






关注我,获取更多分享。

MySQL中经常会遇到重复的数据,那么当我们遇到重复的时候的时候,如果定位哪些数据是有重复的记录?如何删除重复的数据?我们该怎么做呢?接下来我们一步步来分析一下遇到这样的情况后,该如何处理。
初始化实验环境
我们创建一个简单的表user_info,然后基于这个表进行分析重复数据的处理情况。其中的id为自增主键,name、sex、age三个列是我们判断是否为重复数据的key,如果这三列的值相同,则认为这行数据为重复数据。
建表语句如下:CREATETABLE`user_info`(`id`int(10)unsignedNOTNULLAUTO_INCREMENT,`name`varchar(255)DEFAULTNULL,`sex`varchar(255)DEFAULTNULL,`age`int(11)DEFAULTNULL,`remark`varchar(255)DEFAULTNULL,PRIMARYKEY(`id`))ENGINE=InnoDBAUTO_INCREMENT=13DEFAULTCHARSET=utf8;
初始化数据如下:INSERTINTO`tmp_test`.`user_info`(`id`,`name`,`sex`,`age`,`remark`)VALUES(1,'A','男',22,'第一个A');INSERTINTO`tmp_test`.`user_info`(`id`,`name`,`sex`,`age`,`remark`)VALUES(2,'B','女',33,'第一个B');INSERTINTO`tmp_test`.`user_info`(`id`,`name`,`sex`,`age`,`remark`)VALUES(3,'C','男',44,'第一个C');INSERTINTO`tmp_test`.`user_info`(`id`,`name`,`sex`,`age`,`remark`)VALUES(4,'D','女',55,'第一个D');INSERTINTO`tmp_test`.`user_info`(`id`,`name`,`sex`,`age`,`remark`)VALUES(5,'A','男',22,'第二个A');INSERTINTO`tmp_test`.`user_info`(`id`,`name`,`sex`,`age`,`remark`)VALUES(6,'B','女',33,'第二个B');INSERTINTO`tmp_test`.`user_info`(`id`,`name`,`sex`,`age`,`remark`)VALUES(7,'C','男',44,'第二个C');INSERTINTO`tmp_test`.`user_info`(`id`,`name`,`sex`,`age`,`remark`)VALUES(8,'D','女',55,'第二个D');INSERTINTO`tmp_test`.`user_info`(`id`,`name`,`sex`,`age`,`remark`)VALUES(9,'E','男',18,'第一个E');INSERTINTO`tmp_test`.`user_info`(`id`,`name`,`sex`,`age`,`remark`)VALUES(10,'A','男',22,'第三个A');INSERTINTO`tmp_test`.`user_info`(`id`,`name`,`sex`,`age`,`remark`)VALUES(11,'B','女',33,'第三个B');INSERTINTO`tmp_test`.`user_info`(`id`,`name`,`sex`,`age`,`remark`)VALUES(12,'F','男',15,'第一个F');
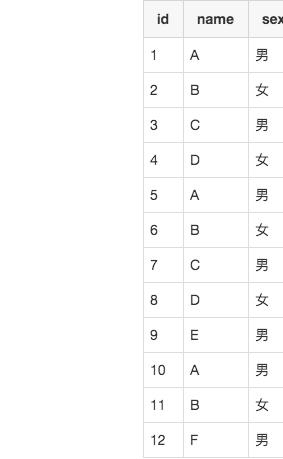
最后表中数据如下:
明确需求
假设我们的要求是保留重复数据中,第一次出现的数据,后面出现的数据不保留。
也就是我们的上面的这个表中每一组重复数据中id最小的一行数据需要保留,其他比较大的id的重复的数据行需要被删除。当然如果是要保留id行最大的一行数据最为最后的数据行也是可以了,只要在查询的时候,稍微修改一下SQL语句的min(id)或max(id)函数即可。
查找重复的数据
基于前面我们初始化的实验数据,首选我们要查询出那些数据是有重复数据的行,通过下面的SQL语句,可以得到结果:其中有重复数据的是name值为A、B、C、D的四种类型的数据。
使用如下SQL可以查询出来那些数据行有重复记录,并统计出重新出现的次数。select name, sex, age,count(*)as countfrom user_info groupby name, sex, age havingcount(*)>1;
重复数据在表中的统计结果如下:

查找要保留的数据
上面我们知道该如何查询哪些数据是重复数据了,那么我们需要保留的数据是哪些?
使用下面的SQL既可以获取到我们要保留的数据行:select*from user_info where id in(selectmin(id)from user_info groupby name, sex, age);
结果如下:
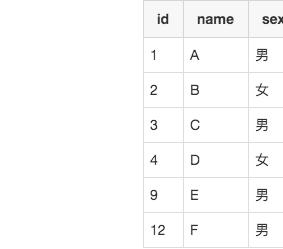
上面的结果就是我们需要最后留下来的数据。这里包含了非重复的时候和每一组重复的数据中id最小的数据行。
删除重复的数据
方法一
这是最笨的一种方式,也是最容易理解的一种方式,效率也比较低。思路如下:
查询出每一组的重复数据的key值,也就是这里的name,sez,age三个字段。SQL语句如下:select name, sex, agefrom user_infogroupby name, sex, agehavingcount(*)>1结果如下:

查询出每一组重复数据中,最小的id值。SQL如下:selectmin(id)from user_info groupby name, sex, agehavingcount(*)>1;结果如下:

把上面的两个查询的结果,作为条件来筛选出每组重复数据中除id最小的行之外的重复数据行,这些行就是需要被删除的行。SQL语句如下:select*from user_info where(name,sex,age)in(select-- 查询重复数据中,name, sex, age的值 name, sex, age from user_info groupby name, sex, age havingcount(*)>1) and id notin(select-- 查询重复数据中,最小的id值min(id)from user_info groupby name, sex, age havingcount(*)>1);结果如下:
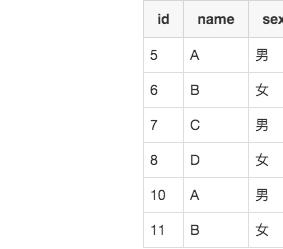
从上面的过程中,我们一步一步定位到了我们需要删除的数据是哪些。定位到这些数据之后,删除的时候,只要把查询语句改为删除语句即可。所以最后通过这样的方式来删除我时候,我们的删除语句如下:
deletefrom user_infowhere(name,sex,age)in(select x.*from(-- 删除的时候,这里要在包裹一层子查询select-- 查询重复数据中, name, sex, age的值name, sex, agefrom user_infogroupby name, sex, age havingcount(*)>1)as x)and id notin(select min_id from(-- 删除的时候,这里要在包裹一层子查询select-- 查询重复数据中,最小的id值min(id)as min_idfrom user_info groupby name, sex, age havingcount(*)>1)as y);
注意:上面的删除语句中,我们在两个where条件中的子查询语句外面又包裹了一层子查询,即为上面SQL语句中的as x和as y两个查询语句,之所以包裹一层的原因是在程序如下的错误提示:
1093- You can't specify target table 'user_info' forupdateinFROM clause,Time: 0.084000s
上述错误的原因是:修改一个表的时候子查询不能是这被修改的这个表,所以,我们的解决办法是,在子查询外面再套一层查询语句就可以了。
方法二
上面方法一的思路是想办法找到我们要删除的数据是哪些,然后我们在删除的时候,使用where条件去匹配这些查询出来要删除的数据行,以此来达到删除重复数据的目的。
此时,我们不防换一个角度思考:我们不要去关注哪些是我们需要删除的重复数据,相反,我们去关注哪些是我们需要留下来的数据。然后我们可以在删除的时候,使用取反的方式not in我们需要保留下来的数据,那不是就我们需要删除的数据吗?
所以,我们想一想哪些使我们需要留下来的数据呢?每一组数据中,id值最小的哪一行就是我们要保留的数据行。其余的我们就不关心了。那么怎么样才能取到这样的数据行呢?
使用下面的SQL语句可以获取我们需要保留的数据行的所有的id的值:selectmin(id)from user_info groupby name, sex, age;
结果如下:

既然我们想要保留的数据行的id集合得到了,在我们要删除数据的where条件中,使用not in我们要保留的id集合,不就是需要删除的数据吗?
删除重复数据的语句如下:deletefrom user_info where id notin(select min_id from(selectmin(id)as min_id from user_info groupby name, sex, age)as x);
注意:这里为了避免MySQL的1903错误,我们也在where条件的子查询中包裹了另外一个子查询,即上面SQL中as x查询语句。
方法三
通过两个表关联的方式来删除数据,这个方式效率比较高,推荐使用这种方式。自己和自己关联,关联的条件就是我们判断数据是否为重复数据的key。除此之外,最重要的一个条件是:两个表的id关联条件,这个是删除保留数据的关键条件。
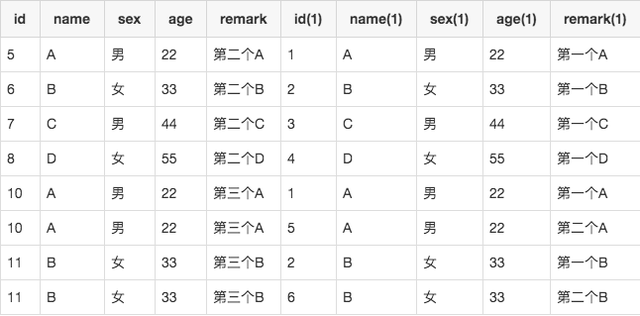
查询重复数据的SQL语句如下:select a.*,b.*from user_info as a innerjoin user_info as b on a.name = b.name and a.sex = b.sex and a.age = b.ageand a.id > b.id;
结果如下:
写法1
删除重复数据SQL语句如下:
delete a.* from user_info as ainnerjoin user_info as bon a.name = b.nameand a.sex = b.sexand a.age = b.ageand a.id > b.id;
写法2
除了上面的那种写法之外,还有另外一种写法,如下:
查询待删除的重复数据SQL如下:
select*from user_info as a where a.id <>(selectmin(b.id)from user_info as bwhere a.name = b.nameand a.sex = b.sexand a.age = b.age);
删除重复数据的SQL语句如下:
delete a.*from user_info as awhere a.id <>(selectmin(b.id)from(select*from user_info )as bwhere a.`name`= b.`name`and a.sex = b.sexand a.age = b.age);
总结
以上是对于MySQL中重复数据删除的时候,经常使用的方法。希望能帮助到你。
最后提醒一点:在真正删除之前,记得对原数据备份一下。以便删除错误后,数据不能恢复回来。可以使用如下的语句来创建一个备份表,以便于在删除错误后,把数据恢复到原来的表中取。
createtable user_info_bak asselect*from user_info;--创建一个备份表truncatetable user_info;-- 清空原始表中的数据insertinto user_info select*from user_info_bak;-- 从备份表中把数据插入到原始表中
像上面这样操作,数据如果删除失误的时候,可以从user_info_bak中还原数据到user_info表中。
关注我,获取更多分享。















 4464
4464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









