给变量解除绑定
六.字符串str
作用:
用来记录文本(文字)信息
说明:
在非注释中,凡是用引号括起来的部分都是字符串
引号的种类
' 单引号
" 双引号
''' 三单引号
""" 三双引号
1.字符串的表示方法:
a.空字符串的字面值表示方式
''
""
''''''
""""""
b.非空字符串的字面值表示方式
'hello world'
"hello world"
'''hello world'''
"""hello world"""
单引号和双引号的区别:
单引号内的双引号不算结束符
双引号内的单引号不算结束符
三引号字符串的作用:
三引号字符串的换行会自动转换为换行符'\n'
三引号内可以包含单引号和双引号
三引号字符串的使用:
#单引号
'welcome to beijing\nwelcome to beijing\nI am studing!'
#双引号
"welcome to beijing\nwelcome to beijing\nI am studing!"
#三引号
s='''welcome to beijing
welcome to beijing!
I am studing!'''
2.用转义序列代表特殊字符
字符串字面值中,用字符反斜杠(\) 后跟一些字符代表一个字符
字符串中的转义字符表
raw 字符串(原始字符串)
作用:
让转义字符无效
字面值格式:
r'字符串内容'r"字符串内容"r'''字符串内容'''r"""字符串内容"""
实例:
a='C:\newfile\test.py'
print(a)print(len(a)) #得到字符串的长度
a=r'C:\newfile\test.py'
print(a)print(len(a)) #得到字符串的长度
3.字符串的运算:
a.算术运算符:
+ += * *=
实例:
+ 加号运算符用于字符串的拼接
x = 'abcd' + 'efg'
print(x) #abcdefg
x += '123'
print(x) #abcdefg123
* 运算符用于生成重复的字符串
x = '123'y= x * 2 #y = '123123'
x *= 3 #x = '123123123'
x = 3x*= '123' #x = '123123123'
b.字符串的比较运算
运算符:
> >= < <= == !=
示例:
'A' < 'B' #True
'B' < 'a' #True
'ABC' > 'AB' #True
'AD' < 'ABC' #False
'ABC' == 'abc' #False
c.in / not in 运算符
作用:
in 用于序列,字典,集合中,用于判断某个值是否存在于容器中,如果存在则返回True, 否则返回False
格式:
对象 in 容器
示例:
s = 'welcome to tarena!'
'to' in s #True
'weimingze' in s #False
4.索引index
python 字符串str是不可以改变的字符序列。
索引语法:
字符串[整数表达式]
说明:
python 序列都可以用索引(index) 来访问序列中的对象(元素)
python 序列的正向索引是从0开始的,第二个索引为1,最后一个索引为len(s) -1
python 序列的反向索引是从-1开始的,-1代表最后一个,-2代表倒数第二个,第一个是-len(s)
示例:
s = 'ABCDE'
print(s[0]) #A
print(s[1]) #B
print(s[4]) #E
5.切片 slice
作用:
从字符串序列中取出一部分相应的元素重新组成一个字符串
语法:
字符串[(开始索引b):(结束索引e)(:(步长s))]注: () 内括起的部分代表可以省略
说明:
开始索引是切片开始切下的位置0代表第一个元素,-1代表最后一个元素
结束索引是切片的终止索引(但不包含终止索引)
步长是切片每次获取完当前索引后移动的方向和偏移量
关于步长的说明:
没有步长,相当于取值完成后向后移动一个索引的位置(默认为1)
当步长为正整数时,取正向切片:
步长默认值为1, 开始索引默认值为0, 结束索引的默认值为len(s)
当步长为负整数时,取反向切片:
反向切片时,默认的起始位置为最后一个元素,默认终止位置为第一个元素的前一个位置
示例:
s = 'ABCDE'a= s[1:4] #a -> 'BCD'
a = s[1:] #a -> 'BCDE'
a = s[:2] #a -> 'AB'
a = s[:] #a -> 'ABCDE'
a = s[4:2] #a -> ''
a = s[2:10000] #a -> 'CDE' 开始索引/结束索引可以越界
a = s[::2] #a -> 'ACE'
a = s[1::2] #a -> 'BD'
a = s[::-1] #a -> 'EDCBA'
a = s[::-2] #a -> 'ECA'
a = s[4:0:-2] #a -> 'EC'
6.常用字符串方法
空白字符
是指空格,水平制表符(\t),换行符(\n)等不可见的字符
字符串文本解析方法
#将字符串使用sep作为分隔符分割s字符串,返回分割后的字符串的列表,#当不给定参数时,用空白字符作为分隔符进行分割
s.split(sep=None)#连接可迭代对象中的字符串,返回一个中间用s分割的字符串
s.join(iterable)
示例:
s = 'Beijing is capital'L= s.split(' ') #L = ['Beijing', 'is', 'capital']
s = '\\'L= ['C:', 'Programe files', 'python3']
s2= s.join(L) #s2 = b'C:\Programe files\python3'
7.字符串的几个函数:
a.字符串的构造函数
str(obj='') #将对象转换为字符串
示例:
s = 123
print(str(s) + '456') #123456
b.字符串编码转换函数
ord(c) #返回一个字符串的Unicode编码值
chr(i) #返回i这个值所对应的字符
示例:
print(ord('A')) #65
print(ord('中')) #
c.整数转换为字符串函数
hex(i) #将整数转换为十六进制的字符串
oct(i) #将整数转换为八进制字符串
bin(i) #将整数转换为二进制字符串
8.字符串格式化表达式
运算符:
%
作用:
生成想要的格式的字符串
语法:
格式字符串 % 参数值
格式字符串 % (参数值1,参数值2,...)
格式字符串中的%为占位符,占位符的位置将用参数值替换
格式化字符串中的占位符和类型码:
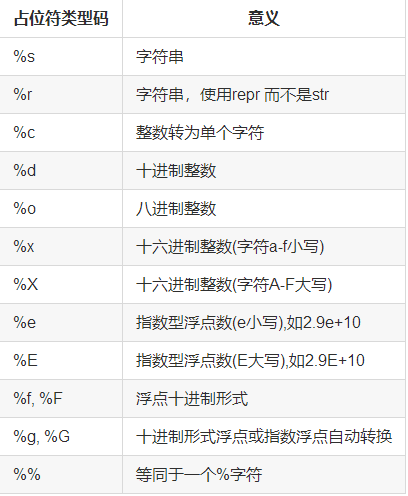
占位符和类型码之间的格式语法:
% [格式语法] 类型码
格式语法:
-左对齐
+显示正号
0补零
宽度(整数)
宽度.精度(整数)
示例:
'%10d' % 123 #' 123'
'%-10d' % 123 #'123 '
'%10s' % 'abc' #' abc'
'%-5s' % 'abc' #'abc '
'%-5d' % 123 #'00123'
'%7.3f' % 3.1415926 #'003.142'
七.列表list:
说明:
列表是由一系列特定元素组成的,元素和元素之间没有任何关联关系,但是他们之间有先后顺序
列表是一种容器
列表是序列的一种
列表是可以被改变的序列
python中的序列类型简介(sequence)
1.字符串str
2.列表list
3.元组tuple
4.字节串bytes
5.字节数组bytearray
1.列表的表达方式:
a.创建空列表的字面值:
L=[] #L绑定空列表
b.创建非空列表:
L=[1,2,3,4]
L=["北京","上海","天津"]
L=[1,'two',3,'四']
L=[1,2,[3.1,3.2,3.3],4]
2.列表的构造(创建)函数list
#生成一个空的列表,等同于[]
list()#用可迭代对象创建一个列表
list(iterable)
实例:
L=list() #L为空的列表,等同于[]
L=list("ABCD") #L->['A','B','C','D']
L = list(range(1, 10, 2))
3.列表的运算:
a.算术运算
+ += * *=
+ 用于拼接列表
x = [1,2,3]
y= [4,5,6]
z= x + y #z = [1,2,3,4,5,6]
+=用于原列表与左侧可迭代对象进行拼接,生成新的列表
x = [1,2,3]
x+= [4,5,6] #x = [1,2,3,4,5,6]
x = [1,2,3]
x+= 'ABC' #+= 右侧必须是可迭代对象
* 生成重复的列表
x = [1,2,3] * 2 #x = [1,2,3,1,2,3]
*= 用于生成重复的列表,同时用变量绑定新列表
x = [1, 2]
x*= 3 #x = [1,2,1,2,1,2]
b.列表的比较运算:
运算符:
< <= > >= == !=
示例:
x = [1,2,3]
y= [2,3,4]
x!= y #True
x > [1,2] #True
x < y #True
[1,3,2] > [1,2,3] #True
['AB', 'CD'] > ['AC', 'BD'] #False
[1, 'two'] > ['two', 1] #TypeError
c.列表的 in / not in
说明:
判断一个数据元素是否存在于容器(列表)内,如果存在返回True, 否则返回False
not in 的返回值与 in运算符相反
示例:
x = [1, 'Two', 3.14, '四']1 in x #True
2 in x #False
3 not in x #True
'四' not in x #False
5.列表的索引 index
列表的索引语法:
列表[整数表达式]
用法:
列表的索引取值与字符串的索引取值规则完全相同
列表的索引为分正向索引和反向索引
示例:
L = ['A', 2, 'B', 3]print(L[1]) #2
x = L[2] #x = 'B'
列表的索引赋值:
列表是可变的序列,可以通过索引赋值改变列表中的元素
语法:
列表[索引] = 表达式
示例:
x = [1,2,3,4]
x[2] = 3.14 #改变了第三个元素的值
6.列表的切片
语法:
列表[:]
列表的[::]
列表的切片取值返回一个列表,规则等同于字符串的切片规则
示例:
x = list(range(9))
y= x[1:9:2] #y = [1,3,5,7]
列表的切片赋值语法:
列表[切片] = 可迭代对象
说明:
切片赋值的赋值运算符的右侧必须是一个可迭代对象
示例:
L = [2,3,4]
L[0:1] = [1.1, 2.2]print(L) #[1.1, 2.2, 3, 4]
L = [2,3,4]
L[:]= [7,8]
L= [2,3,4]
L[1:2] = [3.1, 3.2, 3.3] #[2,3.1, 3.2, 3.3,4]
L = [2,3,4]
L[1:1] = [2.1, 2.2] #[2, 2.1, 2.2, 3, 4]
L = [2,3,4]
L[0:0]= [0, 1] #L=[0, 1, 2,3,4]
L = [2,3,4]
L[3:3] = [5,6] #L=[2,3,4, 5,6]
L = [2,3,4]
L[1:2] = []
切片步长不为1的切片赋值:
L = list(range(1, 9))
L[1::2] = [2.2, 4.4, 6.6, 8.8]print(L) #[1, 2.2, 3, 4.4, 5, 6.6, 7, 8.8]
切片注意事项:
对于步长不等于1的切片赋值,赋值运算符的右侧的可迭代对象提供元素的个数一定要等于切片切出的段数
如:
L = [1,2,3,4,5,6]
L[::2] = 'ABCD' #错的
L[::2] = 'ABC' #对的
7.del 语句用于删除列表元素
语法:
del 列表[索引]
del 列表[切片]
示例:
L = [1,2,3,4,5,6]del L[0] #L = [2,3,4,5,6]
del L[-1] #L = [2,3,4,5]
L = [1,2,3,4,5,6]del L[::2] #L = [2, 4, 6]
8.常用的列表方法
八.元组 tuple
说明:
元组是不可改变的序列,同list一样,元组可以存放任意类型的元素,一但元组生成,则它不可以改变
元组的表示方式:用小括号()括起来,单个元素括起来用逗号(,)区分是单个对象还是元组
1.元组的表示方式
a.创建空元组的字符值
t = ()
b.创建非空元组的字面值
t = 200,
t= (20,)
t= (1,2,3)
t= 100, 200, 300
c.元组的错误示例:
t = (20) #t 绑定整数
x, y, z = 100, 200, 300 #序列赋值
x, y, z = 'ABC'x, y, z= [10, 20, 30]
2.元组的构造函数 tuple
#生成一个空的元组,等同于()
tuple()#用可迭代对象生成一个元组
tuple(iterable)
示例:
t =tuple()
t= tuple(range(10))
t= tuple('hello')
t= tuple([1,2,3,4])
3.元组的算术运算:
a.算术运算:
+ += * *=
用法与列表的用法完全相同
b.元组的比较运算:
< <= > >= == !=
规则与列表完全相同
c.in/ not in
规则与列表完全相同
4.索引取值
规则与列表完全相同
区别:
元组是不可变对象,不支持索引赋值和切片赋值
5.切片取值
规则与列表完全相同
区别:
元组是不可变对象,不支持索引赋值和切片赋值
6.元组的方法:
#用于获取元组中v所在的索引位置
T.index(v[,begin[,end]])#用于获取元组中v的个数
T.count(v)#以上方法同list中的index,count方法
示例:
for x in reversed("ABCD"):print(x) #D C B A
L = [8, 6, 3, 5, 7]
L2=sorted(L)print(L2) #[3, 5, 6, 7, 8]
L3 = sorted(L, reversed=True)print(L3) #[8, 7, 6, 5, 3]
print(L) #保持不变
九.字典 dict
说明:
字典是一种可变的容器,可以存储任意类型的数据
字典中的每个数据都是用'键'(key) 进行索引,而不像序列可以用下标来进行索引
字典的数据没有先后顺序关系,字典的存储是无序的
字典中的数据以键(key)-值(value)对进行映射存储
字典的键不能重复,且只能用不可变类型作为字典的键。
1.字典的字面值表示方式:
用 {} 括起来,以冒号(:) 分隔键-值对, 各键值对用分号分隔开
a.创建空字典
d = {}
b.创建非空的字典:
d = {'name': 'tarena', 'age': 15}
d= {'姓名': '小张'}
d= {1:'壹', 2:'贰'}
2.字典的构造函数 dict
dict() #创建一个空字典,等同于 {}
dict(iterable) #用可迭代对象初始化一个字典
dict(**kwargs) #关键字传参形式生成一个字典
示例:
d =dict()
d= dict([('name', 'tarena'), ('age',15)])
d= dict(name='tarena', age=15)
3.字典的键索引
用[] 运算符可以获取字典内'键'所对应的'值'
语法:
字典[键]
a.获取数据元素:
d = dict(name='tarena', age=15)print(d['age']) #15
b.添加/修改字典元素
字典[键] = 表达式
示例:
d ={}
d['name'] = 'tarena' #创建一个新的键值对
d['age'] = 15 #创建键值对
d['age'] = 16 #修改键值对
4.del 语句删除字典的元素
语法:
del 字典[键]
示例:
d = {'name': 'china', 'pos': 'asia'}del d['pos']print(d)del d['name']print(d) #{}
5.字典的 in / not in 运算符
可以用 in 运算符来判断一个'键'是否存在于字典中,如果存在则返回True, 否则返回False
not in 与 in 返回值相反
示例:
d = {'a': 1, 'b': 2}'a' in d #True
1 in d #False
100 not in d #True
2 not in d #True
6.字典的迭代访问:
字典是可迭代对象,字典只能对键进行迭代访问
d = {'name': 'tarena', (2002, 1, 1): '生日'}for x ind:print(x)
7.字典的方法
十.集合 set
说明:
集合是可变的容器
集合内的数据对象是唯一的(不能重复多次的)
集合是无序的存储结构,集合中的数据没有先后关系
集合内的元素必须是不可变对象
集合是可迭代的
集合是相当于只有键没有值的字典(键则是集合的数据)
1.集合的表达方式:
a.创建空的集合
s = set() #set() 创建一个空的集合
b.创建非空集合
s = {1, 2, 3} #集合中的三个整数1,2,3
2.集合的构造函数 set
set() #创建空集合
set(iterable) #用可迭代对象创建一个新的集合对象
示例:
s = set("ABC")
s= set('ABCCBA')
s= set({1:"一", 2:'二', 5:'五'})
s= set([1, 3.14, False])
s= set((2,3,5,7))#s = set([1, 2, [3.1, 3.2], 4]) # 错的[3.1, 3.2]是可变对象
3.集合的运算:
a.& 生成两个集合的交集
s1 = {1,2,3}
s2= {2,3,4}
s3= s1 & s2 #s3 = {2, 3}
b.| 生成两个集合的并集
s1 = {1,2,3}
s2= {2,3,4}
s3= s1 | s2 #s3 = {1,2,3,4}
c.- 生成两个集合的补集
s1 = {1,2,3}
s2= {2,3,4}#生成属于s1,但不属于s2的所有元素的集合
s3 = s1 - s2
d.^ 生成两个集合的对称补集
s1 = {1,2,3}
s2= {2,3,4}
s3= s1 ^ s2 #s3 = {1, 4}
#等同于 s3 = (s1 - s2) | (s2 -s1)
e.< 判断一个集合是另一个集合的子集
f.> 判断一个集合是另一个集合的超集
s1 = {1, 2, 3}
s2= {2, 3}
s2< s1 #True 判断子集
s1 > s2 #True 判断超集
g.== != 集合相同/不同
s1 = {1, 2, 3}
s2= {2, 3, 1}
s1== s2 #True
s1 != s2 #False # 集合的数据没有先后关系
h.in / not in 运算符
说明:
等同于字典,in 运算符用于集合中,当某个值存在于集合中,则为真,否则为假
not in 与 in 返回值相反
示例:
s = {1, 'Two', 3.14}1 in s #True
2 in s #False
3.14 not in s #False
4 not in s #True
4.集合的方法:
十一.固定集合 frozenset
说明:
固定集合是不可变的,无序的,含有唯一元素的集合
作用:
固定集合可以作为字典的键,也可以作为集合的值(元素)
1.固定集合的表达方式
a.创建空的固定集合
fs = frozenset()
b.创建非空的固定集合
fs = frozenset([2,3,5,7])
2.构造函数:
frozenset()
frozenset(可迭代对象)#同set函数一致,返回固定集合
3.固定集合的运算:
运算规则等同于set中的用法
4.固定集合的方法:
相当于集合的全部方法去掉修改集合的方法
十二.字节串 bytes
作用:
存储以字节为单位的数据
说明:
字节串是不可变的字节序列
字节是0~255之间的整数
1.字节串的表达方式
a.创建空字节串的字面值
b''b""b''''''b""""""B''B""B''''''B""""""
b.创建非空字节串的字面值:
b'ABCD'b'\x41\x42'b'hello tarena'
2.字节串的构造函数 bytes
bytes() #生成一个空的字节串 等同于 b''bytes(整型可迭代对象) #用可迭代对象初始化一个字节串
bytes(整数n) #生成n个值为零的字节串
bytes(字符串, encoding='utf-8') #用字符串的转换编码生成一个字节串
3.字节串的运算
运算规则等同于str中的用法
示例:
b = b'abc' + b'123' #b=b'abc123'
b += b'ABC' #b=b'abc123ABC'
b'ABD' > b'ABC' #True
b = b'ABCD'
65 in b #True
b'A' in b #True
4.bytes 与 str的区别:
bytes 存储字节(0-255)
str 存储Unicode字符(0-65535)
bytes 与 str 转换
a.编码(encode)
str ------> bytes
b = s.encode('utf-8')
b.解码(decode)
bytes ------> str
s = b.decode('utf-8')
十三.字节数组 bytearray
可变的字节序列
1.创建字节数组的构造函数:
bytearray() 创建空的字节数组
bytearray(整数)
bytearray(整型可迭代对象)
bytearray(字符串,encoding='utf-8')#以上参数等同于字节串
2.字节数组的运算:
字节数组支持索引和切片赋值,规则与列表相同
3.bytearray的方法:
B.clear() #清空字节数组
B.append(n) #追加一个字节(n为0-255的整数)
B.remove(value) #删除第一个出现的字节,如果没有出现,则产生ValueError错误
B.reverse() #字节的顺序进行反转
B.decode(encoding='utf-8') #解码
B.find(sub[, start[, end]]) #查找















 668
668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









